github地址:https://github.com/Joanna1220/WordCount.git
同伴作业地址:https://www.cnblogs.com/huyu 1998/p/10660407.html
一、PSP表格和结对编程图片
见小伙伴作业,不再重复显示。
二、模块接口的设计与实现过程
1.解题思路:看到作业要求后,就觉得这些功能有些很复杂,根本不知道怎样下手,通过上网搜索和借鉴优秀的博客,逐渐知道在统计单词时用正则表达式分割,并且利用字典储存单词和频数并给单词频数排序。但是在实现扩展功能时出现问题,最终未能实现。
正则表达式的用法:https://www.cnblogs.com/TanSea/p/6924177.html
字典的遍历:https://www.cnblogs.com/gengaixue/p/4002244.html
字典排序:https://www.cnblogs.com/wt-vip/p/5997094.html
2.模块设计:将四个基本统计功能用四个方法实现,最后在Main方法中分别调用四个统计功能,将结果输出到output。
第一个统计字符串:每读取文件的一个字符就字符数加1,直到文本末尾,读取结束。
第二个统计行数:每读取一行就行数加一,判断空白行并跳过空白行(判断空白行有误,未能实现)直到文本末尾。
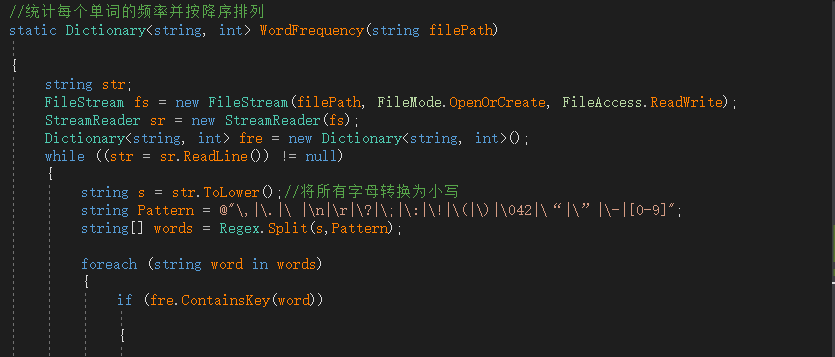
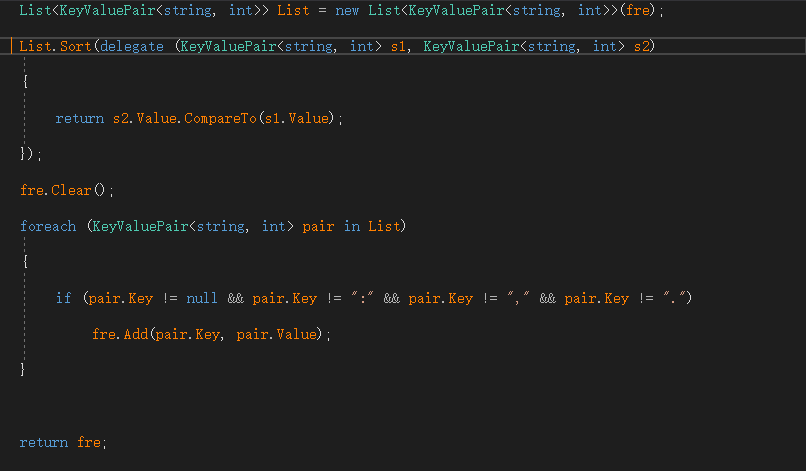
第三个统计单词频率和输出前十个频率最高的单词:先将文本所有字母转化成小写,再用正则表达式将文本拆分成字符串数组,遍历所有字符串,若前四个为字母则为合法单词,统计所有合法单词频数,用字典序进行排序输出前十个频率最高单词。此部分代码如下图:

第四个统计单词总数:调用第三个方法,遍历后输出单词总数。
三、代码复审
我们两人分工为:我主要写代码,小伙伴负责写测试,《构建之法》上面的代码规范很详细,在编写过程我有特意去按照上面的标准,所以代码复审过程并无什么问题。
四、测试
1.因为合法单词必须字母数大于3并且前四个为字母,所以进行以下判断:
写统计单词数测试时,设计数据有数字开头和字母不足四个的单词,如下

