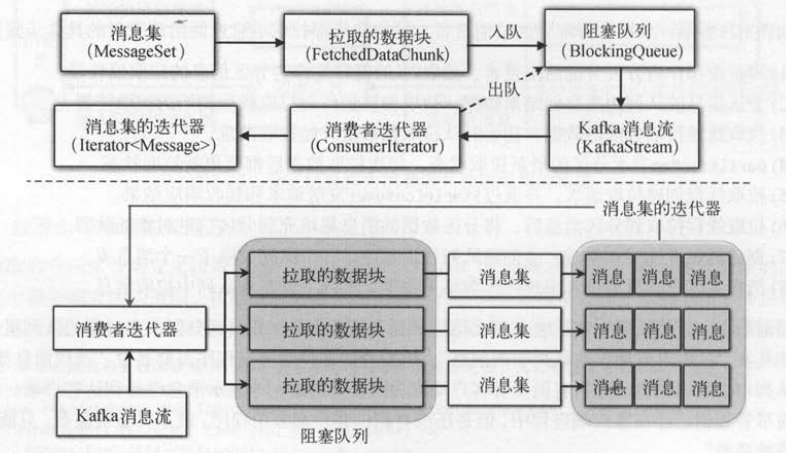
消费者拉取钱程拉取每个分区的数据,会将分区的消息集包装成一个数据块( FetchedDataChunk )放入分区信息的队列中 。 而每个队列都对应一个消息流( KafkaStream ),
消费者客户端选代消息流,实际上是迭代每个数据块中消息集的每条消息 。
一个队列包含多个数据块,每个数据块对应一个分区的消息集, 一个消息集包含多条消息 。 消费者迭代器( ConsumerIterator)封装了迭代获取消息的逻辑,
客户端不需要面向数据块、消息集这些内部对象,只需要对消费者迭代器循环获取消息即可 。
消费者迭代消费消息
消费者迭代器生成包含消息的迭代器,首先弹出队列的每个数据块,然后获取数据块对应的消息集,最后迭代消息集中的每条消息 。
客户端迭代的消息是队列的所有数据块,而不是一个数据块。 所以在迭代过程中,要确保读取完一个数据块后,接着读取下一个数据块。 也就是说,消费者迭代器是:
所有数据块通过消息集组成的消息迭代器。
消费者的“拉取线程” 拉取消息后会更新“拉取状态 ” ,对应的 “消费线程”获取消息后也要更新相关的“消费状态” 。 拉取状态对应分区信息、
对象的拉取偏移量( fetchedOffset ) , 表示消费者已经拉取的分区位置 ; 消费状态对应了消费偏移量( consul'ledOffset ),表示消费者已经消费完成的偏移量 。
如 下图 所示 , 拉取消息的线程和消费消息 的线程是两个独立的工作模块,前者通过分区信息对象的阻塞队列将消息传给消费消息的线程完成数据的传输 。
消息拉取后只有被消费线程真正消费后,才会更新消费状态 。 也就是说,“拉取线程更新拉取偏移量,消费线程更新消费偏移量”,具体步骤如下 。
(1) 消费者的拉取线程从服务端拉取分区的消息 。
(2)拉取到分区消息后 ,就更新分区信息对象的拉取偏移量 。
(3)将分区数据的消息集封装成数据块 。
(4)客户端循环迭代数据块的消息集 。
(5)消费完一条消息后,就更新分区信息对象的消费偏移量 。
(6)消息流中的每一条消息返回给消费者客户端应用程序 。 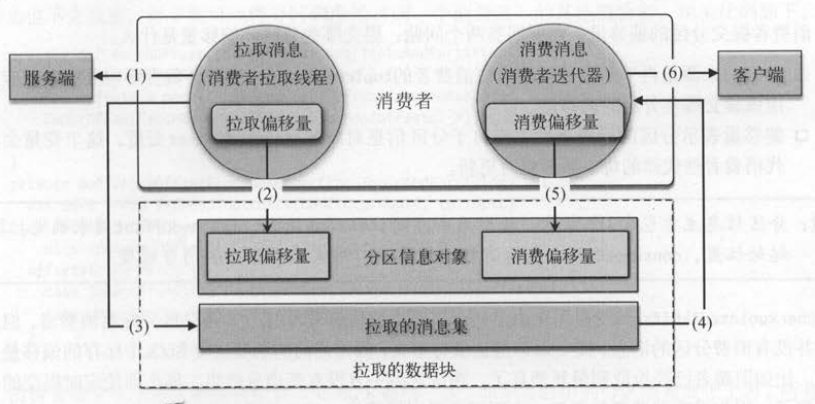
分区信息的拉取偏移初始时从ZK读取,然后在拉取消息后更新 。 同样,消费偏移量初始时也是从ZK读取,然后在消费消息后更新。
消费者消费了新的消息后,还应该及时地将消费进度(即分区信息的消费偏移量)保存到ZK中 。
消费者提交分区偏移量
消费者提交偏移量是为了保存分区的消费进度 。 因为Kafka保证同一个分区只会分配给消费组中的唯一消费者,所以即使发生再平衡后,
分区和消费者的所有权关系发生变化,新消费者也可以接着上一个消费者记录的偏移盘位置继续消费消息 。
