1. 垃圾收集算法
JVM的垃圾收集算法在不同的JVM实现中有所不同,且在平时工作中一般不会深入到收集算法,因此只对算法做较为简单的介绍。
1.1 标记-清除算法
这种算法是非常直观的,也是最为基础的收集算法(Mark-Sweep)算法,这种算法将回收分为两个阶段:首先标记所有需要回收的对象,然后在完成标记后统一回收掉被标记的对象。这种算法是如此的基础,以至于后面的算法都是基于该思路,并对其确定进行改进所得的。
这种算法的缺点主要有两个:
1. 效率较低,整个回收过程分为标记-回收两个阶段
2. 内存碎片,标记清除之后存在较多内存碎片,可能导致需要连续的较大的内存空间时,没有满足需要的内存空间,从而不得不导致另外一次GC。

1.2 复制算法
为了解决效率问题,复制算法出现了,其将内存划分为容量相等的两块,每次只使用其中一块。当一块的内存用完了,就将活着的对象复制到另外的内存块上,然后把使用过的空间一次清理掉。这样只对一块内存空间进行回收,相当的高效。
但这种算法的问题是将实际可用内存的大小缩小了一般,在内存价格还相当昂贵的今天,代价有些太高了。
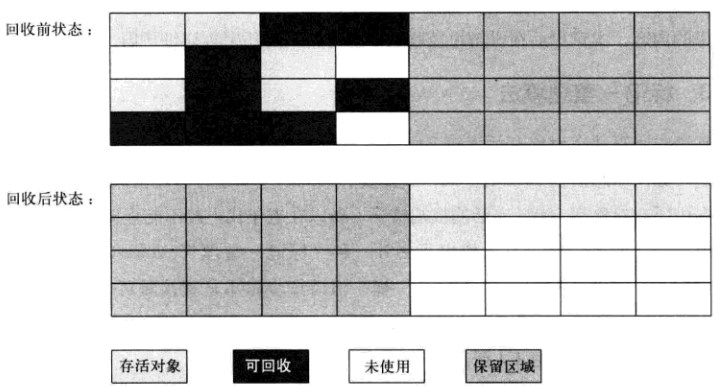
现在的商业虚拟机都使用此种算法来回收新生代,根据IBM研究表明,新生代中98%的对象是朝生夕死的,所以并不需要按照1:1来划分内存空间,而是将新生代划分为一块较大的Eden和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。
回收时,将Eden和Survivor中存活的对象一次性复制到另外的Survivor空间,并清理掉Eden和Survivor空间。这样,可以减少浪费至10%,当survivor空间不够时,需要老年代进行分配担保(Handle Promotion,如果另一个Survivor没有足够空间,则存放到老年代)。
1.3 标记 - 整理算法
复制算法在存货对象较多时需要执行大量的复制操作,这对老年代来说是不合适的,因此有人就提出了标记-整理算法,过程与标记-清除算法一样,但后续步骤不是对可回收对象进行清理,而是让所有的对象都向一端移动,然后直接清理掉边界之外的内存。

1.4 分代收集算法
当前的商业虚拟机均使用分代收集算法,将对象按照存活周期分为几块,一般将Java堆分为新生代与老年代,从而可以根据不同年代的特点使用不同的收集算法。
如新生代中存在大量死去的对象,只有少量存活,使用复制算法;老年代中因存活对象数量多,且没有额外空间,因此需要采用标记 - 清除或 标记 - 清理算法。
2. 垃圾收集器
垃圾收集器是垃圾收集算法的具体实现,Java虚拟机对垃圾收集器如何实现并未做规定,因此不同厂商会有各自的垃圾收集器。如HotSpot虚拟机中的收集器如下所示,其中存在连线的收集器即可搭配使用。
但现在没有最好的收集器,都需要根据具体环境来选择。
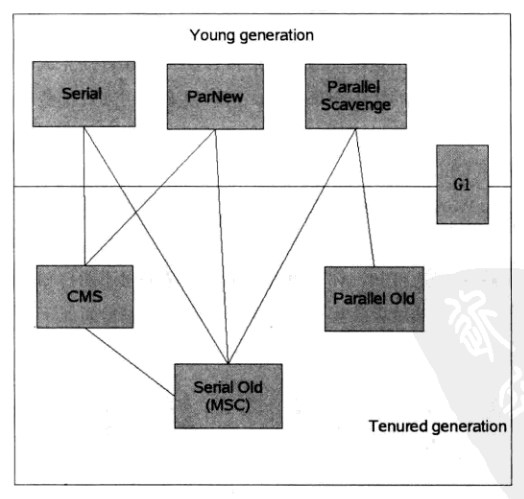
2.1 Serial收集器
串行收集器是最为基本的收集器,它是单线程的,而且在运行时,会停掉其他所有的工作线程(Stop the world),直到其收集结束。在实际应用中,用户很难忍受程序运行暂停。
