-Kafka是一个分布式的( distributed )、分区的( partitioned )、复制的( replicated )提交日志( commitlog )服务 。
“分布式”是所有分布式系统的特性 ;“分区”指消息会按照分区分布在集群的所有节点上 ;“复制”指每个分区都会有多个副本存储在不同的节点上;
“提交日志”指新的消息总是以追加的方式进行存储。
写到提交日志的目的是防止节点宕机后,因内存中的数据来不及刷写到磁盘而导致数据丢失 。 分布式存储系统除了提交日志,
一般还有真正的数据存储格式。 它们的提交日志只是作为一种故障恢复的数据源,而Kafka直接使用提交日志作为最终的存储格式。
数据的更新操作在分布式存储系统中很常见,比如不同时间产生相同键( key )的数据 。 分布式存储系统为了保证写数据的性能,
采用追加方式,而不是直接修改已有记录 。 为了只保存最近的一条数据,还会有一个后台的压缩( compaction )操作,负责将相同键
的多条记录合并为一条 。 Kafka的消息如果指定了键,也会有类似的日志压缩操作,保证相同键的消息只会保留最近的一条。
Kafka的消息按照主题进行组织,不同类别的消息分成不同的主题 。 为了提高消息的并行处理能力,每个主题会有多个分区 。
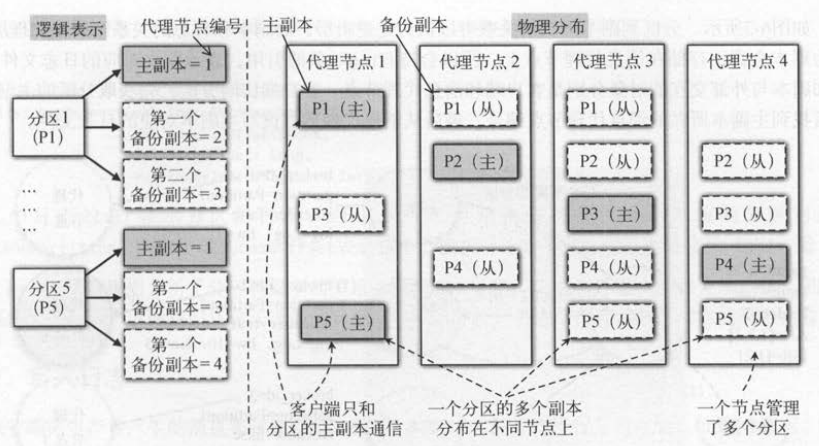
为了保证消息的可用性,每个分区会有多个副本 。 下面先从逻辑意义上理解Kafka分区和副本的关系,再从物理上理解分区在Kafka代理节点上的存储形式。
分区、副本、日志、日志分段
为了理解Kafka分区的概念,以HDFS分布式文件系统为例进行对比 。 如下表所示, HDFS的文件以数据块的形式存储在多个数据节点上,
名称节点保存了文件和数据块的对应关系 。 Kafka的主题以分区的形式存储在多个代理节点上, ZK记录了主题和分区的对应关系 。
Kafka一个主题的所有消息以分区的方式,分布式地存储在多个节点上 。 主题的分区数量一般比集群的消息代理节点多,而且实际运用时会根据不同的业
务逻辑,不同的消息按照不同的主题进行分类 。 反过来从消息代理节点到分区的角度看,集群的每一个代理节点都会管理多个主题的多个分区 。
Kafka主题的消息分布在不同节点的不同分区上,客户端以分区作为最小的处理单位生产或消费消息 。 以消费者消费消息为例,主题的分区数设置得越多,
就可以启动越多的消费者线程。 消费者数量越多,消息的处理性能就越好,消息就可以更快地被消费者处理,消息的延迟就越低。
主题的分区保存在消息代理节点上,当消息代理节点挂掉后,为了保证分区的可用性, Kafka采用副本机制为一个分区备份多个副本。一个分区只有一个主
副本( Leader ),其他副本叫作备份副本(Follower )。 主副本负责客户端的读和写,备份副本负责向主副本拉取数据,以便和主剧本的数据同步 。
当主副本挂掉后, Kafka会在备份副本中选择一个作为主副本,继续为客户端提供读写服务 。