但是消费者即使记录了分区的偏移量,仍然无法解决消息被重复消费的问题。 例如,消费者每隔 10秒提交一次偏移量,在 10秒时提交的偏移量是 100 ,
下一次提交的时间点是20秒。 在20秒之前,消费者又消费了 30条消息,然后消费者突然挂掉了 。 由于偏移量现在仍然停留在 10。这个位置,因
此新的消费者2也只会从 10。这个位置继续消费,从而会重复处理偏移量为 100之后的30条消息 。
通常消息被重复处理是可以接受的,至少不会出现消息丢失这种不可接受的问题。 定时提交偏移量的周期时间越长,消息被重复消费的数据量就越多。
客户端可以将这个周期时间设置得更短,来减少重复消费的消息量。 当然也不能太短,否则会导致客户端和保存偏移量的存储系统产生大量的网络
请求 。
在旧版本中每个分区的偏移量都保存到ZK中,每个分区都要和ZK产生一次交互,况且还要周期性地写入,这对ZK来说是个不小的负担。
在新版本中把偏移量像普通消息一样写入Kafka集群的内部主题。 而且正像消息会源源不断地写到集群一样,记录偏移量也是周期性的 。 Kafka支持高吞吐量的
消息写入,对于偏移量的记录当然也不在话下 。 下面我们会分析两个版本的提交偏移量过程 。
提交偏移量到ZK
消费者提交分区的偏移量 , 需要回答两个问题 : 提交哪些分区、偏移量是什么 。
分区 的来源是再平衡后分配给当前消费者的 topicRegistry , 消费者负责哪些分区,相应地就应该提交哪些分区的偏移量 。
偏移量 表示分区 的消费进度,来自于分区信息对象的 consumedOffset变量,这个变量会在迭代消费者迭代器的每一条消息时更新。
数据有写入就有读取,从ZK中读取偏移量需要指定要读取哪个分区。 注意 , 虽然是由消费者对分区的偏移量进行读写操作, 但是分区对应的ZK节点并没有消费者信息 。
ZK节点的路径中只有消费者所属的组 :/consumers/[group_id]/offsets/[topic]/[partition_id ] 。 提交分区偏移量以“消费组” 为级别,而不是让每个消费者自己维护分区偏移量
目的是 :即使某个消费者挂掉 , 分区偏移量代表的含义也不会改变,再平衡可以将分区调度给“ 同一个消费组” 的其他消费者。
提交偏移量到内部主题
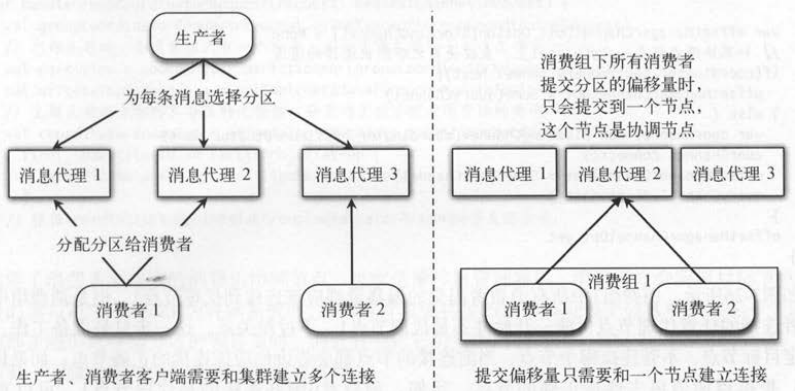
消费者提交偏移量到Kafka的 内部主题,首先要确定连接哪个或者哪些服务端节点 。 生产者发送消息时会根据分区的主副本分组和多个节点者都建立连接 ;
消费者分配多个分区 ,也要根据分区的主副本分组, 和多个节点建立连接。 而消费者提交所有分区 的偏移量时, 实际上只和一个服务端节点建立连接。
同样要处理多个分区,为什么普通消息需要多个连接,而偏移量只需要一个连接?
