1.两种方式管理偏移量并将偏移量写入redis
(1)第一种:rdd的形式
一般是使用这种直连的方式,但其缺点是没法调用一些更加高级的api,如窗口操作。如果想更加精确的控制偏移量,就使用这种方式
代码如下
KafkaStreamingWordCountManageOffsetRddApi


package com._51doit.spark13 import com._51doit.utils.JedisConnectionPool import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010.{CanCommitOffsets, ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange} import org.apache.spark.streaming.{Milliseconds, StreamingContext} object KafkaStreamingWordCountManageOffsetRddApi { def main(args: Array[String]): Unit = { val conf = new SparkConf() .setAppName(this.getClass.getSimpleName) .setMaster("local[*]") //创建StreamingContext,并指定批次生成的时间 val ssc = new StreamingContext(conf, Milliseconds(5000)) //设置日志级别 ssc.sparkContext.setLogLevel("WARN") //SparkStreaming 跟kafka进行整合 //1.导入跟Kafka整合的依赖 //2.跟kafka整合,创建直连的DStream【使用底层的消费API,效率更高】 val topics = Array("test11") //SparkSteaming跟kafka整合的参数 //kafka的消费者默认的参数就是每5秒钟自动提交偏移量到Kafka特殊的topic中: __consumer_offsets val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "feng05:9092,feng06:9092,feng07:9092", "key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "group.id" -> "g013", "auto.offset.reset" -> "earliest" //如果没有记录偏移量,第一次从最开始读,有偏移量,接着偏移量读 , "enable.auto.commit" -> (false: java.lang.Boolean) //消费者不自动提交偏移量 ) //跟Kafka进行整合,需要引入跟Kafka整合的依赖 //createDirectStream更加高效,使用的是Kafka底层的消费API,消费者直接连接到Kafka的Leader分区进行消费 //直连方式,RDD的分区数量和Kafka的分区数量是一一对应的【数目一样】 val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, //调度task到Kafka所在的节点 ConsumerStrategies.Subscribe[String, String](topics, kafkaParams) //指定订阅Topic的规则 ) kafkaDStream.foreachRDD(rdd => { //println(rdd + "-> partitions " + rdd.partitions.length) //判断当前批次的RDD是否有数据 if (!rdd.isEmpty()) { //将RDD转换成KafkaRDD,获取KafkaRDD每一个分区的偏移量【在Driver端】 val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges // //循环遍历每个分区的偏移量 // for (range <- offsetRanges) { // println(s"topic: ${range.topic}, partition: ${range.partition}, fromOffset : ${range.fromOffset} -> utilOffset: ${range.untilOffset}") // } //将获取到的偏移量写入到相应的存储系统呢【Kafka、Redis、MySQL】 //将偏移量写入到Kafka //对RDD进行处理 //Transformation 开始 val keys = rdd.map(_.key()) println(keys.collect().toBuffer) val lines: RDD[String] = rdd.map(_.value()) println(lines.collect().toBuffer) val words: RDD[String] = lines.flatMap(_.split(" ")) val wordAndOne: RDD[(String, Int)] = words.map((_, 1)) val reduced: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _) //Transformation 结束 //触发Action reduced.foreachPartition(it => { //在Executor端获取Redis连接 val jedis = JedisConnectionPool.getConnection jedis.select(3) //将分区对应的结果写入到Redis it.foreach(t => { jedis.hincrBy("wc_adv", t._1, t._2) }) //将连接还回连接池 jedis.close() }) //再更新这个批次每个分区的偏移量 //异步提交偏移量,将偏移量写入到Kafka特殊的topic中了 kafkaDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) } }) ssc.start() ssc.awaitTermination() } }
(2) 第二种:DStream的形式
功能更加丰富,可以使用DStream的api,但最终还是要调用foreachrdd,将数据写入redis