如下图(左)所示,分区从逻辑上分成一个主副本(图中灰色背最)和多个备份副本 。 每个分区都有唯一的分区编号,比如,分区 1用P1表示,分区5用 P5表示 。
如下图 (右)所示,分区从物理上来看,所有的副本分布在不同的消息代理节点上 。 每个副本的编号表示所在的消息代理节点编号 。 比如, P1的第一个副本
编号是2 ,表示这个备份副本在编号为2的消息代理节点上 。
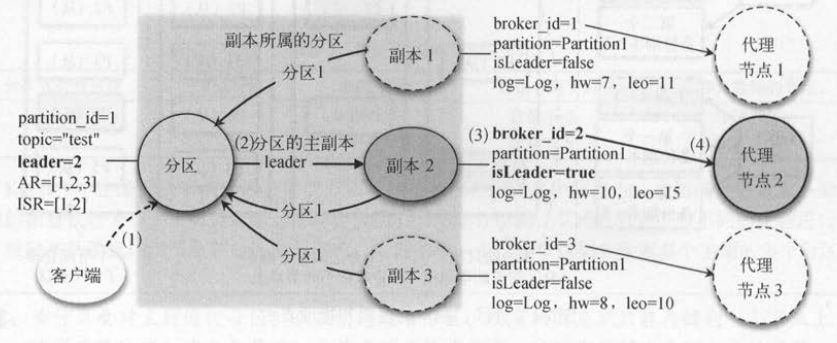
为了进一步理解分区和副本的关系,下面两段代码列举了分区类( Partition )和副本类( Replica )的成员变量: 
分区类的变量partition_id表示分区的编号,副本类的broker_i.d表示副本所在代理节点的编号,partition表示所属的分区对象引用 。 分区有一个主副本的
引用( leader ),副本有一个日志文件的引用( log )。
分区还有两个副本集构成的AR ( Assigned Replica )和ISR ( In-Sync Replica )。 AR表示分区的所有副本, ISR表示和主副本处于同步的所有副本,
也叫作“正在同步的副本” 。 如果副本超出同步范围,就叫作Out-Sync Replica。
如下图 所示,分区到副本的映射关系可以认为是逻辑层,而副本和日志的关系则属于物理层面。因为副本会真正存储在消息代理节点上,所以会持有
Log对象的引用,表示副本对应的日志文件 。 分区和副本与外部交互的对象分别是客户端和消息代理节点 。 客户端访问分区,先获取分区的主副本,
然后找到主副本所在的消息代理节点编号,最后从消息代理节点读写主副本对应的日志文件。
分区的每个副本存储在不同的消息代理节点上,每个副本都对应一个日志。 在将分区存储到底层文件系统上时,每个分区对应一个目录,
分区目录下有多个日志分段( LogSegment )。 同一个目录下,所有的日志分段都属于同一个分区 。
每个日志分段在物理上 由一个数据文件和l一个索引文件组成 。 数据文件存储的是消息的真正内容,索引文件存储的是数据文件的索引信息 。
为数据文件建立索引文件的目的是更快地访问数据文件。
写入日志
服务端将生产者产生的消息集存储到日志文件,要考虑对消息集进行分段存储。 如下图 所示,服务端将消息追加到日志文件,
并不是直接写入底层的文件,具体步骤如下 。
(1) 每个分区对应的日志对象管理了分区的所有日志分段 。
(2) 将消息集追加到当前活动的日志分段,任何时刻,都只会有一个活动的日志分段 。
(3) 每个日志分段对应一个数据文件和索引文件,消息内容会追加到数据文件中 。
(4) 操作底层数据的接口是文件通道,消息集提供一个WriteFullyTo ()方法,参数是文件通道 。
(5) 消息集( ByteBufferMessageSet )的 WriteFullyTo ()方法,调用文件通道的Write ()方法 , 将底层包含消息
内容的字节缓冲区( ByteBuffer)写到文件通道中 。