如下图 所示,目标节点指的是分区的主副本节点,我们给 出了偏移量的多种连接方案 。
(1)如果不同分区的偏移量写到了不同的节点,消费者分配了多个分区,当要读取不同分区的偏移量时,就得连接不同的节点才可以获得完整的数据。
(2)如果能让所有分区的偏移量数据只保存在一个节点,消费者就只需要同一个节点通信 。 但因为消费者和分区的关系是变化的,
即使保证这一次分区在一个节点上, 也无法保证下一次仍然在同一个节点 。
(3)如果消费组所有消费者所有分区的偏移量都保存在一个节点,就可以解决第二种方式的 问题 。
(4)消费者 的分区偏移量要保存在哪个节点,跟消费者所属 的消费组有关系 。 只要保证消费组级别的偏移量在一个节点上,
即使消费者和分区的关系发生变化 , 也能够保证消费者访问新分配的分区时 , 只需要访问一个节点 。
同一个消费组的所有消费者,以内部主题形式提交所有分区的偏移盘到一个目标节点,这个内部主题和普通消息的主题一样也会有多个分区。
如果只有一个分区 ,所有消费组都只能提交到唯一的节点,就又退化到和ZK面临的将所有读写请求都压到一个节点的相同问题。 而如果有多个分区,并且以消费组
作为分区的分布条件,不同消费组提交到的偏移量有可能是不同的节点,就可以分散偏移盘读写的压力 。
实际上,消费者提交偏移量如果存储在ZK中,也是用消费组级别来表示 。 存储在ZK中天生就具有共享存储的优势,所有的消费者只需要连接ZK即可 。
而以主题方式存储偏移量时,就得考虑是否需要连接多个服务端节点 。 每个消费组只连接一个节点是最好的,这个节点负责管理一个消费组所有消
费者所有分区的偏移量, 叫作偏移量管理器( OffsetManager)。 和采用ZK方式将偏移量数据写到ZK不同,消费者将偏移量数据封装成偏移量提
交请求( OffsetCommitRequest )发送给偏移量管理器。 就像生产者的生产请求、消费者的拉取请求一样,偏移量提交请求和偏移拉获取请求都是发
送给Kafka服务端节点的 。
如下图 所示,总结一下目前为止客户端需要确定服务端节点的几个场景
- 生产者发送消息时,直接在客户端决定消息要发送给哪个分区,这一步不向服务端发送请求 。
- 消费者拉取管理器的 LeaderFinderThread线程向服务端发送主题元数据请求,获取包含了主副本等信息的所有分区元数据,
消费者拉取线程才能确定要连接哪些服务端节点 。
- 提交偏移量虽然有点像生产者的发送消息,都是写数据,但也需要和消费者的 LeaderFinderThread一样,获取分区的主副本作为偏移量管理器,
才能确定提交到哪个节点 。
连接偏移量管理器
前面分析的拉取偏移量方法和提交偏移量方法,都需要和偏移量管理器通信。 在这之前,消费者需要通过 channelToOffsetManager()方法
向服务端任意一个节点发送“消费组的协调者请求”( GroupCoordinatorRequest ),来获取消费组对应的协调节点 ,即偏移量管理器( OffsetManager )节点 。