代码如下
KafkaStreamingWordCountManageOffsetDstreamApi
package com._51doit.spark13 import com._51doit.utils.JedisConnectionPool import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.kafka010.{CanCommitOffsets, ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange} import org.apache.spark.streaming.{Milliseconds, StreamingContext} import redis.clients.jedis.Jedis object KafkaStreamingWordCountManageOffsetDstreamApi { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf() .setAppName(this.getClass.getSimpleName) .setMaster("local[*]") // 创建StreamingContext,并指定批次生成的时间 val ssc: StreamingContext = new StreamingContext(conf, Milliseconds(5000)) // 设置日志的级别 ssc.sparkContext.setLogLevel("WARN") // kafka整合SparkStreaming // 1.导入跟kafka整合的依赖 2. 跟kafka整合,创建直连的Dstream[使用底层的消费API,消费更高] val topics = Array("test11") // SparkStreaming跟kafka整合的参数 //kafka的消费者默认的参数就是每5秒钟自动提交偏移量到Kafka特殊的topic中: __consumer_offsets val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "feng05:9092,feng06:9092,feng07:9092", "key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "group.id" -> "g014", "auto.offset.reset" -> "earliest" //如果没有记录偏移量,第一次从最开始读,有偏移量,接着偏移量读 , "enable.auto.commit" -> (false: java.lang.Boolean) //消费者不自动提交偏移量 ) //直连方式,RDD的分区数量和Kafka的分区数量是一一对应的【数目一样】 val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String,String]( ssc, LocationStrategies.PreferConsistent, // 调度task到kafka所在的节点 ConsumerStrategies Subscribe[String, String](topics, kafkaParams) //消费者策略,指定订阅topic的规则 ) var offsetRanges: Array[OffsetRange] = null // 调用transform,取出kafkaRDD并获取每一个分区对应的偏移量 val transformDS: DStream[ConsumerRecord[String, String]] = kafkaDStream.transform(rdd => { // 在该函数中,获取偏移量 offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges rdd }) // 调用DStream的API,其有一些RDD没有的API,如upsteateByKey, Window相关的操作 val reducedDStream: DStream[(String, Int)] = transformDS.map(_.value()).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) // 将数据写入redis,此时还是需要使用foreachRDD reducedDStream.foreachRDD(rdd => { if(!rdd.isEmpty()){ rdd.foreachPartition(it =>{ // 在Executor端获取Redis连接 c val jedis: Jedis = JedisConnectionPool.getConnection jedis.select(4) it.foreach(t=>{ jedis.hincrBy("wc_adv2",t._1, t._2) }) jedis.close() }) // 将计算完的批次对应的偏移量提交(在driver端移交偏移量) kafkaDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) } }) ssc.start() ssc.awaitTermination() } }
以上两种方式都无法保证数据只读取处理一次(即exactly once)。因为若是提交偏移量时出现网络问题,导致偏移量没有进行更新,但是数据却成功统计到redis中,这样就会反复读取某段数据进行统计
解决方法:使用事务,即数据的统计与偏移量的写入要同时成功,否则就回滚
2. MySQL事务的测试
MySQLTransactionTest