(6) 字节缓冲区写到文件通道中,消息就持久化到日志分段对应的数据文件中了 。

1. 消息集
生产者发送消息时 ,会在客户端将属于同一个分区的一批消息,作为一个生产请求发送给服务端。 Java版本和I Scala版本的生产者
在客户端生成的消息集对象不一样 , Java版本的消息内容本身就是字节缓冲区( ByteBuffer ), Scala版本则是消息集( Message*)。
为了兼容两个版本,两者都要转换为底层是字节缓冲区的ByteBufferMessageSet对象。
消息集中的每条消息( Message )都会被分配一个相对偏移量,而每一批消息的相对偏移量都是从0开始的 。
生产者写到分区P1的第一批消息有4条消息 , 对应的偏移量是 [ 0,1,2,3 ]; 第二批消息有3条消息 , 对应的偏移量是 [ 0,1,2 ] 。
客户端每次发送给服务端的一批消息,它的字节缓冲区只属于这一批消息,字节缓冲区不是共亭的数据结构 。
消息集中的每条消息由 3部分组成 : 偏移量、 数据大小 、 消息 内容 。
消息集中每条消息的第一部分内容是偏移量。 Kafka存储消息时,会为每条消息都指定一个唯一的偏移量 。 同一个分区的所有日志分段,
它们的偏移量从0开始不断递增 。 不同分区的偏移量之间没有关系 , 所以说Kafka只保证同一个分区的消息有序性,但是不保证跨分区消息的有序性。
消息集中每条消息的第二部分是当前这条消息的长度 。 消息长度通常不固定,而且在读取文件时,客户端可能期望直接定位到指定的偏移量。
记录消息长度的好处是:如果不希望读取这条消息,只需要读取出消息民度这个字段的值然后跳过这些大小的字节 ,这样就可以定位到下
一条数据的起始位置。
第三部分是消息的具体内容,和消息集的第二部分类似,每条消息的键值之前也都会先记录键的长度和值的长度。
注意 : 消息格式是在客户端定义的,消息集在传给服务端之前,就用ByteBufferMessageSet封装好。 服务端接收的每个
分区消息、就是ByteBufferMessageSet。
消息集的WriteMessage ()方法将每条消息( Message )填充到字节缓冲区中, 冲区会暂存每个分区的一批消息 。 这个方法实际上是在
客户端调用的,填充消息时,会为这批消息设置从0开始递增的偏移量 。 如下图 (右)所示,在服务端调用文件通道的写方法时,才会将消息集
字节缓冲区的内容刷写到文件中 。

客户端创建消息集中每条消息的偏移量 ,都还只是相对于本批次消息集的偏移量。 每一批消息的偏移量都是从0开始的,显然这个偏移量
不能直接存储在日志文件中 。 对偏移量进行转换是在服务端进行的,客户端不需要做这个工作 。为了获取到消息真正的偏移量, 必须知道
存储在日志文件中“最近一条消息”的偏移量。 再追加一个有新消息的消息集时,这批消息的偏移量从 “最近一条偏移消息”开始 。
既然客户端消息的偏移量只是相对偏移量,都是从0开始的,为什么不在服务端计算消息偏移i量时直接设置?