服务端处理消费组的协调者请求,实际上也是通过查询主题的元数据来完成的 。 不过和LeaderFinderThread 中返回主题元数据,
然后还要在客户端继续处理( 比如获取存在主副本的分区)不同,这里在服务端完成“选择消费组对应内部主题的分区的主副本节点”,
然后直接返回这个协调节点给客户端。 也就是说客户端发送消费组的协调者请求,服务端返回的就是消费组的协调节点 。
消费组1中所有消费者提交的偏移量都应该连接到代理节点1 ,但是消费组中不同消费者连接的任意代理节点可能一开始并不是代理节点1。
不过没关系,这一步只是准备工作,目的是确定目标节点,不管连接哪个节点,当前连接的节点都会告诉你应该连接的正确节点 ;如果你连得
不对,根据返回值再去连接正确的节点 。 比如,消费者0刚好连接的是代理节点1 ,可以直接把queryChannel作为offsetChannel ;
而消费者1 和消费者2第一次连接的不是代理节点 1 , 所以在得到结果时应该首先关闭 queryChannel ,然后重新连接代理节点 1
作为queryChannel 。
任何一个服务端节点处理消费者发送的GroupCoordinator请求 , 首先要确定消费组在内部主题的分区,然后,从主题元数据的所有分区元数据中
找出指定分区的主副本节点 , 就是消费组对应的协调者节点 。 在 LeaderFinderThread 中直接返回主题的元数据,是因为无法确定具体的分区,而这里根据
消费组可以确定分区,所以直接在服务端返回对应分区的主副本信息 。
确定了消费者要连接的消费组协调节点,也就是偏移量管理器后,消费者才会向该目标节点发送偏移量的读写请求 。在以ZK为存储系统时,
消费者针对偏移量的读写都是每个分区单独发起一个请求 。在以内部主题形式存储分区的偏移量时 ,消费者会把它负责的所有分区一次性发送给协调节点 。 现在
我们来看一下服务端对偏移业请求的处理过程 。
服务端处理提交偏移量的请求
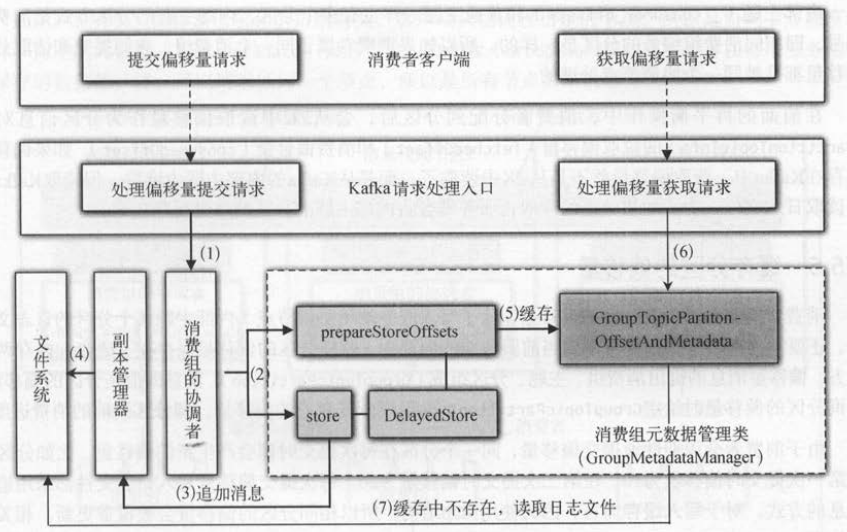
协调节点会将消费者的所有分区消费进度偏移量请求消息集追加到本地日志文件,并且会把分区和对应的偏移量保存在协调节点的缓存中 。
目的是:再平衡后如果其他消费者需要读取分区的偏移量, 在连接上协调节点后,可以直接读取缓存 , 而不需要从日志文件中读取。
如下图 所示 , 消费者发送提交偏移量和获取偏移量都会被服务端的 KafkaApis处理,服务端处理这两个请求的具体步骤如下 。
(1 ) KafkaApis将提交偏移量请求的处理交给消费组的协调者( GroupCoordinator )。
(2)消费组的协调者再交给消费组的元数据管理类( GroupMetadataManager )去处理 。
(3)延迟的存储对象( DelayedStore )会调用副本管理器的 appendMessages ()存储消息 。
(4)副本管理器将消息追加到底层文件系统的日志文件中,这样分区的偏移量就抒储到服务端了 。
