JanusGraph采用邻接表(adjacency list)的方式存储图,也即图以顶点(vertex)和其邻接表组成。邻接表中保存某个顶点的所有入射边(incident edges)。
通过将图采用邻接表的形式存储,JanusGraph确保了某个顶点的所有入射边和属性都被紧凑的存储在一起,从而能够加快遍历速度,缺点是数据存储了两次。而且JanusGraph以sort key指定的顺序存储数据。
JanusGraph可以采用任何支持big table数据模型的存储后端存储邻接表。
Bigtable Data Model

在Bigtable data model下,表就是行的集合。每个行都唯一的由一个key标识,每行由大量的cell组成。一个cell是由列和值组成的。一个cell唯一的由指定行的制定列所标识。行在bigtable模型中称为“宽行”,表因此称为“宽表”。cell的数量可以非常大,而且不需要预定义。
JanusGraph对bigtable数据模型有一个特殊的要求:cell必须是根据列来排序的,而且由column制定的cell的子集必须可以高效查询。
而且,如果bigtable实现可以根据行的key排序,JanusGraph则可以利用该特性实现更高的图遍历性能。
JanusGraph Data Layout
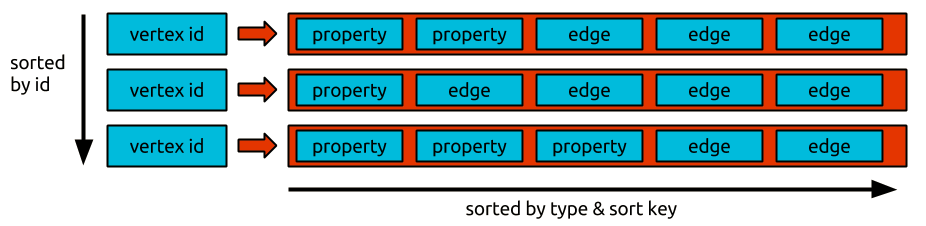
JanusGraph将每个邻接表作为以个row保存在存储后端,64位的vertex id是指向邻接表的key。每个边和属性都是作为独立的cell保存的,以实现更高效插入和删除。没行中最大能保存的cell的个数,也就是vertex的edge的数量限制。
Individual Edge Layout

每个edge和property都作为邻接表的一个cell存储,并通过序列化之后,byte order即表示了edge label的sort key。variableid对schema进行编码和压缩来节省空间。上图中深蓝色的色块表示了对schema进行编码压缩后的ID,用以减少存储消耗。红色快代码一个或多个属性值,该值也被压缩并关联到属性key上。灰色块代表未压缩的属性值,如(序列化的OBJECT)。
Edge有edge label唯一ID开始,并附加一个表示方向的数据位;之后有属性key组成的排序键,再之后是邻接表IDD,和边ID。Janus并不保存实际的vertex id,而是相对于邻接表的偏移量,因其比压缩更节省空间。value部分保存了序列化后的值。
对于属性来说就简单一点,column是属性的key id,property id和property key保存在value部分,如果property key被定义为LIST,property id也保存在列中。
总结
对于理解JanusGraph的存储,关键在于理解其bigtable的邻接表存储结构,而在邻接表中保存了边(包括边的属性)及vertex的属性。
由于边是由两个vertex定义的,故肯定存在有edge的重复保存,这增加了存储空间,但通过冗余也提高了查询效率。
最后是每个邻接表:行,的数据结构,对于一般的应用场景,我们没有必要深入到行存储中去,只是了其存储的一般原理即可。