package cn._51doit.spark.day13 import java.sql.{Connection, DriverManager, PreparedStatement} /** * mysql的哪一种存储引擎支持事物呢? * InnoDB */ object MySQLTransactionTest { def main(args: Array[String]): Unit = { var connection: Connection = null var ps1: PreparedStatement = null var ps2: PreparedStatement = null try { //默认MySQL自动提交事物 connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "123456") //不要自动提交事物 connection.setAutoCommit(false) ps1 = connection.prepareStatement("INSERT INTO t_user1 (name,age) VALUES (?, ?)") //设置参数 ps1.setString(1, "AAA") ps1.setInt(2, 18) //执行 ps1.executeUpdate() val i = 1 / 0 //往另外一个表写入数据 ps2 = connection.prepareStatement("INSERT INTO t_user2 (name,age) VALUES (?, ?)") //设置参数 ps2.setString(1, "BBB") ps2.setInt(2, 28) //执行 ps2.executeUpdate() //多个对数据库操作成功了,在提交事物 connection.commit() } catch { case e: Exception => { e.printStackTrace() //回顾事物 connection.rollback() } } finally { if(ps2 != null) { ps2.close() } if(ps1 != null) { ps1.close() } if(connection != null) { connection.close() } } } }
注意:mysql只有InnoDB引擎支持事务,其它引擎都不支持
3.利用MySQL事务实现数据统计的ExactlyOnce
思路:
从Kafka读取数据,实现ExactlyOnce,偏移量保存到MySQL中
- 1. 将聚合好的数据,收集到driver端(若不收集到driver端,count和偏移量就无法写入一个事务,count数据实在executor中得到,而事务实在driver端得到)
- 2 然后将计算好的数据和偏移量在一个事物中同时保存到MySQL中
- 3 成功了提交事务
- 4 失败了让这个任务重启

代码
(1)ExactlyWordCountOffsetStoreInMySQL(没有查询mysql中的历史偏移量)
package com._51doit.spark13 import java.lang import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange} import org.apache.spark.streaming.{Milliseconds, StreamingContext} object ExactlyWordCountOffsetStoreInMySQL { def main(args: Array[String]): Unit = { //true a1 g1 ta,tb val Array(isLocal, appName, groupId, allTopics) = args val conf: SparkConf = new SparkConf() .setAppName(appName) if (isLocal.toBoolean){ conf.setMaster("local[*]") } //创建StreamingContext,并指定批次生成的时间 val ssc = new StreamingContext(conf, Milliseconds(5000)) // 设置日志级别 ssc.sparkContext.setLogLevel("WARN") // SparkStreaming跟kafka进行整合 // 1.导入跟kafka整合的依赖 2. 跟kafka整合,创建直连的DStream // SparkStreaming跟kafka整合的参数 // kafka的消费者默认的参数就是5秒钟自动提交偏移量到kafka特殊的topic(__consumer_offsets)中 val kafkaParams: Map[String, Object] = Map[String, Object]( "bootstrap.servers" -> "feng05:9092,feng06:9092,feng07:9092", "key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "group.id" -> groupId, "auto.offset.reset" -> "earliest" //如果没有记录偏移量,第一次从最开始读,有偏移量,接着偏移量读 , "enable.auto.commit" -> (false: lang.Boolean) //消费者不自动提交偏移量 ) // 需要订阅的topic val topics = allTopics.split(",") // 跟kafka进行整合,需要引入跟kafka整合的依赖 //createDirectStream更加高效,使用的是Kafka底层的消费API,消费者直接连接到Kafka的Leader分区进行消费 //直连方式,RDD的分区数量和Kafka的分区数量是一一对应的【数目一样】 val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, //调度task到Kafka所在的节点 ConsumerStrategies.Subscribe[String, String](topics, kafkaParams) //指定订阅Topic的规则 ) kafkaDStream.foreachRDD(rdd => { // 判断当前批次的rdd是否有数据 if(!rdd.isEmpty()){ val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges println("偏移量长度"+offsetRanges.length) println(offsetRanges.toBuffer) // 进行wc计算 val words = rdd.flatMap(_.value().split(" ")) val wordAndOne: RDD[(String, Int)] = words.map((_, 1)) val reduced: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _) //将计算好的结果收集到Driver端再写入到MySQL中【保证数据和偏移量写入在一个事物中】 //触发Action,将数据收集到Driver段 