泰坦尼克是一个经典的机器学习数据集,通过决策树对特征进行筛选,获得较大的特征
import pandas as pd
pd.set_option('display.max_columns', None) #显示完整的列
# pd.set_option('display.max_rows', None) #显示完整的行
titanic = pd.read_csv('titanic_train.csv')
# print(titanic.describe())
# 通过descriable 可以发现 Age 存在缺失值,而且Age这个属性比较重要,因此需要填充,通过均值进行填充
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].median())
print(titanic.describe())
# 要把字符的量转化为数值的量
print(titanic['Sex'].unique())
# 把离散的变量转化为数值0-1
titanic.loc[titanic['Sex'] == 'male', 'Sex'] = 0
titanic.loc[titanic['Sex'] == 'female', 'Sex'] = 1
# 均值如何计算
print(titanic['Embarked'].unique())
titanic['Embarked'] = titanic['Embarked'].fillna('S')
titanic.loc[titanic['Embarked'] == 'S', 'Embarked'] = 0
titanic.loc[titanic['Embarked'] == 'C', 'Embarked'] = 1
titanic.loc[titanic['Embarked'] == 'Q', 'Embarked'] = 2
# 构建机器学习模型,来预测
# 最简单的线性回归
from sklearn.linear_model import LinearRegression
# # 交叉验证
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
#
# # 第一步, 提取特征
# predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare','Embarked']
#
# # 建立模型
# alg = LinearRegression()
# kf = KFold(n_splits=3, shuffle=False)
#
# predictions = []
#
# for train, test in kf.split(titanic):
# train_preditors = (titanic[predictors].iloc[train, :])
# train_target = titanic['Survived'].iloc[train]
#
# # 训练模型
# alg.fit(train_preditors, train_target)
#
# # 预测
# test_predictions = alg.predict(titanic[predictors].iloc[test, :])
# predictions.append(test_predictions)
# 预测准确率
# import numpy as np
#
# predictions = np.concatenate(predictions, axis=0)
#
# # Map predictions to outcome
# predictions[predictions > 0.5] = 1
# predictions[predictions <= 0.5] = 0
# accuracy = sum(predictions[predictions == titanic['Survived']]) / len(predictions)
# print(accuracy)
print('-------------------------------')
# 用逻辑回归
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
# # 初始化模型
# alg = LogisticRegression()
#
# # 交叉验证
# scores = cross_val_score(alg, titanic[predictors], titanic['Survived'], cv=3)
# print(scores.mean())
# 下面用随机森林分类器
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare','Embarked']
alg = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)
# 计算
scores = cross_val_score(alg, titanic[predictors], titanic['Survived'], cv=3)
print(scores.mean())
print('---------------------------------')
# 这一步花费的时间是最多的
alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=4, min_samples_leaf=2)
# 计算
scores = cross_val_score(alg, titanic[predictors], titanic['Survived'], cv=3)
print(scores.mean())
# 现在准确率上不去,可以考虑添加新的特征
titanic['FamilySize'] = titanic['SibSp'] + titanic['Parch']
titanic['NameLength'] = titanic['Name'].apply(lambda x:len(x))