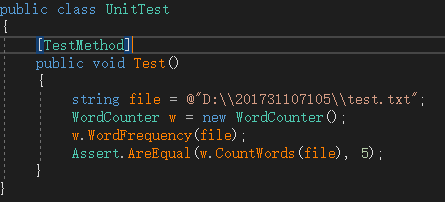 测试通过。
测试通过。
其他部分测试截图:

五、性能分析
刚开始编写的代码中方法很多,调用很麻烦,最后我将有些方法合并,增强了代码的可读性,最开始实现统计单词数时,我是重新创建字典,后来采用引用第三个方法,性能优化不少。
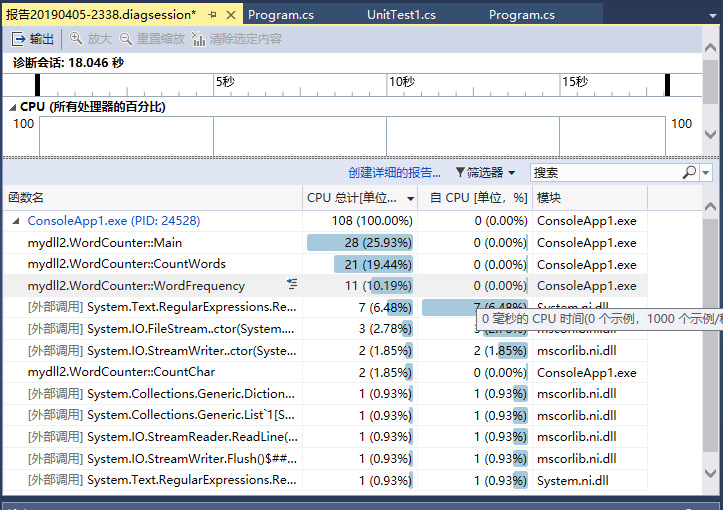
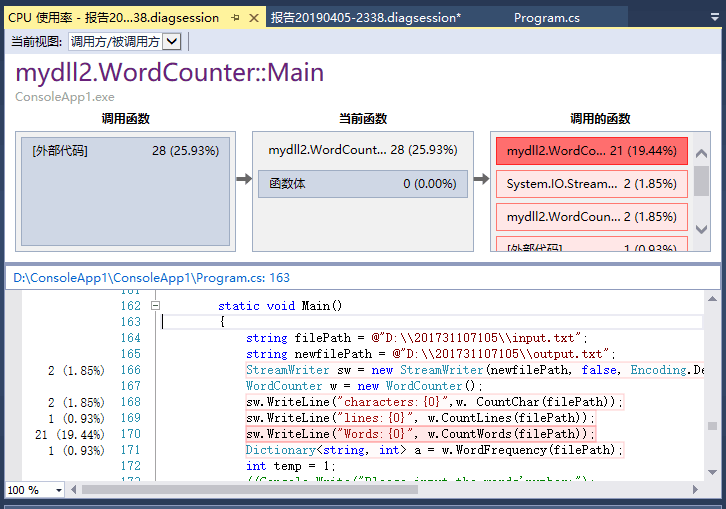
如图可见消耗最大的方法应该是mian方法。
六、收获与感受
首先,每一次作业的完成自己都有所收获,不管收获是小是大,也许在此过程中付出了很多时间和精力,但最后结果也不理想,但至少每一次都有尽力,每一次都在进步。
其次,我觉得结对编程就是相互学习,要吸取对方的优点,找出自己在某些方面的不足,结对编程的好处就是当一人犯一个小错误可能影响全局却没被发现时,另一个人可以马上指出来,防止问题变得更大;并且在自己思路受限或短路时,另一个人可能一句话让你茅塞顿开;一个人与两人或多人合作最大的不同是多了一份责任,因为这次我负责先写代码再交给小伙伴测试,所以必须在规定时间内把代码交给对方,所以就比自己编程多一份责任。
在编写代码时发现很多自己之前没有接触的东西,所以在接下来的学习中需要自己增强学习新知识的能力。