val res: Array[(String, Int)] = reduced.collect() println("长度"+res.length) println(res.toBuffer) var connection:Connection = null var ps1: PreparedStatement = null var ps2: PreparedStatement = null // 利用事务往MYSQL存相关数据 try { connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/db_user", "root", "feng") // 设置不自动提交事务 connection.setAutoCommit(false) // 往mysql中写入word以及相应的count val ps1: PreparedStatement = connection.prepareStatement("INSERT INTO t_wordcount (word, count) VALUES(?, ?) ON DUPLICATE KEY UPDATE count=count+?") for (tp <- res){ ps1.setString(1,tp._1) ps1.setInt(2,tp._2) ps1.setInt(3,tp._2) ps1.executeUpdate() //没有提交事务,不会将数据真正写入MYSQL } // 往mysql中写入偏移量 val ps2: PreparedStatement = connection.prepareStatement("INSERT INTO t_kafka_offset (app_gid, topic_partition, offset) VALUES(?, ?, ?) ON DUPLICATE KEY UPDATE offset=?") for (offsetRange <- offsetRanges){ //topic名称 val topic: String = offsetRange.topic // topic分区编号 val partition: Int = offsetRange.partition // 获取结束的偏移量 val utilOffset: Long = offsetRange.untilOffset ps2.setString(1, appName+"_"+groupId) ps2.setString(2,topic+"_"+partition) ps2.setLong(3,utilOffset) ps2.setLong(4,utilOffset) ps2.executeUpdate() } // 提交事务 connection.commit() } catch { case e:Exception => { // 回滚事务 connection.rollback() // 让人物停掉 ssc.stop() } } finally{ if(ps2 != null){ ps2.close() } if(ps1 != null){ ps1.close() } if(connection != null){ connection.close() } } } }) ssc.start() ssc.awaitTermination() } }
此处自己的代码出现了如下问题(暂时没有解决)
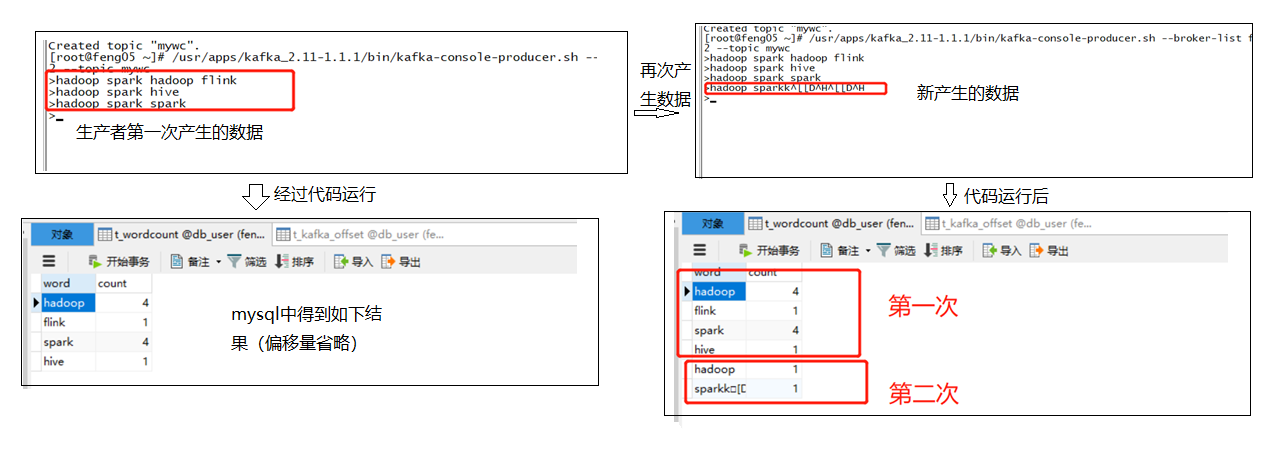
当再次消费生产者产生的数据时,统计出现如上问题(暂时没解决),
(2)若是不查询mysql中的偏移量,可能存在重复读取kafka中的数据,比如mysql挂掉时,代码继续消费生产者产生的数据,但数据没有成功写入mysql,当重启mysql并相应重启代码时,会发现kafka中的所有数据会被重新读取一遍,原因:

解决办法,在消费kafka中的数据时,先读取mysql中的偏移量数据,这样消费者从kafka中消费数据时就会从指定的偏移量开始消费,具体代码如下
ExactlyWordCountOffsetStoreInMySQL(考虑了mysql已经存储的历史记录)
package cn._51doit.spark.day13 import java.sql.{Connection, DriverManager, PreparedStatement} import cn._51doit.spark.utils.OffsetUtils import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.TopicPartition import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010._ import org.apache.spark.streaming.{Milliseconds, StreamingContext} /** * 从Kafka读取数据,实现ExactlyOnce,偏移量保存到MySQL中 * 1.将聚合好的数据,收集到Driver端, * 2.然后建计算好的数据和偏移量在一个事物中同时保存到MySQL中 * 3.成功了提交事物 * 4.失败了让这个任务重启 * * MySQL数据库中有两张表:保存计算好的结果、保存偏移量 */ object ExactlyOnceWordCountOffsetStoreInMySQL { def main(args: Array[String]): Unit = { //true a1 g1 ta,tb val Array(isLocal, appName, groupId, allTopics) = args val conf = new SparkConf() .setAppName(appName) if (isLocal.toBoolean) { conf.setMaster("local[*]") } //创建StreamingContext,并指定批次生成的时间 val ssc = new StreamingContext(conf, Milliseconds(5000)) //设置日志级别 ssc.sparkContext.setLogLevel("WARN") //SparkStreaming 跟kafka进行整合 //1.导入跟Kafka整合的依赖 //2.