一、简单单表操作
(1)简单CRUD
|
插入查询结果 |
insert into table1(id,name,age) select id,name,age from table2 where id=1 |
|
更新操作 |
update 表名 set 字段名=’abc’where id=xxx; |
|
避免重复数据查询-distinct |
Select distinct 去重字段名 from 表名 |
|
数学运算 |
select id*10 from表名 |
|
字符串拼接 |
select concat(name,’的工资是:’,salary) |
|
范围查询 |
select name from 表名 where id between 5 and 10 |
|
去除范围查询 |
select name from 表名 where id not between 5 and 10 |
|
为空查询 |
select * from 表名 where field is NULL; |
|
不为空查询 |
select * from 表名 where field is not NULL; |
|
带in关键字集合查询 |
select name from表名 where id in (1,2,3) |
|
带in关键字排除查询 |
select name from表名 where id not in (1,2,3) |
|
备注:关于带in的集合查询,当集合中存在null值时,如Select name from表名 where id in (1,2,3,null),不会影响查询结果。 |
|
|
模糊匹配like |
select name from 表名 where name like ‘XXX%’ |
|
备注:匹配以“xx”开头的字符以%结尾,以“xx”结尾的字符以%开头 |
|
|
占位符_ |
1、 select name from xuanjie where name like ‘_c%’;(第二个字符为c) 2、 select name from xuanjie where name like ‘__c%;(第三个字符为c) |
|
备注:“_”通配符能匹配单个字符,“%”通配符可以匹配任意长度的字符串。Like匹配“%%”则表示查询所有数据记录。非匹配关键字可用not like 表示。 |
|
|
升序 |
select * from 表名 order by 字段名 asc; |
|
降序 |
select * from 表名 order by 字段名 desc; |
|
多字段升序,降序 |
select * from 表名 order by 字段名1 asc,字段名2 desc; |
|
Limit关键字 |
select * from 表名 where id < 8 order by id desc limit 3 |
|
Limit A,B |
A从第几开始,显示B条 |
|
不等于表达式 |
select age from 表名where not name=’cc’; |
(2)统计函数和分组查询
|
统计表中记录的条数count()函数 |
select count(字段名) from 表名 where id < xxx |
|
统计平均值avg()函数 |
select avg(字段名) as xxx from 表名 |
|
统计计算求和sum()函数 |
select sum(字段名) as xxx from 表名 |
|
统计最大值max()函数 |
select max(字段名),min(字段名) from 表名 |
|
统计最大值min()函数 |
|
|
备注:对于MySQL支持的统计函数,如果所操作的表中没有任何记录,则count()函数返回0,其他函数则返回NULL。 |
|
|
简单分组查询group by |
select * from 表名 group by 字段名 |
|
group_concat()函数用以指定显示每个分组中的指定字段值 |
select age,group_concat(字段名),count(字段名) from 表名 group by 分组字段名 |
|
多个字段分组查询 |
group by 字段名1,字段名2 |
|
Having字句限定分组查询 |
select id as uid,group_concat(name) as uname,count(name),avg(age) from xuanjie group by id,age having age > 20; |
|
备注:在MySQL中,如果想实现对分组进行条件限制,不能通过where来实现,因为该关键字主要用来实现条件限制数据记录。MySQL提供了专门的关键字having来实现条件限制分组数据记录。同时,分组查询必须为操作表中有重复的数据,否则没有任何意义。 |
|
二、多表操作原理
MySQL支持通过连接查询来进行多表的操作,具体操作时,首先将两个或两个以上的表按照某个条件进行连接后,再按要求查询目标数据,连接查询包括内连接和外连接。但在实际应用中,一般不使用连接查询,因为笛卡尔乘积的缘故,该操作的效率比较低,所以又出现了同样适合多表查询的子查询。
以下介绍,均围绕以下班级和学生信息表来展开
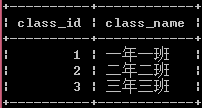
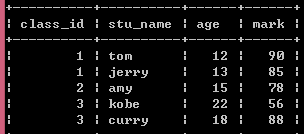
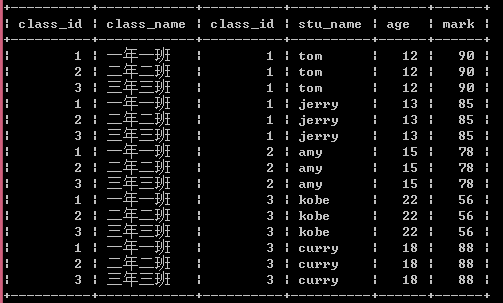
(1)笛卡尔积:没有连接表关系返回的结果。如select * from class,student,出现如下结果,笛卡尔积的结果集数为前一个表的数据总和 x 后一个表的数据总和,中间只是单纯的连接两个表,并没有做数据的匹配等操作。
(2)连接:所谓连接,其实就是在表关系的笛卡尔积中,按照某个条件生成的一个新的关系,连接可分为内连接和外连接。
(3)内连接(INNER JOIN):所谓内连接,就是在表关系的笛卡尔积中,保留表关系中匹配的记录,舍弃不匹配的数据记录,按照匹配的条件可以分为自然连接,等值连接和不等值连接。
(4)自然连接(NATURAL JOIN):所谓自然连接,就是表关系的笛卡尔积,根据表关系中相同名称的字段自动进行数据匹配,然后去掉重复字段。
select * from class natural join student;

