HDFS介绍
产生原因: 单机存储无法存储大量数据,需要跨机器存储,统一管理分布在集群上的文件系统。
概念: HDFS是一个分布式文件系统 , Apache Hadoop项目的一个子项目,Hadoop非常适合存储大型数据。(T级)
应用场景:
-
-
采用流式的数据访问方式 : 一次写入 , 多次读取 , 数据集经常从数据源生成或者拷贝一次 .
-
运行于商业硬件上
-
需要高容错性
-
为数据存储提供所需的扩展能力
-
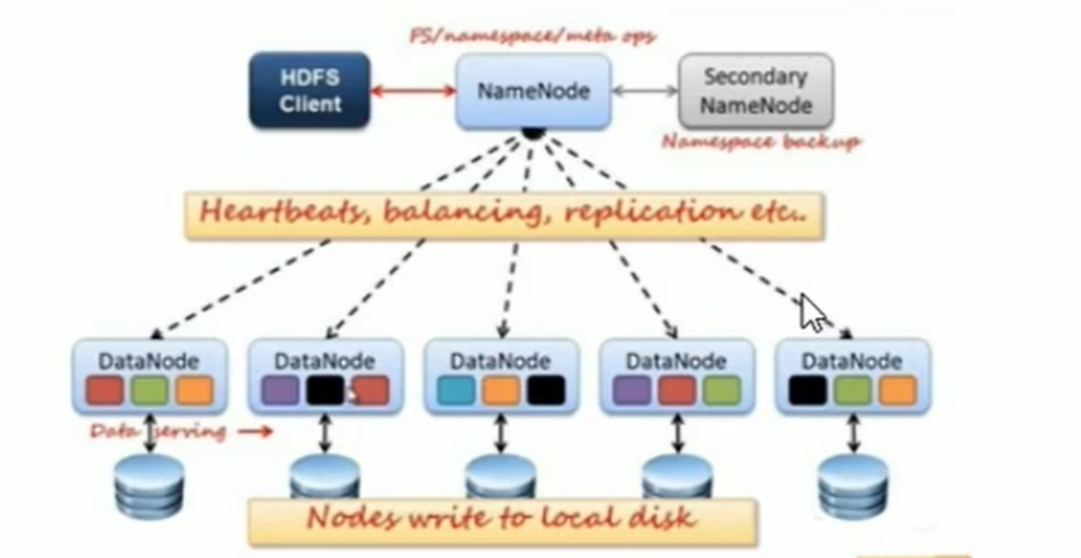
-
-
与NameNode交互, 获取文件的位置信息
-
与DataNode交互, 读取或者写入数据
-
-NameNode: 就是master , 它是一个主管, 管理者
-
-
管理数据库映射信息
-
配置副本策略
-
-Datanode: 就是Slave , NameNode下达命令, DataNode执行具体操作
-
-
- 心跳机制,反馈给namenode ( 心跳信息 , 数据块信息 , 存数据块信息 )
-SecondaryNameNode : 并非NameNode热备, 当NameNode挂掉时,它并不能马上替换NameNode并提供服务
副本机制:
-
-
使用块作为文件存储的逻辑单位可以简化存储子系统
-
<!--在Hadoop1当中,文件的block默认64M,Hadoop2中,默认128M,block块的大小在 hdfs-site.xml当中设定--> <property> <name>dfs.block.size</name> <value>块大小 以字节为单位</value> </property>
HDFS的命令行操作:
start-all.sh #启动所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager stop-all.sh #停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager #格式: hdfs dfs -ls URI #作用: 类似于Linux的ls 命令,显示文件列表 hdfs dfs -ls / #格式 : hdfs dfs -lsr URI #作用 : 在整个目录下递归执行ls,与UNIX的 ls -R类似 # hdfs dfs -lsr / 过时了 hdfs dfs -ls -R / #格式 : hdfs dfs [-p] -mkdir <paths> #作用 : 以<paths>中的URI作为参数,创建目录,使用-p参数可以递归创建目录 #格式 : hdfs dfs -put <localsrc> ... <dst> #作用 : 将单个源文件src或者多个源文件srcs从本地文件系统拷贝到目标文件系统中(<dst> 对应的路径)也可以从标准输入中读取输入,写入目标文件系统中 hdfs dfs -put /root/a.txt /dir1 #格式 : hdfs dfs -moveFromLocal <localsrc> <dst> #作用 : 和put命令类似,但是源文件localsrc拷贝之后自身被删除 hdfs dfs -moveFromLocal /root/a.txt / #格式 hdfs dfs -get [-ignorecrc ] [-crc] <src> <localdst> #作用:将文件拷贝到本地系统. CRC校验失败的文件通过-ignorecrc选项拷贝. 文件和CRC校验和可以通过-CRC选项拷贝 hdfs dfs -get /install.ini /export/servers #格式 : hdfs dfs -mv URI <dest> #作用 : 将hdfs上的文件从原路径移动到目标路径(移动文件后删除),该命令不能夸文件系统 hdfs dfs -mv /dir1/a.txt /dir2 #格式 : hdfs dfs -rm [-r] [-skipTrash] URI [URI...] #作用 : 删除参数指定的文件,参数可以有多个.