跟kafka整合,创建直连的DStream【使用底层的消费API,效率更高】 val topics = allTopics.split(",") //SparkSteaming跟kafka整合的参数 //kafka的消费者默认的参数就是每5秒钟自动提交偏移量到Kafka特殊的topic中: __consumer_offsets val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "node-1.51doit.cn:9092,node-2.51doit.cn:9092,node-3.51doit.cn:9092", "key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer", "group.id" -> groupId, "auto.offset.reset" -> "earliest" //如果没有记录偏移量,第一次从最开始读,有偏移量,接着偏移量读 , "enable.auto.commit" -> (false: java.lang.Boolean) //消费者不自动提交偏移量 ) //在创建KafkaDStream之前要先读取MySQL数据库,查询历史偏移量,没有就从头读,有就接着读 //offsets: collection.Map[TopicPartition, Long] val offsets: Map[TopicPartition, Long] = OffsetUtils.queryHistoryOffsetFromMySQL(appName, groupId) //跟Kafka进行整合,需要引入跟Kafka整合的依赖 //createDirectStream更加高效,使用的是Kafka底层的消费API,消费者直接连接到Kafka的Leader分区进行消费 //直连方式,RDD的分区数量和Kafka的分区数量是一一对应的【数目一样】 val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, //调度task到Kafka所在的节点 ConsumerStrategies.Subscribe[String, String](topics, kafkaParams, offsets) //指定订阅Topic的规则 ) kafkaDStream.foreachRDD(rdd => { //判断当前批次的RDD是否有数据 if (!rdd.isEmpty()) { //获取RDD所有分区的偏移量 val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //实现WordCount业务逻辑 val words: RDD[String] = rdd.flatMap(_.value().split(" ")) val wordsAndOne: RDD[(String, Int)] = words.map((_, 1)) val reduced: RDD[(String, Int)] = wordsAndOne.reduceByKey(_ + _) //将计算好的结果收集到Driver端再写入到MySQL中【保证数据和偏移量写入在一个事物中】 //触发Action,将数据收集到Driver段 val res: Array[(String, Int)] = reduced.collect() //创建一个MySQL的连接【在Driver端创建】 //默认MySQL自动提交事物 var connection: Connection = null var ps1: PreparedStatement = null var ps2: PreparedStatement = null try { connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "123456") //不要自动提交事物 connection.setAutoCommit(false) ps1 = connection.prepareStatement("INSERT INTO t_wordcount (word, counts) VALUES (?, ?) ON DUPLICATE KEY UPDATE counts = counts + ?") //将计算好的WordCount结果写入数据库表中,但是没有提交事物 for (tp <- res) { ps1.setString(1, tp._1) ps1.setLong(2, tp._2) ps1.setLong(3, tp._2) ps1.executeUpdate() //没有提交事物,不会讲数据真正写入到MySQL } //(app1_g001, wc_0) -> 1000 ps2 = connection.prepareStatement("INSERT INTO t_kafka_offset (app_gid, topic_partition, offset) VALUES (?, ?, ?) ON DUPLICATE KEY UPDATE offset = ?") //将偏移量写入到MySQL的另外一个表中,也没有提交事物 for (offsetRange <- offsetRanges) { //topic名称 val topic = offsetRange.topic //topic分区编号 val partition = offsetRange.partition //获取结束偏移量 val untilOffset = offsetRange.untilOffset //将结果写入MySQL ps2.setString(1, appName + "_" + groupId) ps2.setString(2, topic + "_" + partition) ps2.setLong(3, untilOffset) ps2.setLong(4, untilOffset) ps2.executeUpdate() } //提交事物 connection.commit() } catch { case e: Exception => { //回滚事物 connection.rollback() //让任务停掉 ssc.stop() } } finally { if(ps2 != null) { ps2.close() } if(ps1 != null) { ps1.close() } if(connection != null) { connection.close() } } } }) ssc.start() ssc.awaitTermination() } }
OffsetUtils类(封装了查询偏移量的方法:queryHistoryOffsetFromMysql)