(5)分区和l对应的偏移量会在消息存储成功后,被缓存至服务端的消费组元数据管理类 。
(6)服务端处理客户端的获取分区偏移量请求 , 会首先从缓存中获取 。
(7)如果缓存中没有分区的偏移量 , 就从日志文件中读取 。
如下图 所示 , 我们用一个示例说明消费者提交偏移量的过程,具体步骤如下 。
(1)消费者分配到分区, 比如消费者 1(C1)分配到主题( test1)的分区 P0和分区 P1 。
(2)分区 P0 的主副本是消息代理节点 1 ( Broker1),分区 P1的主副本是消息代理节点 2 ( Broker2 ),消费者创建拉取线程拉取分区消息 。
(3)消费者拉取到每个分区的消息后,客户端迭代每条消息,会更新分区信息对象的消费进度 。
(4)消费者定时提交分区偏移量 , 连接消费组的协调节点,消费组1对应内部主题的 P1即Broker2 。
(5)消费者1将向己负责的分区(即P0和 P1 )偏移量提交到协调节点Broker2上 。
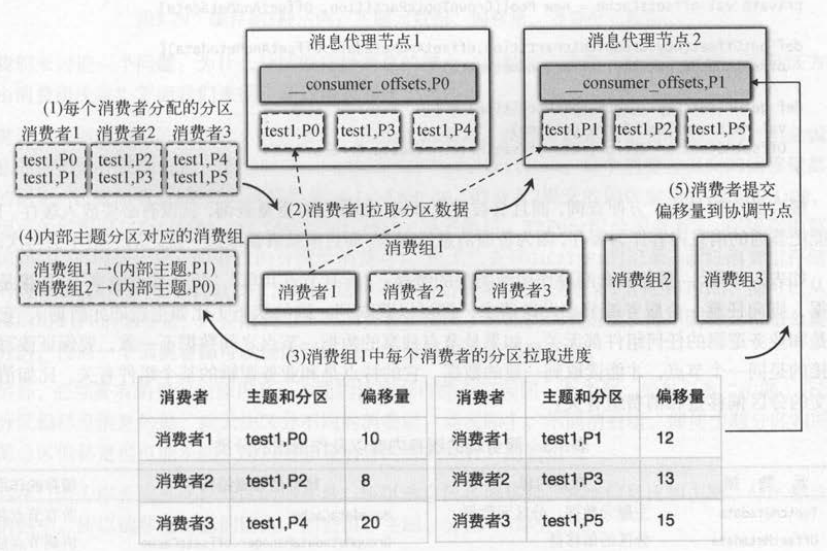
内部主题( _consumer_offsets )和普通主题一样也有多个分区,内部主题的分区方式是消费组编号,即相同消费组编号的分区是一样的 。
所以如果消费者属于同一个消费组 , 它们提交和读取分区偏移量都是被同一个协调节点处理的 。在前面的再平衡操作中 ,
消费者分配到分区后,会从 ZK 中读取偏移量作为分区信息对象( PartitionTopicinfo )的拉取偏移量( fetchedOffset )和消费偏移量( consumedOffset )。
如果偏移量保存在Kafka中,获取偏移量就不是从ZK中读取了,而是从Kafka的内部主题中读取。 但读取Kafka需
要读取日志文件,为了加快数据的读取,服务端会将内部主题的分区偏移盘缓存起来 。
缓存分区的偏移量
消费者提交自己负责分区的偏移量,除了写入服务端(协调节点)内部主题某个分区的日志文件中,还要把这部分数据保存一份到当前服务端的内存中,
这样分区的偏移量保存在了磁盘和内存两个地方。偏移量消息的键由消费组、主题、分区组成( GroupTopicParttion ),消息的值是分区的偏移量 。
查询分区的偏移量时给定GroupTopicParttion , 会返回分区对应的偏移量, 即分区当前的消费进度 。
由于消费者会周期性地提交偏移量,同一个分区在每次提交时都会产生新的偏移量。 比如分区p。在第一次提交时偏移量为 10 , 在第二次提交时偏移量为20。
每次提交偏移量写入日志文件都采用追加消息的方式 。 对于写入缓存而言,因为使用Map结构,所以相同分区的偏移量会被覆盖更新。
缓存的作用是为了方便查询, 而且会被重复查询,如果没有重复查询,就没有必要放入缓存。 比如,不能把普通的消息内容作为缓存,因为普通消息量很大,
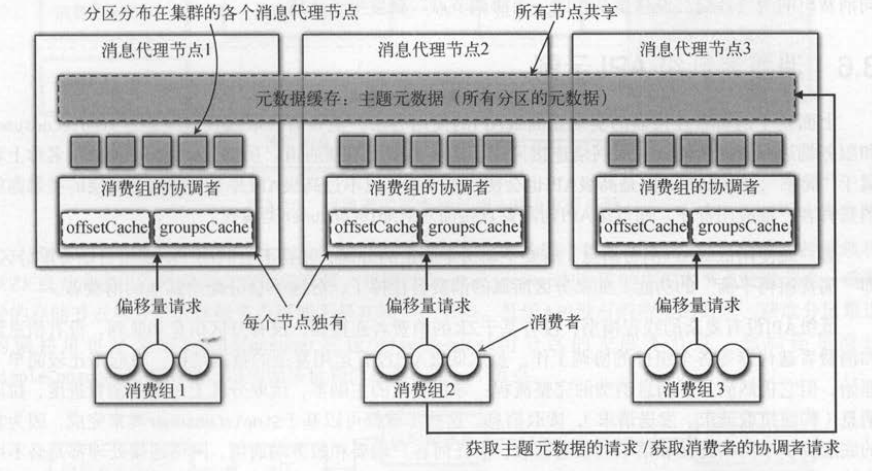
