执行步骤:1)准备Map处理的输入数据
2)Mapper处理
3)Shuffle
4)Reduce处理
5)结果输出
三、mapreduce核心概念:
1)split:交由MapReduce作业来处理的数据块,是MapReduce最小的计算单元。
HDFS:blocksize 是HDFS中最小的存储单元 128M
默认情况下:他们两是一一对应的,当然我们也可以手工设置他们之间的关系(不建议)
2)InputFormat:
将我们的输入数据进行分片(split): InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
TextInputFormat: 处理文本格式的数据
3)OutputFormat: 输出
4)Combiner:每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果
5) Partitioner:是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认是对key hash后再以reduce task数量取模
一、MapReduce概述:
1)源于Google的MapReduce论文,论文发表于2004年12月
2)Hadoop MapReduce 是Google MapReduce的克隆版
3)MapReduce的优点:海量数据离线处理,易开发,易运行。
4)MapReduce的缺点:实时流计算
二、MapReduce编程模型 word count 入门例子
word count:统计文件中单词出现的次数
word count mapreduce 计算流程图如下:
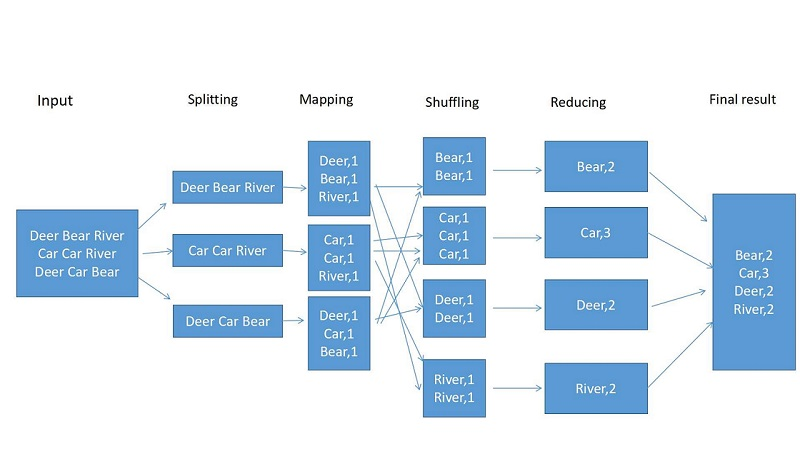
执行步骤:1)准备Map处理的输入数据
2)Mapper处理
3)Shuffle
4)Reduce处理
5)结果输出
三、mapreduce核心概念:
1)split:交由MapReduce作业来处理的数据块,是MapReduce最小的计算单元。
HDFS:blocksize 是HDFS中最小的存储单元 128M
默认情况下:他们两是一一对应的,当然我们也可以手工设置他们之间的关系(不建议)
2)InputFormat:
将我们的输入数据进行分片(split): InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
TextInputFormat: 处理文本格式的数据
3)OutputFormat: 输出
4)Combiner:每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果
5) Partitioner:是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认是对key hash后再以reduce task数量取模