一.递归函数
在函数内部,可以调用其他函数,如果一个函数在内部调用本身,这个函数就是递归函数
1.递归的基本原理:
- 每一次函数调用都会有一次返回.当程序流执行到某一级递归的结尾处时,它会转移到前一级递归继续执行(调用本身函数)
- 递归函数中,位于递归调用前的语句和各级被调函数具有相同的顺序
- 虽然每一级递归有自己的变量,但是函数代码并不会得到复制
- 递归函数中必须包含可以终止递归调用的语句
举例:
>>> def fun2(i): ... r = fun2(i+1) ... return r
递归函数中没有包含终止递归调用的语句,此函数将一直返回循环执行下去,加终止条件当满足条件时会结束函数
def fun(i): print(i) if i == 5: return 5 r = fun(i + 1) return r fun(1)
举例:
阶乘,计算整数n:n!=1*2*3*4*5*..*n
如果用函数fun(n) 可以表示为:
fun(n)=1*2*3*4*5*..*n=fun(n-1)*n
如果用递归函数
>>> def fun(n): ... if n == 1: ... return 1 ... return fun(n-1) * n ... >>> fun(2) 2 >>> fun(10) 3628800
举例:
写函数,利用递归获取斐波那契数列中的第 10 个数,并将该值返回给调用者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
def fun2(depth, a1, a2): if depth == 10: return a1 a3 = a1 + a2 r = fun2(depth + 1, a2, a3) return r ret = fun2(1,0,1) print(ret)
递归小结:
递归的目的是简化程序设计,使程序易读。
但递归增加了系统开销。 时间上, 执行调用与返回的额外工作要占用CPU时间。空间上,随着每递归一次,栈内存就多占用一截。
二.冒泡排序
冒泡排序一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序算法的运作如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
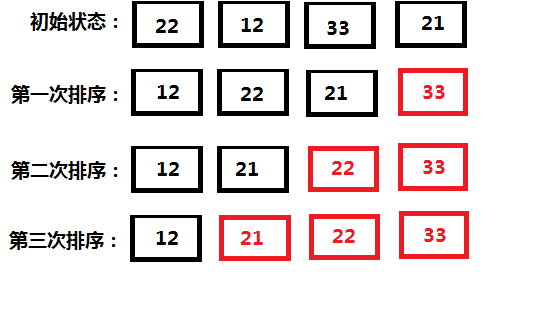
例:
li = [22, 12, 33, 21] for i in range(1,len(li)): for j in range(len(li) - i): if li[j] > li[j + 1]: temp = li[j] li[j] = li[j + 1] li[j + 1] = temp print(li)