而且消费者读取过一次之后一般不会再次读取。如下表所示,服务端有两种作用域类型的缓存:“所有节点共享”“每个节点独享” 。 如果是共享
数据, 则向任意一个服务端节点发送请求,都可以获取到一致的状态(比如主题的元数据) , 它的特点是和业务逻辑的任何组件都无关。
如果是节点独享的数据,节点之间数据不一致,要保证读写请求连接的是同一个节点,才能读取到一致的数据。它的特点是和业务逻辑的某个组件有关,
比如消费者提交的分区偏移量和消费组有关。

如下图所示 ,偏移量请求和消费组有关,客户端只能连接指定的节点,所以是协调节点独享的缓存。 而主题元数据( TopicMetadata )和消费组的协调者( GroupCoordinator )
因为在每个服务端节点保存的数据都一样,可以请求任何一个节点,所以是所有节点共享的缓存。
我们来讨论一个问题:为什么分区偏移量消息的键由“消费组 、 主题 、 分区”组成,而分区方式却只由消费组决定?下面我们来循序渐进地回答这个问题。
首先,要回答消息的键为什么有消费组,而没有消费者 。 虽然分区是由消费者提交的,但是偏移量消息的键不能存在消费者。
假设键是GroupConsumerTopicPartition ,每个消费者提交的偏移量都有自己的标识。 比如消费者 1提交的偏移量是G1-C1-T1P0:10 ,
消费者2提交的偏移量是G1-C2-T1P1:20 ,保存到缓存的数据是 [ (G1C1T1P0, 10), (G1C2T1P1,20 )] 。 再平衡后, T1P0分配给消费者2 ,
在缓存中就不会查询至l]G1C2T1P0的记录;如果T1P1分配给消费者1 ,也无法查到G1C1T1P1的记录。 而以消费组存储时缓存的
内容是 [(G1T1P0, 10), (G1T1P1, 20)],这样不管是消费者1还是消费者2分配到T1P0 ,都可以从缓存中读取出 T1P0的偏移量。
只要消费组所有消费者都提交了分区的消费进度,再平衡时无论怎么重新分配分区,任何一个消费者都可以查询到任意一个分区的最新消费进度 。
另外,必须要有消费组的原因是,不同的消费组可能会订阅同一个主题。 如果只有“主题 、 分区”作为分区偏移量消息的键,就无法区分不同的消费组 。
而实际上,不同消费组,即使主题分区相同,它们的分区偏移盐也可能不同,所以偏移量消息的键需要有“消费组” 。
其次,因为服务端要保存分区的偏移量,所以消息值是偏移量,其他信息比如主题、分区都放在消息的健中 。 所以偏移量消息的键由“消费组、主题、分区” 3部分组成。
最后,再来看看为什么分区方式只由消费组决定的,而不是偏移量消息的键?因为同一个消费组 的分区偏移量消息都在同一个协调节点上,
为消息进行分区的方式只能是消费组 。 如果分区方式也是“消费组、主题、分区”,那么只有这3个数据都相同时,内部主题的分区才相同 。 比如G1T1P0和G1T1P1
因为分区不同, 内部主题的分区也不同,提交偏移量时就不在同一个协调节点了 。 而这和前面的“相同消费组的消费者提交偏移量是在同一个协调节点”就发生了矛盾。