1. 函数
函数就是一个非常灵活的运算逻辑,可以灵活的将函数传入方法中,前提是方法中接收的是类型一致的函数类型
函数式编程的好处:想要做什么就调用相应的方法(fliter、map、groupBy、sortBy),想要具体怎么做,就传入相应的函数
函数式编程的特点之一就是支持链式编程(不停的函数调用函数)
1.1 一种更加简洁的定义函数的方式(_)
以前的形式

简洁的形式

"_" 相当于一个占位符,将遍历出来的值赋给这个占位符
该占位符号出现两次,其会认为出现两个参数,由于此处就是一个参数,若用如下表达式求平方会报错

此时想求平方的话可以使用math包来达到目的
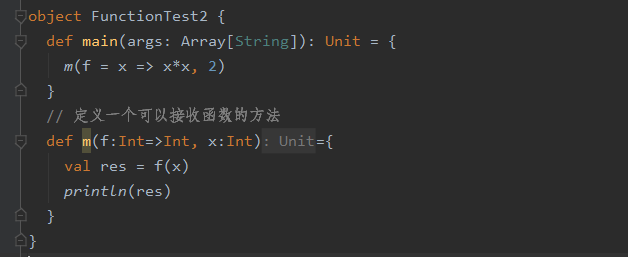
1.2 函数和方法区别
函数可以作为参数传入到方法中【函数本质是一个引用类型】,但是方法不能作为参数传入方法中
函数中也可以调用方法
下面的例子似乎能得到方法可以作为参数传入方法

m相当于m _的语法糖,m _会生成一个函数
问题1:为什么在方法中传入方法m可以执行相应的运算呢?
因为当传入一个方法名时,scala内部会将其转换成函数,实际传入的还是一个函数
问题2:m _这种语法到底是生成了一个跟m方法运算逻辑一样的函数,还是生成的函数调用了m方法呢
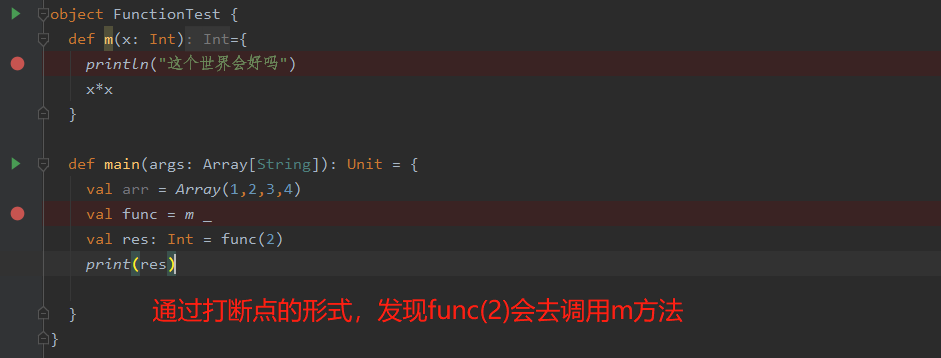
所以m _这种语法是生成了一个函数,这个生成的函数再调用了m方法
案例
2. 数组和集合常用的方法
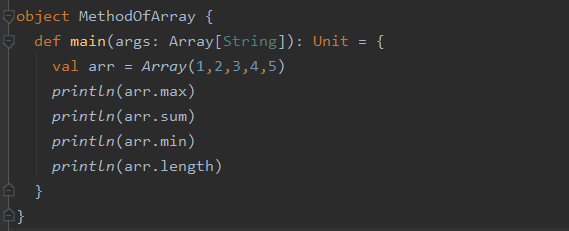
2.1 max(最大值),min(最小值),sum(求和),length(长度)
2.2 reduce、fold
- reduce
在Scala中,可以使用reduce这种二元操作对集合中的元素进行归约,reduce包含reduceLeft和reduceRight两种操作,前者从集合的头部开始操作,后者从集合的尾部开始操作
object MethodOfArray { def main(args: Array[String]): Unit = { val arr = Array(1,2,3) println(arr.reduce(_+_)) // 6 println(arr.reduce(_-_)) // -4 此处说明reduce默认使用reduceLeft println(arr.reduceLeft(_-_)) // -4 println(arr.reduceRight(_-_)) // 2 println(arr.reduce(_*_)) //6 } }
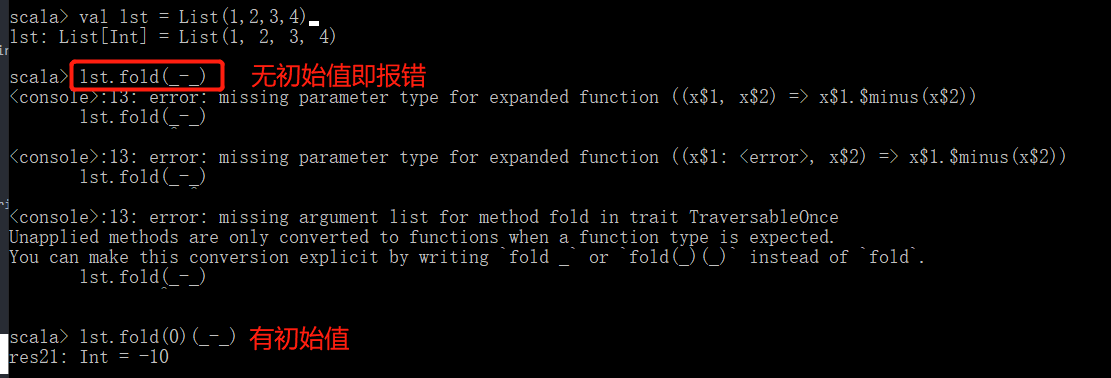
- fold
fold类似reduce,但其一定要从一个初始值开始,并以该值作为上下文,处理集合中的每个元素
2.3 sortBy:排序,默认是升序