package com._51doit.utils import java.sql.{Connection, DriverManager, ResultSet} import org.apache.kafka.common.TopicPartition import org.apache.spark.streaming.kafka010.OffsetRange import scala.collection.mutable object OffsetUtils { def queryHistoryOffsetFromMySQL(appName: String, groupId: String): Map[TopicPartition, Long] = { val offsets = new mutable.HashMap[TopicPartition, Long]() val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "123456") val ps = connection.prepareStatement("SELECT topic_partition, offset FROM t_kafka_offset WHERE" + " app_gid = ?") ps.setString(1, appName + "_" +groupId) val rs: ResultSet = ps.executeQuery() while (rs.next()) { val topicAndPartition = rs.getString(1) val offset = rs.getLong(2) val fields = topicAndPartition.split("_") val topic = fields(0) val partition = fields(1).toInt val topicPartition = new TopicPartition(topic, partition) //将构建好的TopicPartition放入map中 offsets(topicPartition) = offset } offsets.toMap } /** * 将偏移量更新到MySQL中 * @param offsetRanges * @param connection */ def updateOffsetToMySQL(appNameAndGroupId: String, offsetRanges: Array[OffsetRange], connection: Connection) = { val ps = connection.prepareStatement("INSERT INTO t_kafka_offset (app_gid, topic_partition, offset) VALUES (?, ?, ?) ON DUPLICATE KEY UPDATE offset = ?") for (offsetRange <- offsetRanges) { //topic名称 val topic = offsetRange.topic //topic分区编号 val partition = offsetRange.partition //获取结束偏移量 val untilOffset = offsetRange.untilOffset //将结果写入MySQL ps.setString(1, appNameAndGroupId) ps.setString(2, topic + "_" + partition) ps.setLong(3, untilOffset) ps.setLong(4, untilOffset) ps.executeUpdate() } ps.close() } }
4 将数据写入kafka
需求:将access.log的数据写入kafka中
此相当于自己写了一个kafka生产者,然后把数据写入名叫access的topic中,然后就可以使用sparkstreaming消费kafka中的数据,然后进行统计
DataToKafka代码
package cn._51doit.spark.day12 import java.util.Properties import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord} import org.apache.kafka.common.serialization.StringSerializer import scala.io.Source // 相当于自己写了一个kafka生产者,然后把数据写入access的topic中,然后就可以使用sparkstreaming消费kafka中的数据,然后进行统计 object DataToKafka { def main(args: Array[String]): Unit = { // 1 配置参数 val props = new Properties() // 连接kafka节点 props.setProperty("bootstrap.servers", "node-1.51doit.cn:9092,node-2.51doit.cn:9092,node-3.51doit.cn:9092") //指定key序列化方式 props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer") //指定value序列化方式 props.setProperty("value.serializer", classOf[StringSerializer].getName) // 两种写法都行 val topic = "access" // 2 kafka的生产者 val producer: KafkaProducer[String, String] = new KafkaProducer[String, String](props) //读取一个文件的数据 val iterator = Source.fromFile(args(0)).getLines() iterator.foreach(line => { //没有指定Key和分区,默认的策略就是轮询,数据写入一部分后,切换leader分区(均匀写入多个分区中) val record = new ProducerRecord[String, String](topic,line) // 4 发送消息 producer.send(record) }) println("message send success") // 释放资源 producer.close() } }
tttt