(5)等值连接:所谓等值连接,就是表关系的笛卡尔积,选择所匹配字段值相等的数据。如下执行结果,发现与自然连接相比,等值连接会去匹配"="条件,并且在新关系中不会去掉重复字段,如class_id。

(6)不等连接:所谓不等连接,就是在表关系的笛卡尔积中,选择所匹配字段不等于的条件。如下执行结果,会在笛卡尔积中获取"!="不等于条件中的数据,并且不会去掉重复字段,如class_id。
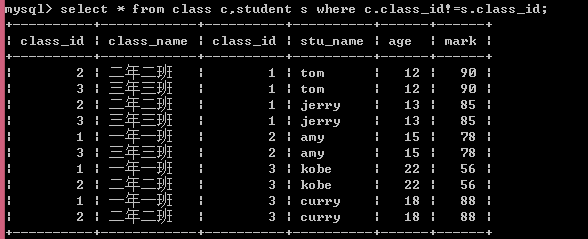
(7)外连接(OUTER JOIN):就是在表关系的笛卡尔积中,不仅会保留部分不匹配的记录,还会保留部分不匹配的记录。外连接包括左外连接(LEFT OUTER JOIN),右外连接(RIGHT OUTER JOIN)和全外连接(FULL OUTER JOIN),以下基于此两张表讲解外连接:
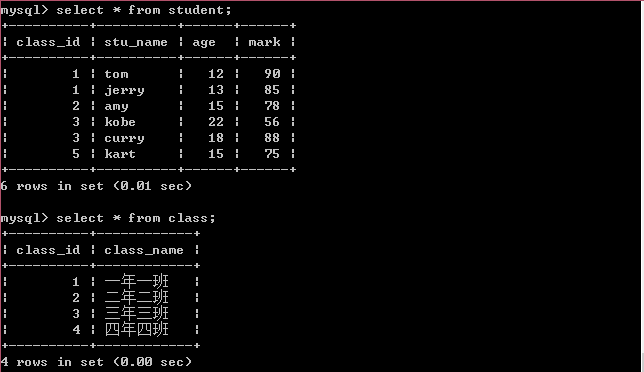
(8)左外连接(LEFT OUTER JOIN):所谓左外连接,就是表关系的笛卡尔积中除了选择匹配的数据记录,还包含左边表中不匹配的数据记录,如下:
(9)右外连接(RIGHT OUTER JOIN):所谓右外连接,就是表关系的笛卡尔积中除了选择匹配的数据记录,还包含右边表中不匹配的数据记录,如下:

(10)全外连接(FULL OUTER JOIN):所谓全外连接,就是表关系的笛卡尔积中,除了选择相匹配的记录,还包含左右两边表中不匹配的数据记录。
三、子查询
为什么使用子查询:在平常的多表连接查询中,由于会对表进行笛卡尔积操作,如果多张表的数据记录大,或字段多,则进行笛卡尔积的时候就会出现死机,对于有经验的SQL开发者,会首先通过统计函数count(*)统计多表的数据记录数,然后才决定是否使用多表查询。
但如果通过统计函数得到的数据记录数过大,则不适合使用多表查询,此时便推荐使用子查询,所谓子查询,即在一个主查询中嵌套了其他的若干查询,如在select xxx from where xxx中嵌套多select,此时,外层的select被称为主查询,内层的则称为子查询。
以下使用该student表作为示例:
示例1:子查询为单行多列
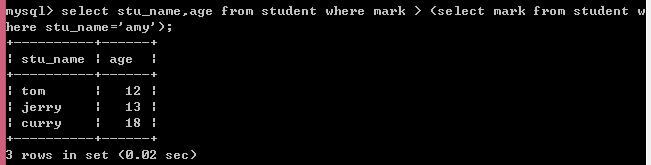
示例2:子查询为单行多列
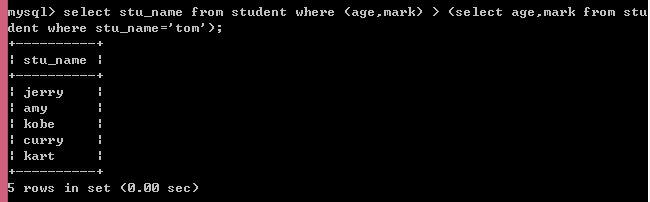
示例3:子查询为多行单列
当子查询返回结果是多行单列数据时,通常会包含in,any,all,exists关键字。
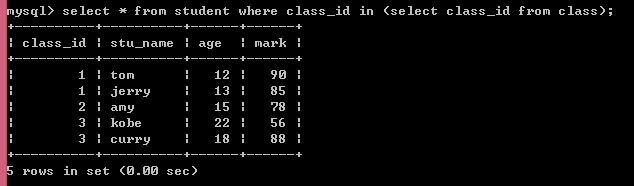
(1)in关键字
(2)any关键字
=any:功能与in一样
>any:比子查询中返回的最小数据还要大的记录
<any:比子查询中返回的最大数据还要小的记录

(3)all关键字
>all:比子查询中返回的最大的记录数还要大的数据
<all:比子查询中返回的最小的记录数还要小的数据

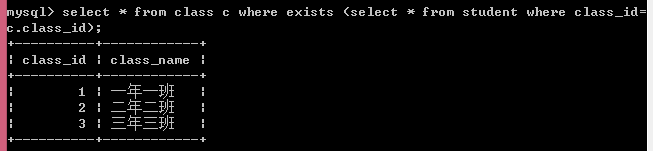
(4)exists关键字
exists查询时会对外表进行遍历逐条查询,然后将结果传到子查询中。
示例4:多行多列子查询
