1.基本思想
符号表中使用的数据结构的一个简单选择是链表,每个结点存储一个键值对,如算法中的代码所示。get()的实现即为遍历链表,用equals()方法比较需被查找的键和每个结点中的键。如果匹配成功我们就返回相应的值,否则我们返回null。put()的实现也是遍历链表,用equals()方法比较需被查找的键和每个结点中的键。如果匹配成功我们就用第二个参数指定的值更新和该键相关联的值,否则我们就用给定的键值对创建一个新的结点并将其插入到链表的开头。这种方法也被称为顺序查找:在查找中我们一个一个地顺序遍历符号表中的所有键并使用equals()方法来寻找与被查找的键匹配的键。
2.具体算法
/**
* 算法3.1 顺序查找(基于无序链表)
* Created by huazhou on 2015/11/11.
*/
public class SequentialSearchST<Key, Value> {
private Node first; //链表首结点
//链表结点的定义
private class Node{
Key key;
Value val;
Node next;
public Node(Key key, Value val, Node next){
this.key = key;
this.val = val;
this.next = next;
}
}
//查找给定的键,返回相关联的值
public Value get(Key key){
for(Node x = first; x != null; x = x.next){
if(key.equals(x.key)){
return x.val; //命中
}
}
return null; //未命中
}
//查找给定的键,找到则更新其值,否则在表中新建结点
public void put(Key key, Value val){
for (Node x = first; x != null; x = x.next){
if(key.equals(x.key)){ //命中,更新
x.val = val;
return;
}
}
first = new Node(key, val, first); //未命中,新建结点
}
}
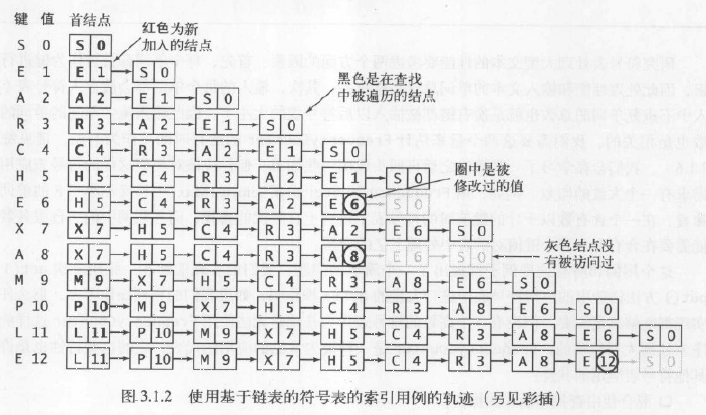
符号表的实现使用了一个私有内部Node类来在链表中保存键和值。get()的实现会顺序地搜索链表查找给定的键(找到则返回相关联的值)。put()的实现也会顺序地搜索链表查找给定的键,如果找到则更新相关联的值,否则它会用给定的键值对创建一个新的结点并将其插入到链表的开头。
3.算法分析
命题:在含有N对键值的基于(无序)链表的符号表中,未命中的查找和插入操作都需要N次比较。命中的查找在最坏情况下需要N次比较。特别地,向一个空表中插入N个不同的键需要~N2/2次比较。
证明:在表中查找一个不存在的键时,我们会将表中的每个键和给定的键比较。因为不允许出现重复的键,每次插入操作之前我们都需要这样查找一遍。
推论:向一个空表中插入N个不同的键需要~N2/2次比较。∑Ni=1(i)=1+2+...+N=N(N+1)/2~N2/2次比较
4.总结
查找一个已经存在的键并不需要线性级别的时间。一种度量方法是查找表中的每个键,并将总时间除以N。在查找表中的每个键的可能性都相同的情况下时,这个结果就是一次查找平均所需的比较数。我们将它称为随机命中。尽管符号表用例的查找模式不太可能是随机的,这个模型也总能适应得很好。我们很容易就可以得到随机命中所需的平均比较次数为~N/2:算法中的get()方法查找第一个键需要1次比较,查找第二个键需要2次比较,如此这般,平均比较次数为(1+2+...+N)/N=(N+1)/2~N/2。
这些分析完全证明了基于链表的实现以及顺序查找是非常低效的。

【源码下载】