题目一:
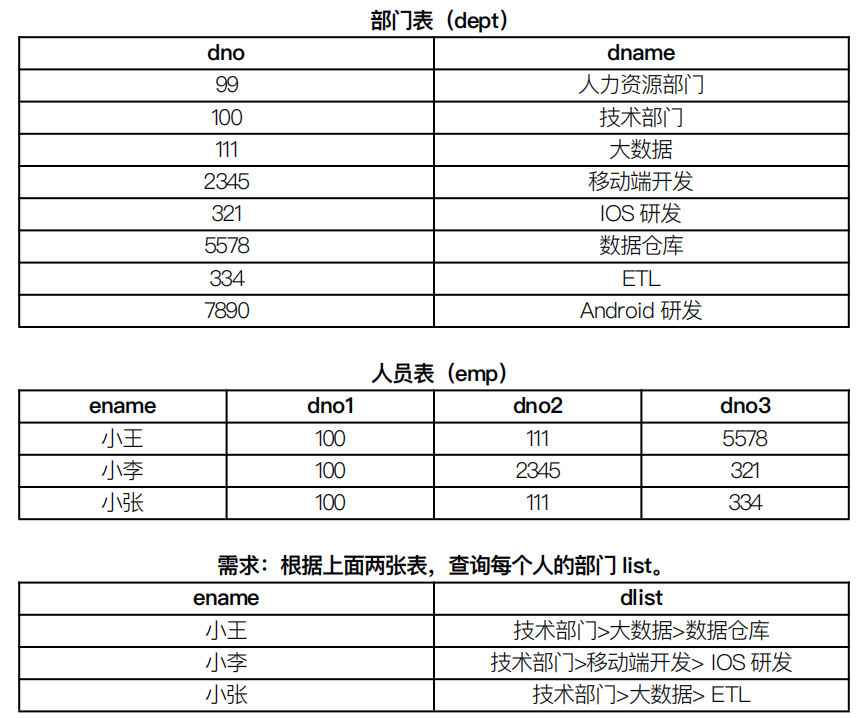
# 建表语句,注意!注意!注意!本题测试环境为Hive3.1.0 -- 部门表(dept) dno dname create table dept( dno int, dname string ) row format delimited fields terminated by ',' lines terminated by ' ' stored as textfile; -- 人员表(emp) ename dno1 dno2 dno3 create table emp( ename string, dno1 int, dno2 int, dno3 int ) row format delimited fields terminated by ',' lines terminated by ' ' stored as textfile;
数据文件:
# dept表
99,人力资源部
100,技术部门
111,大数据
2345,移动端开发
321,IOS开发
5578,数据仓库
334,ETL
7890,Android研发
# emp表
小王,100,111,5578
小李,100,2345,321
小张,100,111,334
加载数据到hive表中,采用本地加载模式
load data local inpath '/opt/module/data/dept.txt' into table default.dept; load data local inpath '/opt/module/data/emp.txt' into table default.emp;
解题思路:
-- 原始表初始化 select e.ename,d.dname from emp e join dept d on e.dno1 = d.dno or e.dno2 = d.dno or e.dno3 = d.dno; -- 失败1:拼接。hive中不能查询非group by的字段 select ename, dname from ( select e.ename,d.dname from emp e join dept d on e.dno1 = d.dno or e.dno2 = d.dno or e.dno3 = d.dno )tmp group by ename; -- 失败2:hive中不能查询非group by的字段 with tmp as ( select e.ename,d.dname from emp e join dept d on e.dno1 = d.dno or e.dno2 = d.dno or e.dno3 = d.dno ) select ename,concat_ws('>', dname) from tmp group by ename; -- 成功,注意,本环境为3.1.0;如果是Hive2.x的版本,不能使用or,需要使用where条件,然后union 起来 with tmp as ( select e.ename, d.dname from emp e join dept d on e.dno1 = d.dno or e.dno2 = d.dno or e.dno3 = d.dno ) select ename, concat_ws('>', collect_set(dname)) from tmp group by ename;