以下只是改变比较的规则(将数据以字符串的形式比较),并不是改变数据,所以结果还是Int

若想实现降序,可如下
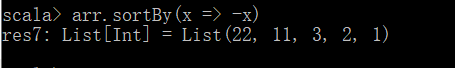
补充:迭代器
迭代器不存储数据,其只是一个帮助拿数据的工具
2.4 求并集

此处因为是List,所以可以有重复,若是改变成Set,这求并集后将不会有重复的元素
2.5 聚合:Aggregate
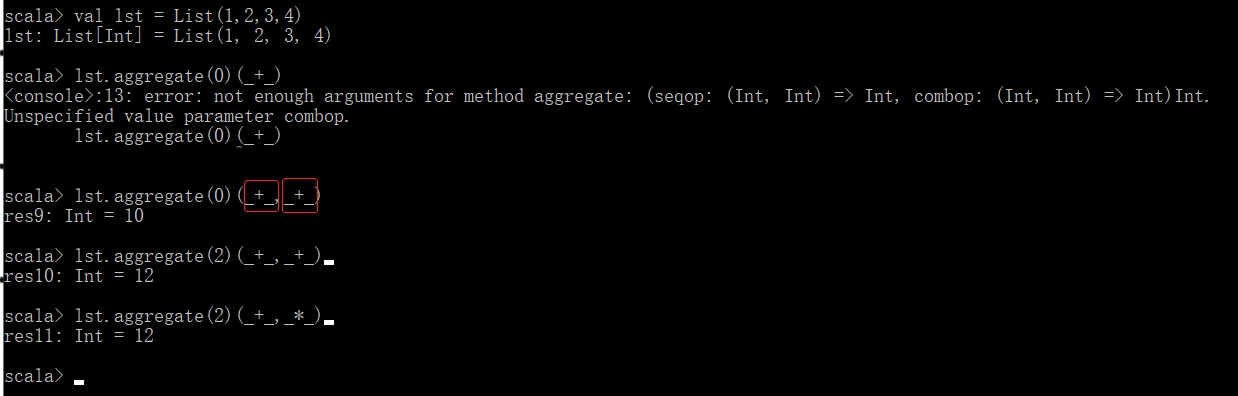
右边的参数用不到,不写会报错,源码如下

2.6 交集和差集
- 交集
val r2 = l1.intersect(l2)
- 差集:去掉相同的元素
val r3 = l1.diff(l2)
2.7 并行化集合(arr.par)