import re
# 获取名字的头衔
def get_title(name):
# 使用正则表达式进行筛选,
title_search = re.search(' ([A-Za-z]+).',name)
# 如果头衔存在, 返回
if title_search:
return title_search.group(1)
return ''
titles = titanic['Name'].apply(get_title)
print(pd.value_counts(titles))
# Map each title and print
title_mapping = {'Mr': 1,'Miss':2,'Mrs':3,'Master':4,'Dr':5,
'Rev':6,
'Major':7,
'Mlle' :8,
'Col' :9,
'Ms' :10,
'Countess' :11,
'Mme' :12,
'Lady':13,
'Sir' :14,
'Capt':15,
'Jonkheer':16,
'Don':17 }
for k, v in title_mapping.items():
titles[titles == k] = v
print(pd.value_counts(titles))
titanic['Title'] = titles
# 添加额外的特征,进行测试
import numpy as np
from sklearn.feature_selection import SelectKBest, f_classif
import matplotlib.pyplot as plt
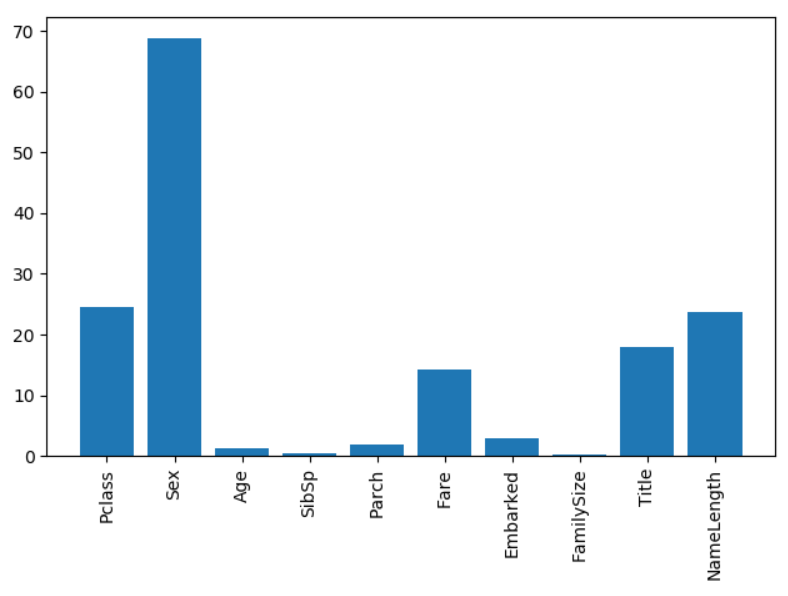
predictors = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare','Embarked', 'FamilySize', 'Title', 'NameLength']
# 进行最好的特征选择
selector = SelectKBest(f_classif, k=5)
selector.fit(titanic[predictors], titanic['Survived'])
# 得到每一个特征的值
scores = -np.log10(selector.pvalues_)
# 画图展示
plt.bar(range(len(predictors)), scores)
plt.xticks(range(len(predictors)), predictors, rotation='vertical')
plt.show()
# 选择最有价值的特征
print('---------------')
predictors = ['Pclass', 'Sex', 'Fare', 'Title']
alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=8, min_samples_leaf=4)
scores = cross_val_score(alg, titanic[predictors], titanic['Survived'], cv=3)
print(scores.mean())
# 使用多个分类器,达到最优的结果
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
# 通过集成两个分类器,达到最优的结果
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), ['Pclass', 'Sex', 'Age', 'Fare','Embarked', 'FamilySize', 'Title']],
[RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=8, min_samples_leaf=4), ['Pclass', 'Sex', 'Fare', 'FamilySize', 'Title', 'Age', 'Embarked']]
]
kf = KFold(n_splits=3, shuffle=False)
predictions = []
for train, test in kf.split(titanic):
train_target = titanic['Survived'].iloc[train]
full_test_predictions = []
# 训练模型
for alg, predictors in algorithms:
alg.fit((titanic[predictors].iloc[train, :]), train_target)
# 预测
test_predictions = alg.predict_proba(titanic[predictors].iloc[test, :].astype(float))[:, 1]
full_test_predictions.append(test_predictions)
# 使用简单的集成模型
test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2
# 对概率进行选择
test_predictions[test_predictions <= 0.5] = 1
test_predictions[test_predictions > 0.5] = 0
predictions.append(test_predictions)
# Put all the predictions together into one array
predictions = np.concatenate(predictions, axis=0)
# 计算准确率
accuracy = sum(predictions[predictions == titanic['Survived']]) / len(predictions)
print('-----------------1')
print(accuracy)