比如我们知道消息有5条,客户端不传每条消息的偏移量,而是在服务端存储时,根据“最近的偏移量”,直接设置这5条消息的实际偏移量 。
实际上 , 客户端将消息填充到字节缓冲区时,消息的格式就已经确定下来了,只是偏移量的值还只是相对偏移量。
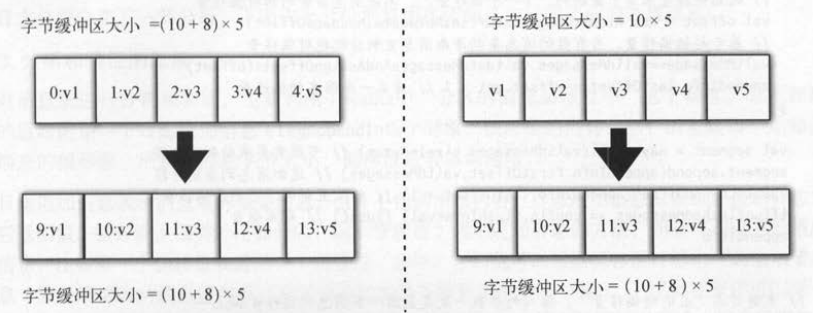
如下图(左)所示,服务端在存储消息时,可以直接修改字节缓冲区中每条消息的偏移量值,其他数据内容都不变,字节缓
冲区的大小也并不会发生变化。 而如下图 (右)所示,客户端填充消息到 字节缓冲区时没有写入相对偏移量。 服务端存储消息时,
由于最后要保存消息的偏移量,就需要在字节缓冲区每条消息的前面添加偏移量才行,这种方式会修改字节缓冲区的大小, 原来的字节缓冲区就
不能直接使用 了 。
2. 日志追加
服务端将每个分区的消息追加到日志中,是以日志分段为单位的 。 当日志分段累加的消息达到阈值大小(文件大小达到 1GB )时,会新创建一个
日志分段保存新的消息 ,而分区的消息总是追加到最新的日志分段中 。每个日志分段都有一个基准偏移量 ( segmentBaseOffset , 或者叫baseOffset ),
这个基准偏移址是分区级别的绝对偏移量,而且这个值在日志分段中是固定的 。 有了这个基准偏移量,就可以计算出每条消息在分区中的绝对偏移量,
最后把消息、以及对应的绝对偏移量写到日志文件中 。
日志追加方法中的messages参数是客户端创建的消息集,这里面的偏移量是相对偏移量。 在追加到日志分段时,
validMessages变量已经是绝对偏移量了 , 具体步骤如下 。
(1) 对客户端传递的消息集进行验证,确保每条消息的(相对)偏移量都是单调递增的 。
(2) 删除消息集中无效的消息 。 如果大小一致 ,直接返回 messages ,否则会进行截断 。
(3) 为有效消息集的每条消息分配(绝对)偏移量 。
(4) 将更新了偏移聋值的消息集追加到 当前日志分段中 。
(5) 更新日志的偏移量(下一个偏移量),必要时调用 flush ()方法刷写磁盘 。
读写操作发生在服务端处理生产请求和拉取请求,具体步骤如下 。
(1) 生产者发送消息集给服务端 , 服务端会将这一批消息追加到日志中。
(2) 每条消息需要指定绝对偏移量,服务端会用 nextOff setMetadata 的值作为起始偏移量 。
(3) 服务端将每条带有偏移量 的消息写入到日志分段中 。
(4) 服务端会获取这一批消息中最后一条消息的偏移量 ,加上一后更新 nextOffsetMetadata 。
(5) 消费线程(消费者或备份副本)会根据这个变量的最新值拉取消息 。一旦变量值发生变化 ,消费线程就能拉取到新写入的消息 。
nextOffsetMetadata变量是一个关于日志的偏移量元数据对象( LogOffsetMetadata ) 。
3 . 分析和验证消息集
对消息集进行分析和验证,主要利用了 Kafka中“分区的消息必须有序”这个特性。 分析和验证方法的返回值是一个日志追加信息( LogAppendinfo )对象 ,
该对象的内容包括 : 消息集第一条和最后一条消息的偏移量、消息集的总字节大小、偏移量是否单调递增 。
日志追加信息表示消息集的概要信息,但并不包括消息内容。 日志追加信息对象也是追加日志方法的最后返回值。服务端上层类(比如分区 、 副本管理器)
调用追加日志的方法 , 期望得到这一批消息的概要信息,比如第一个偏移量和最后一个偏移量。 这样,它们就可以根据偏移量计算出-共追加了多少
条消息(服务端接收的消息集和最后真正被追加的消息数量可能会不一样)。
