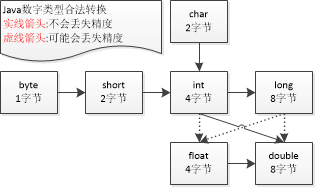
4,基本类型赋值 int->long->float->double
5,公式-n=~n+1可推出~n=-n-1
6,类的加载过程
父类静态代码块-->子类静态代码块-->父类普通代码块-->父类构造方法-->子类代码块-->子类构造方法;
1、虚拟机在首次加载Java类时,会对静态初始化块、静态成员变量、静态方法进行一次初始化。我们不要去纠结这里的顺序,一般来说我们只需要知道,静态方法一般在最后。
2、只有在调用new方法时才会创建类的实例
3、类实例创建过程:按照父子继承关系进行初始化,首先执行父类的初始化块部分,然后是父类的构造方法;再执行本类继承的子类的初始化块,最后是子类的构造方法
4、类实例销毁时候,首先销毁子类部分,再销毁父类部分
7,关键字
java中true ,false , null 显式常量值,但是不能使用它们作为标识符。
关于HashMap的一些说法:
a) HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。HashMap的底层结构是一个数组,数组中的每一项是一条链表。
b) HashMap的实例有俩个参数影响其性能: “初始容量” 和 装填因子。
c) HashMap实现不同步,线程不安全。 HashTable线程安全
d) HashMap中的key-value都是存储在Entry中的。
e) HashMap可以存null键和null值,不保证元素的顺序恒久不变,它的底层使用的是数组和链表,通过hashCode()方法和equals方法保证键的唯一性
f) 解决冲突主要有三种方法:定址法,拉链法,再散列法。HashMap是采用拉链法解决哈希冲突的。
注: 链表法是将相同hash值的对象组成一个链表放在hash值对应的槽位;
用开放定址法解决冲突的做法是:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。 沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。
拉链法解决冲突的做法是: 将所有关键字为同义词的结点链接在同一个单链表中 。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。拉链法适合未规定元素的大小。
Hashtable和HashMap的区别:
a) 继承不同。
public class Hashtable extends Dictionary implements Map
public class HashMap extends AbstractMap implements Map
b) Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
c) Hashtable 中, key 和 value 都不允许出现 null 值。 在 HashMap 中, null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为 null 。当 get() 方法返回 null 值时,即可以表示 HashMap 中没有该键,也可以表示该键所对应的值为null 。因此,在 HashMap 中不能由 get() 方法来判断 HashMap 中是否存在某个键, 而应该用 containsKey() 方法来判断。
d) 两个遍历方式的内部实现上不同。Hashtable、HashMap都使用了Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
e) 哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
f) Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
g)HashMap没有Contains方法
10,ThreadLocal类
ThreadLocal保证各个线程间数据安全,每个线程的数据不会被另外线程访问和破坏
11,
Java锁的种类以及辨析1、自旋锁 2、自旋锁的其他种类 3、阻塞锁 4、可重入锁 5、读写锁 6、互斥锁 7、悲观锁 8、乐观锁 9、公平锁
10、非公平锁 11、偏向锁 12、对象锁 13、线程锁 14、锁粗化 15、轻量级锁 16、锁消除 17、锁膨胀 18、信号量
12,Statement类
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,int length);
1 public static int[] copyOf(int[] original, int newLength) { 2 int[] copy = new int[newLength]; 3 System.arraycopy(original, 0, copy, 0, 4 Math.min(original.length, newLength)); 5 return copy; 6 }
4.clone的话,返回的是Object【】,需要强制转换。 一般用clone效率是最差的,
14,子父类的执行顺序?
父类B静态代码块->子类A静态代码块->父类B非静态代码块->父类B构造函数->子类A非静态代码块->子类A构造函数
15,覆盖(静态与非静态)
method1:静态方法不能隐藏父类中的实例方法。method3:实例方法不能覆盖父类中的静态方法。父类的实例方法被子类的同名实例方法覆盖,父类的静态方法被子类的同名静态方法隐藏,覆盖只能适用于实例方法,不能用于静态方法。静态方法只能隐藏,不能被覆盖。
16,数据库
一般关系数据模型和对象数据模型之间有以下对应关系:表对应类,记录对应对象,表的字段对应类的属性
- DriverManager.getConnection方法返回一个Connection对象,这是加载驱动之后才能进行的
- 加载驱动方法