MySQL体系架构
学习一门数据库系统首先得了解它的架构,明白它的架构原理对于后期的分析问题和性能调优都有很大的帮助,接下来就通过分析架构图来认识它。
数据库:物理操作系统文件或者其它文件的集合,在mysql中,数据库文件可以是frm、myd、myi、ibd等结尾的文件,当使用NDB存储引擎时候,不是os文件,是存放于内存中的文件。
数据库实例:由数据库后台进程/线程以及一个共享内存区组成,共享内存可以被运行的后台进程/线程所共享。
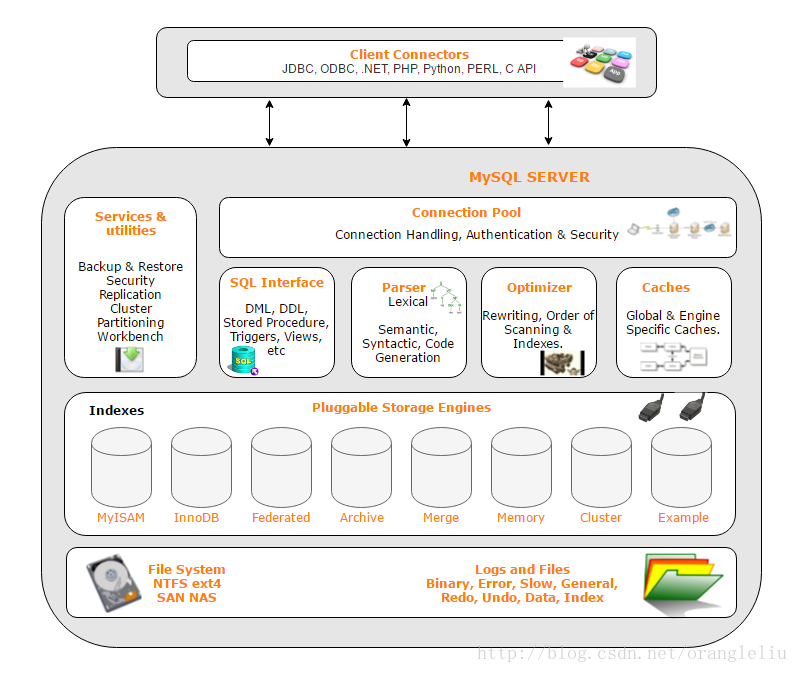
连接者:不同语言的代码程序和mysql的交互(SQL交互)
1、连接池 管理、缓冲用户的连接,线程处理等需要缓存的需求
为解决资源的频繁分配﹑释放所造成的问题,为数据库连接建立一个“缓冲池”,预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
进行身份验证、线程重用,连接限制,检查内存,数据缓存;管理用户的连接,线程处理等需要缓存的需求
2、管理服务和工具组件 系统管理和控制工具
从备份和恢复的安全性、复制、集群、管理、配置、迁移和元数据等方面管理数据库
3、sql接口 接受用户的SQL命令,并且返回用户需要查询的结果
进行DML、DDL,存储过程、视图、触发器等操作和管理;用户SQL命令接口
4、查询解析器 SQL命令传递到解析器的时候会被解析器验证和解析(权限、语法结构)
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本, 主要功能:
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的
b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的
5、查询优化器 SQL语句在查询之前会使用查询优化器对查询进行优化
select id,name from user where age = 40;
a、这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行age过滤
b、这个select查询先根据id和name进行属性投影,而不是将属性全部取出以后再进行过滤
c、将这两个查询条件联接起来生成最终查询结果
6、缓存 如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据
由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
7、插入式存储引擎 存储引擎说白了就是如何管理操作数据(存储数据、如何更新、查询数据等)的一种方法。因为在关系数据库 中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)
说明:
在Oracle 和SQL Server等数据库中,所有数据存储管理机制都是一样的。而MySql数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。
甚至一个库中不同的表使用不同的存储引擎,这些都是允许的。