消息集对象中消息的偏移量是从0开始的相对偏移量,并且它的底层是一个字节缓冲区 。
要获得消息集中第一条消息和最后一条消息的偏移量,只能再把字节缓冲区解析出来,读取每一条消息的偏移量。 这里因为还要对每条消息进行分析和验证,
所以读取消息是不可避免的 。
分析消息集的每条消息时,都会更新最近的偏移量( lastOffset ),但只会在分析第一条消息时更新起始偏移量( firstOffset )。
判断消息集中所有消息的偏移量是否单调递增,只需要比较最近的偏移量和当前消息的偏移量。如果每次处理一条消息时,
当前消息的偏移量都比最近的偏移量值(上一条消息的偏移量)大,说明消息集是单调递增的 。
4 . 为消息集分配绝对偏移量
如何在字节缓冲区中定位到每条消息的偏移量所在位置。 定位消息偏移量的方式有两种: 一种是按照顺序完整
地读取每条消息,这种方式代价比较大,我们实际上只需要更改偏移量,不需要读取每条消息的实际 内容;
另一种是先读取消息大小的值,然后计算下一条消息的起始偏移量,最后直接用字节缓冲区提供的定位方法( position() )直接定位到下一条消息的起始位置。
日志分段
同一个分区的所有日志分段中,所有消息的偏移量都是递增的 。Kafka消息代理节点上的一个主题分区( TopicPattion )对应一个日志( Log )。 每个日志有多个
日志分段( LogSegment ), 一个日志管理该分区的所有日志分段 。
一般会随消息的追加一直发生变化。 另外,因为消息追加到活动的日志分段,日志分段的大小( size )也会发生变化。 “日志分段的大小”会用来判断当前日志分段
是否达到阈值,如果达到阈值,日志就会创建一个新的日志分段,并把新创建的日志分段作为“当前活动的日志分段” 。
“下一个偏移量元数据”对象在追加消息过程中起到重要的作用,相关的步骤如下 。
(1)追加消息前,使用 nextOffsetMetadata 的消息偏移量,作为这一批消息的起始偏移量 。
(2)如果滚动创建了日志分段,当前活动的日志分段会指向新创建的日志分段 。
(3)追加消息后更新nextOffsetMetadata 的消息偏移量,作为下一批消息的起始偏移量 。
1. 日志的偏移量元数据
日志的偏移量元数据是日志的一个重要特征。客户端对消息的读写操作,都会用到日志的偏移量信息。 如下图所示,写入消息集到日志,日志的“下一个偏移量”
( nextOffset )会作为消息集的“起始偏移量”。从日志读取消息时,不能超过日志的“结束偏移量”( logEndOffset )或“最高水位”( highWaterMetadata )。
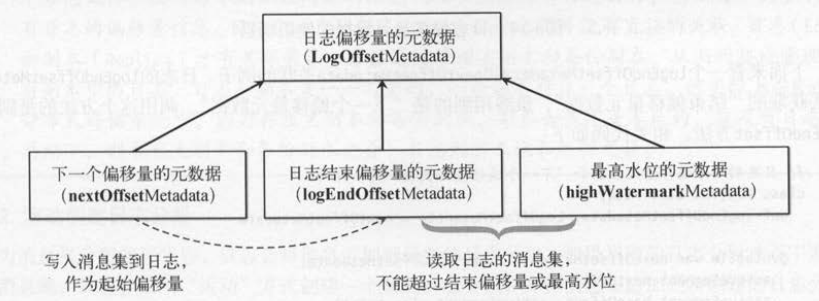
日志的偏移量结构包括 3部分:消息的偏移量( messageOffset )、日志分段的基准偏移量( segmentBaseOffset )、
消息在日志分段中的物理位置( relatlvePositionlnSegment ),其中后两者不一定会有值。
2 . 滚动创建日志分段
为消息集分配偏移量后,日志会将消息追加到最新的日志分段。 如果当前的日志分段放不下新追加的消息集,日志会采用“滚动”方式创建一个新的日志分段 ,
并将消息集追加到新创建的日志分段中 。
判断是否需要创建新的日志分段,有下面3个条件。
- 当前日志分段的大小加上消息大小超过日志分段的阈值( log.segment. bytes配置项) 。
- 离上次创建日志分段的时间到达一定需要滚动的时间( log.roll.hours配置项) 。
- 索引文件满了 。日志分段由数据文件和索引文件组成,第一个条件是数据文件满了, 会创建新的日志分段;这里的第三个条件是索引文件满了,
