转自:http://blog.csdn.net/s630730701/article/details/51902762
在SCOTT用户下,执行下面SQL;
SELECT
s.deptno,s.ename,s.sal,
RANK() over(partition by s.deptno order by s.sal) as rank,
DENSE_RANK() over(partition by s.deptno order by s.sal) as dense_rank,
ROW_NUMBER() over(partition by s.deptno order by s.sal) as row_number
FROM emp s;
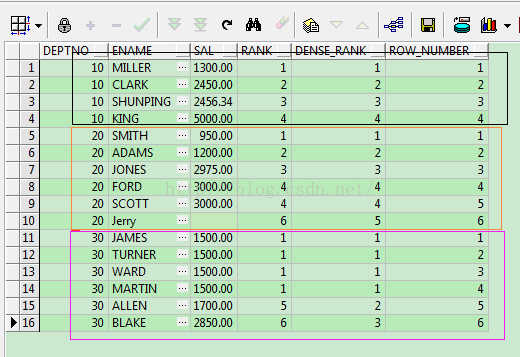
这是一个查询每个部门员工工资的排序情况
从查询结果中很明显的发现规律:
RANK() 发生不持续的编号 例如数据值 1,2,2,3 发生的编号将是1,2,2,4
DENSE_RANK() 发生持续的编号 例如数据值 1,2,2,3 发生的编号将是1,2,2,3
ROW_NUMBER() 发生持续的编号(不重复) 例如数据值 1,2,2,3 发生的编号将是1,2,3,4
RANK() 和 DENSE_RANK() 排序的差异就是排序存在并列的情况下。