人们在努力的减少收集器的停顿时间,但没有办法完全消除,虽然Serial收集器有着种种缺点,但其简单而高效,对于Client型应用,其仍是新生代默认的收集器(桌面应用,内存小且停顿时间可忍受)。
2.2 ParNew收集器
ParNew收集器是Serial收集器的多线程版本,且加入了多个控制参数,并与Serial公用相当多的代码
ParNew除了多线程之外,与其他Serial收集器相比并没有太多创新,但其却是许多运行在Server模式下虚拟机首选的新生代收集器,主要是由于它可以通CMS收集器相配合使用。
在单CPU环境下,ParNew性能甚至不如Serial收集器(线程交互开销),但随着CPU数目上升,对于其收集效率还是很有提升的。
2.3 Parallel Scavenge收集器
新生代收集器,使用复制算法,其关注点在于控制吞吐量(Throughout,CPU用于运行用户代码与CPU总消耗时间的比值),主要适用于后台运算而不太关注用户交互的场合
2.4 Serial Old收集器
是Serial收集器的老年代版本,单线程,使用标记-清理算法
2.5 Parallel Old收集器
是Parallel Scavege收集器的老年代版本,使用多线程和”标记-整理“算法
2.6 CMS(Concurrent Mark Sweep)收集器
是一种以获取最短停顿时间为目标的收集器,常应用于重视服务响应速度的场景。其基于标记-清除算法。
CMS收集器对CPU资源非常敏感,在并发阶段,虽然不会导致程序停顿,但由于占用了部分CPU资源,导致应用程序变慢,总的吞吐量变低。
CMS无法处理浮动垃圾,可能出现”Concurrent Mode Failure“而导致另外一次Full GC的产生,这是由于在GC过程中,程序仍然运行,会不断产生垃圾所致
CMS可能在收集结束后产生大量碎片,当碎片数量过多时,将会给大对象的分配带来困难
2.7 G1收集器
G1(Garbage First)收集器是最新的GC 收集器,其基于标记 - 整理算法,并且可以非常精确的控制停顿
2.8 垃圾收集器总结
没有完美的垃圾收集器,需要根据应用的实际情况进行选择和调优,有时候需要选择不同的收集器,有时需要选择收集器的参数
3. 内存分配与回收策略
3.1 对象有优先在Eden区分配,如果没有足够空间,则会发起一次Minor GC -XX:SurvivorRatio=8决定一个新生代Eden与Survivor区比例为8:1
其中新生代GC称为Minor GC,其发生非常频繁,速度也快
其中老年代的GC称为Major GC,比Minor GC慢10倍以上
3.2 大对象直接进入老年代
3.3 长期存活的对象进入老年代(有相应的年龄计数器,活过一次GC则+1)
4. 总结
内存回收与垃圾收集器在很多时候都影响系统性能、并发能力的主要因素,虚拟机有大量参数可供调节,只有根据实际需求、实现方式选择最优的收集方式才能获取最优的性能。没有固定收集器-算法的组合,也没有最优的调优方法,需要通过实践去逼近最高性能。