此命令只删除文件和非空目录 # -r 参数指定删除文件类型 #如果指定-skipTrash选项,那么在回收站可用的情况下,该选项直接跳过回收站直接删除文件; #否则,在回收站可用时,在HDFS Shell 中执行此命令,会将文件暂时放到回收站中 hdfs dfs -rm -r /dir1 #格式 : hdfs dfs -cp URI [URI ...] <dest> #作用 : 将文件拷贝到目标文件中,如果<dest>为目录的话,可以将多个文件夹拷贝到该目录下 -f #选项将覆盖目标,如果它已经存在 -p #选项将保留文件属性(时间戳、所有权、许可、ACL、XAttr) hdfs dfs -cp /dir1/a.txt /dir2/b.txt hdfs dfs -cat URI[uri ...] #作用 : 将参数所指示的文件内容输出到stdout hdfs dfs -cat /install.log #格式 hdfs dfs -chmod [-R] URI[URI ...] #作用 改变文件的权限,使用这一命令的用户必须是文件的所属用户,或者超级用户 #如果使用-R选项,则对整个目录有效递归执行。 hdfs dfs -chmod -R 777 /install.log #格式 hdfs dfs -chmod [-R] URI[uri ...] #作用 改变文件的所属用户和用户组,使用这一命令的用户必须是文件的所属用户,或者超级用户 # 如果使用 -R 选项,则对整个目录有效递归执行 hdfs dfs -chown -R hadoop:hadoop /install.log #格式: hdfs dfs -appendToFile <localsrc>...<dst> #作用: 追加一个或者多个文件到hdfs文件中,也可以从命令行中读取输入 #方便 小文件的合并,减少元数据过多的压力 hdfs dfs -appendToFile a.xml b.xml /big.xml # 查看配额信息 hdfs dfs -count -q -h /user/root/dir1 #创建hdfs文件夹 hdfs dfs -mkdir -p /user/root/dir #给文件夹下面设置最多上传两个文件,发现只能上传一个文件,n个目录 只能上传n-1个,因为该目录本身也是一个文件 hdfs dfs -setQuota 2 dir #清除文件数量限制 hdfs dfsadmin -clrQuota /user/root/dir #在设置空间配额时,设置的空间大小至少是block_size*3大小 hdfs dfsadmin -setSpaceQuata 4k /user/root/dir #限制大小为4k hdfs dfs -put /root/a.txt /user/root/dir #生成任意大小文件的命令: dd if=/dev/zero of=1.txt bs=1M count=2 #生成2M的文件 #清除空间限额配置 hdfs dfsadmin -clrSpaceQuota /user/root/dir #安全模式操作命令 hdfs dfsadmin -safemode get #查看安全模式状态 hdfs dfsadmin -safemode enter #进入安全模式 hdfs dfsadmin -safemode leave #关闭安全模式 #检查副本率,保证文件系统的安全以及完整性 #写入测试报告,写入一个jar包,一共十个,每个十兆 hadoop jar /export/servers/hadoop-2.7.6/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.6.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB #完成之后查看写入速度结果 hdfs dfs -text /benchmarks/TestDFSIO/io_write/part-00000 #读取测试报告,读取一个jar包,一共十个,每个十兆 hadoop jar /export/servers/hadoop-2.7.6/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.6.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB #清除测试数据 hadoop jar /export/servers/hadoop-2.7.6/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.6.jar TestDFSIO -clean