即9个线程运行此任务(得到的值具有随机性)
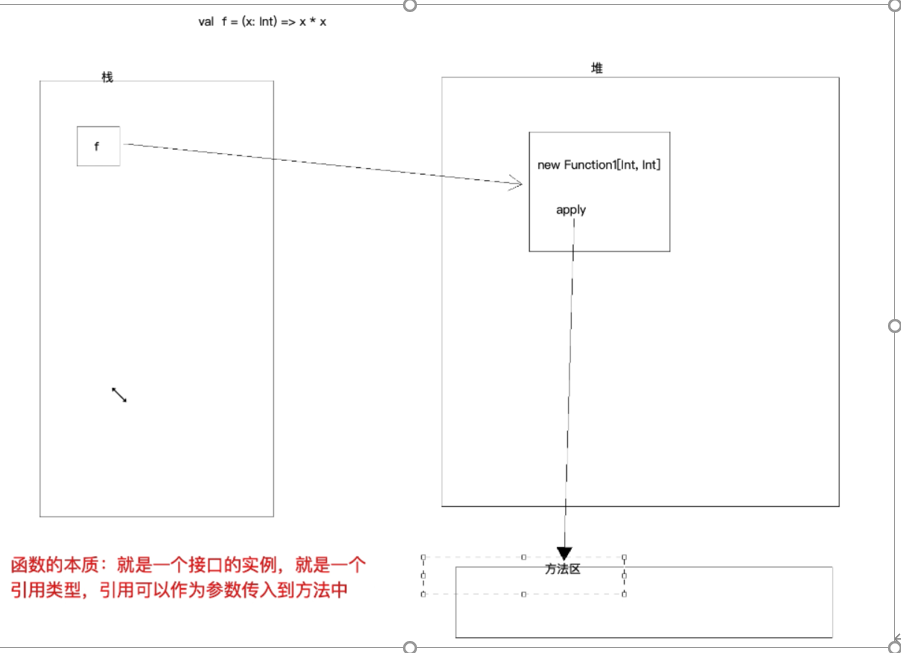
3. 深度理解函数
函数本质是一个接口的实例,是一个引用类型,引用可以作为参数传入到方法中
(1) 以前定义函数的完整形式
val f1:(Int,Double) => Double = (x: Int, y: Double) => (x + y)
(2)但其对应的真正写法应该如下
val f2:Function2[Int, Double, Double] = (x: Int, y: Double) => (x + y) //function2表示函数的输入参数的个数为2
补充: 在scala语言中,函数也是对象,每一个对象都是scala.FunctionN(1-22)1的实例,其中N是函数参数的数量

当点击蓝色字时,发现波浪线处会变成(1)中相应位置处的形式,所以说,(1)中的写法较2中用了语法糖
(3)更加准确的函数定义应该如下(波浪线处提示用语法糖)

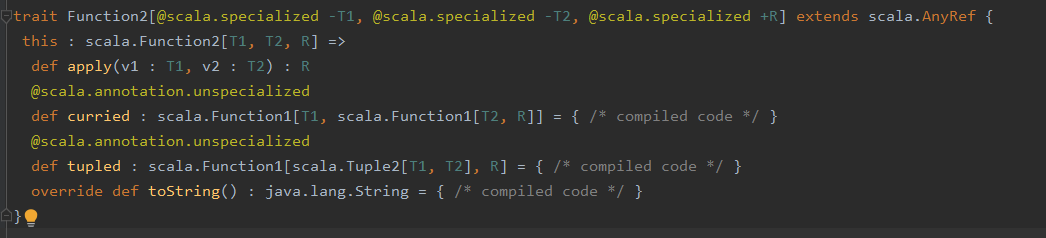
点进Function2,可知其为一个特质(接口),此处相当于定义了一个接口的实例,源码部分如下
图解定义一个函数内部的过程
4 练习