也会创建新的日志分段。
新创建日志分段的基准偏移量取自 logEndOffset ,实际上是 nextOffsetMetadata的消息偏移量值( messageOffset ),也是当前活动日志分段的下一个偏
移量值( nextOffset )。假设已经有两个日志分段,第三个日志分段初始时nextOffsetMetadata的下一个偏移量等于 10 ,基准偏移量等于 10 。 客户端发送多
批消息集,服务端的处理步骤如下 。
(1)第一批消息有 3条消息,追加到第三个日志分段,下一个偏移量改为 13 ,基准偏移量仍是 10 。
(2)第二批消息有 5条消息,追加到第三个日志分段,下一个偏移量改为 18 ,基准偏移盘仍是 10 。
(3)第二批消息、有2条消息,追加到第三个日志分段,下一个偏移量改为 20 ,基准偏移量仍是 10 。
(4)第四批消息有 10条消息,当前活动的日志分段即第三个日志分段放不下这 10条消息 。 满足滚动条件,创建第四个日志分段。 第四个日志分段的下一个偏移量
初始时为20 ,基准偏移量也是20 。 当新创建的日志分段加入到 segments后,当前活动的日志分段会指向新创建的日志分段。 第四批的 10条
消息就会追加到第四个日志分段。
消息集追加到已有的日志分段或者新创建的日志分段,每个日志分段由数据文件和索引文件组成。 数据文件的实现类是文件消息集( FileMessageSet ),它
保存了消息集的具体内容 。 索引文件的实现类是偏移量索引( Offsetindex ) , 它保存了消息偏移量到物理位置的索引 。
3. 数据文件
追加一批消息到日志分段 , 每次都会写到对应的数据文件中,同时间隔indexlntervalBytes大小才写入一条索引条目到索引 文件中 。 假设一条消息占用 10字节,
每隔 100字节才会写入一个索引条目,即 10条消息才会写入一个索引条目 。 如果一批消息有500字节 , 因为只会调用一次日志分段的 append()
方法,所以最多也只会创建一个索引条目 。
消息集( ByteBufferMessageSet )写入到数据文件( FileMessageSet ),实际上是要将消息集中的字节缓冲区( ByteBuffer)写入到数据文件的
文件通道中( FileChannel )。
消息集存储到日志分段中只是简单的追加 。 但要查询指定偏移量的消息,如果一条条查询就太慢了,而建立索引文件的目的就是:快速定位指定偏移
量消息在数据文件中的物理位置。
4 . 索引文件
为数据文件建立索引文件的基本思路是:建立 “消息绝对偏移量”到“消息在数据文件中的物理位置”的映射关系 。 索引文件的存储结构有下面3种形式 。
索引文件的存储结构有下面3种形式 。
- 为每条消息都存储这样的对应关系: “消息的绝对偏移量”到“消息在数据文件中的物理位置” 。
- 以稀疏的方式存储部分消息的绝对偏移到物理位置的对应关系,减少内存占用 。
- 将绝对偏移量改用相对偏移量,进一步减少内存的占用 。
Kafka的索引文件采用第三种形式,具有以下特性 。
- 索引文件映射偏移量到文件的物理位置,它不会对每条消息都建立索引,所以是稀疏的 。
- 索引条目的偏移量存储的是相对于“基准偏移量”的“相对偏移量” ,不是消息的“绝对偏移量” 。
- 索引条目的“相对偏移量”和物理位置各自占用4字节,即 1个索引条目占用 8字节 。
- 消息集的“消息绝对偏移量”占用 8字节,索引文件的“相对偏移量”只占用4字节 。
- 消息集8字节的“消息绝对偏移量”减去 8字节的“基准偏移量”,结果是4字节 。
- 偏移量是有序的,查询指定的偏移量时,使用二分查找可以快速确定偏移量的位置 。
- 指定偏移量如果在索引文件中不存在,可以找到小于等于指定偏移量的最大偏移量 。
- 稀疏索引可以通过内存映射方式,将整个索引文件都放入内存,加快偏移量的查询 。
索引文件通常比较小,可以直接放入内存 。
日志分段如果需要添加索引条目到索引文件,会先添加索引条目,然后才开始追加消息集到数据文件。
读取日志
客户端读取主副本的过程又叫作“拉取”,拉取主副本的消息集 , 一定会指定拉取偏移量。 服务端处理客户端的拉取请求,
就会返回从这个位置开始读取的消息集 。 另外,客户端还会指定拉取的数据量( fetchSize ),这个值默认是Max .partition.fetch.bytes配置项,大小为 1 MB 。
一个分区对应的日志管理了所有的日志分段,日志保存了基准偏移量和日志分段的映射关系 。 给定一个偏移量,要读取从指定位置开始的消息集,
最多i卖取fetchSize字节。 因为fetchSize默认大小只有 1 MB ,而日志分段对应的数据文件大小默认有 1GB ,所以通常来说服务端读取日志时,没有必
要读取所有的日志分段,只需要选择其中的一个分段,就可以满足客户端的一次拉取请求。
日志分段的选择要参考客户端设置的起始偏移量 。
读取日志分段时,要先读取索引文件再读取数据文件,不应该直接读取数据文件,具体步骤如下 。
(1)根据起始偏移量( starOffset )读取索引文件中对应的物理位置 。
(2)查找索引文件最后返回:起始偏移量对应的最近物理位置( starPosition )。
(3)根据起始位置直接定位到数据文件,然后开始读取数据文件的消息 。
(4)最多只能读取到数据文件的结束位置( maxPosition )。
1. 读取日志分段
日志分段的 log引用指的是文件消息集( FileMessageSet ),而不是日志对象( Log )。 文件消息集的读取方法会根据传人的开始位置和读取长度,
构造一个新的文件消息集对象。 读取文件的一般做法是:定位到指定的位置,读取出指定长度的数据,并且借助字节缓冲区来保存读取出来的数据。
而这里读取出来后还要用对象来表示,所以直接创建新的文件消息集,类似于一个视图对象。
2. 查找索引文件
3. 搜索数据文件
4 . 文件消息集视图
文件消息集是数据文件的实现类, 这个类除了文件、文件通道外,还有两个代表文件位置的变量:开始位置( start )和结束位置( end )。
文件消息集的读取方法根据起始位置和读取大小,创建一个新的文件消息集视图 。 每次调用读取方法,都会生成一个新的文件消息集对象 。
我们仅在服务端处理客户端的拉取请求时才会调用消息集的读取方法。
如果客户端的拉取请求读取的是同一个日志分段( 一个日志分段够客户端的拉取请求读取很多次),数据文件是同一个,说明同一个文件消息集
会调用多次读取方法 。 虽然读取方法新创建的文件消息集视图每次都不同,但所有的文件消息集都共用同一个文件和文件通道。 为了区分不同的文件消
息集,我们把和日志分段相关的文件消息集叫作“原始文件消息集”,调用“原始文件消息集”读取方法创建的新文件消息集叫作“文件消息集视图” 。
“原始文件消息集”的起始位置为0 ,结束位置为无限大,而且它们都不会变化。 但读取方法创建的“文件消息集视图”,它们的起始和结束位置则是变化的 。
如下图所示,服务端读取日志分段创建了新消息集,并将消息集发送给客户端,具体步骤如下 。
(1)日志分段新创建数据文件,文件和文件通道会用来创建一个文件消息集对象(原始文件消息
(2) 每次读取日志分段,都会调用原始消息集的读取方法 。
(3)原始消息集的每也读取方法,都会