方法一:装饰的方式:
思路:将原始的List用一个新的List(MyList)包装起来,获得一个包装类,然后在这个包装类中定义map方法,从而实现想要的功能
MyList类
public class MyList { private List<String> words; public MyList(List<String> words) { // 定义有参构造方法 this.words = words; } public List<String> map(MapFunction func) { //定义一个新的集合,装转换后的数据 List<String> nList = new ArrayList<>(); //循环老的List for(String word: words) { //应用外部传入的逻辑 String nWord = func.apply(word); //将新的单词添加到新的List中 nList.add(nWord); } //返回新的List return nList; } }
MyFunction类
public interface MapFunction { //定义一个规范,输入一个String,返回一个String public String apply(String word); }
因为MyList对象调用的map方法中传入的是一个运算逻辑,不能写死,所以此处就创建一个接口,不同的逻辑就相当于不同的实现类(即重写的apply方法不一样)
class MyListTest { public static void main(String[] args) { List<String> words = Arrays.asList("Hadoop", "Spark", "Hbase", "Flink", "Hive"); MyList myList = new MyList(words); // 实现后面拼接字符串 List<String> res1 = myList.map(new MapFunction() { @Override public String apply(String word) { return word + 2.0; } }); // 实现List中的元素都变大写 List<String> res2 = myList.map(new MapFunction(){ @Override public String apply(String word) { return word.toUpperCase(); } }); System.out.println(res1); } }
若是在java8中,可以使用Lambda写逻辑运算,如转换大写部分可以直接使用如下替换
List<String> nList = myList.map(w -> w.toUpperCase());
此时可以去看下scala中的map是怎么实现的,类比发现逻辑跟自己上面的写法是一样的
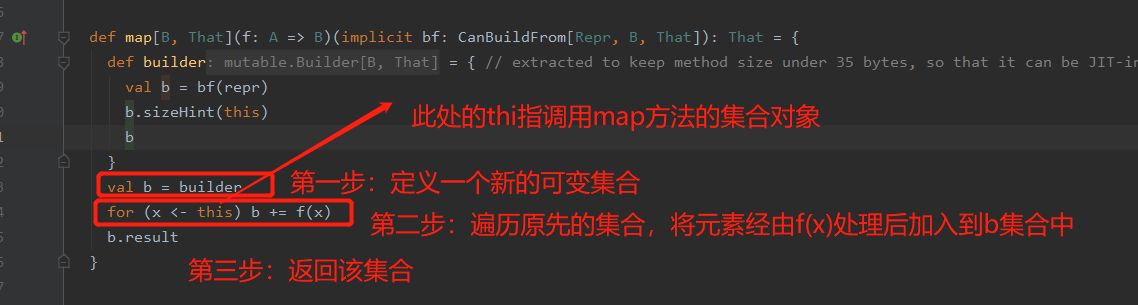
方法二:继承的方式
方法一的缺点:不能使用被包装集合中的方法(如add等),泛型写死,不支持链式编程(自己扩展的方法,)
此方法的优点:
- 具备ArrayList所有的功能
- 扩展了map、filter、reduce等方法
- 支持链式编程 (自己定义的map、fliter等方法返回值类型变为自己定义的集合)
- 支持传入多种数据类型:泛型
MyAdvList
说明:此集合为自己定义的集合,继承了ArrayList(这样就具备了ArrayList的所有功能),并实现了MyTraversableLike接口(scala中的集合,Set等也是实现了这个接口(TraversableLike)的),这样当别的集合想用该方法时,直接实现这个接口就行
public class MyAdvList<T> extends ArrayList<T> implements MyTraversableLike<T>{ @Override public <R> MyAdvList<R> map(MyFunction1<T, R> func) { // 创建一个新的集合,注意此处的返回值为自己定义的MyAdvList,这样才能支持自己写的方法的链式编程 MyAdvList<R> nList = new MyAdvList<>(); // 遍历老的集合(即调用该map方法的集合) for(T t: this){ // 应用外部传入的逻辑 R res = func.apply(t); // 将新的数据放入的刚创建的新的集合中去 nList.add(res); } return nList; } @Override public MyAdvList<T> filter(MyFunction1<T, Boolean> func) { MyAdvList<T> nList = new MyAdvList<>(); for(T t: this){ if(func.apply(t)){ nList.add(t); } } return nList; } }
MyTraversableLike接口
import java.util.List; //MyTraversableLike<T>泛型类,以后T类型就可以在方法中使用了 public interface MyTraversableLike<T> { //泛型方法,在返回值的前面、void的前面<R> /** * 做映射,传入一个运算逻辑,将数据进行处理,返回一个新的List * @param func * @param <R> * @return */ <R> List<R> map(MyFunction1<T, R> func); /** * 对原来集合的数据进行过滤,满足func的条的留下 * @param func * @return */ List<T> filter(MyFunction1<T, Boolean> func); }
MyFunction1(传进map方法中的运算逻辑,相当于一个规范,此处接口可以达到这个目的)
public interface MyFunction1<T, R> { /** * 定义一个规范,属于一个T类型的参数,返回一个R * T 和 R 可以是同一个类型 * @param r * @return */ R apply(T r); }
测试类
public class MyAdvListTest { public static void main(String[] args) { // MyAdvList<String> words = new MyAdvList<>(); // words.add("Hadoop"); // words.add("Spark"); // words.add("Flink"); // words.add("Hive"); // List<String> nList = words.map(new MyFunction1<String, String>() { // @Override // public String apply(String r) { // return r.toUpperCase(); // } // }); MyAdvList<Integer> num = new MyAdvList<>(); num.add(1); num.add(2); num.add(3); num.add(4); // List<Double> nList = num.map(new MyFunction1<Integer, Double>() { // @Override // public Double apply(Integer r) { // return r * 10.0; // } // }); // 链式编程
List<Double> nList = num.map(r -> r * 3.0).filter(x -> x%2==0); System.out.println(nList); } }
这样既可达到需求
补充:java8中Stream【流水线】的使用
public class StreamDemo { public static void main(String[] args) { List<Integer> num = Arrays.asList(1,2,4,5,6,7); // 使用Java8的Stream【流水线】,集合中是没有filter等方法的
Optional<Integer> reduce = num.stream().filter(i -> i % 2 == 0).map(i -> i * i).reduce((a, b) -> a + b); Integer integer = reduce.get(); System.out.println(integer); } }
public class StreamDemo { public static void main(String[] args) { Stream<Integer> integerStream = nums.stream().filter(i -> i % 2 == 0).map(i -> i * i);
// 以下是通过迭代器获取数据 // Iterator<Integer> iterator = integerStream.iterator(); // // while (iterator.hasNext()) { // Integer r = iterator.next(); // System.out.println(r); // }
// java8新特性直接获取 //integerStream.forEach(i -> System.out.println(i)); integerStream.forEach(System.out::println); } }