消费者连接器通过再平衡操作分配到的分区相当于t作任务,任务需要由工作线程完成。 生产者要写消息到服务端的分区,这是通过Sender工作线程完成的,
消费者要读服务端分区的消息则通过拉取管理器的拉取线程完成。
拉取线程管理器
消费者的拉取管理器( ConsumerFetcherManager )管理了当前消费者的所有拉取线程,这些拉取线程会从服务端的分区拉取消息 。
Kafka的生产者和消费者都只能和分区的主副本通信,所以消费者再平衡后分配到分区信息,需要找到分区的主副本 。
拉取管理器会启动一个后台的 LeaderFinderThread线程 , 不断找出已经存在主副本的分区,被选中的分区会被加入对应的拉取线程 。
如下图 所示,消费者连接器触发ZKRebalancerListener监听器的再平衡操作,将分区信息传递给拉取管理类,后台线程会选中已经准
备好的分区交给不同的拉取线程,然后拉取线程才会真正开始工作 。
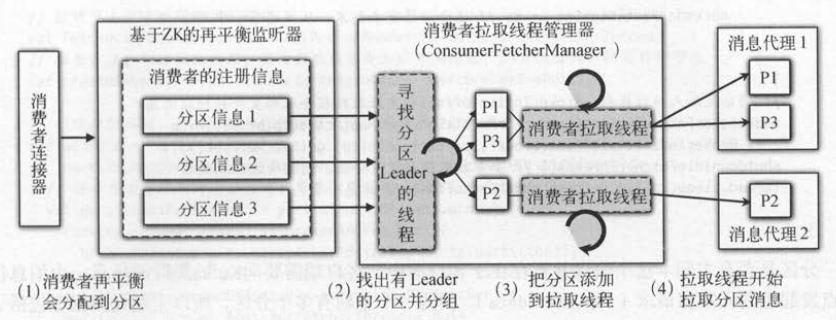
1 . 选择有主副本的分区
LeaderFinderThread后台线程是抽象拉取管理器( AbstractFetcherManage)的内部类,它的工作是找出已经有主副本的分区 。
初始时假设分配给消费者的所有分区( topicinfos )都找不到主副本,topicinfos会被加入候选集合( noleaderPartitions ,没有主副本的分区)中 。
后台线程每次运行时 ,只需要判断候选集合中的分区是存有主副本,如果找到有主副本的某个分区,就将这个分区从候选集合中移除 。 后台线程下一次运行时 ,
上次已经被选出并移除的分区就不会存在于候选集合,所以每个分区都只会有一次被加入拉取线程的机会,并不会被重复加入 。
拉取管理器的后台线程将有主副本的分区分配给拉取线程, 而拉取线程还需要知道分区的拉取位置才能正常作。 前面再平衡操作分配给
消费者的分区信息,会保存在拉取管理器的partitionMap变量中,分区信息中包含了拉取位置,所以可以从partitionMap中读取分区的拉取位置。
分区是否有主副本这个信息并不存在于客户端中,客户端需要向 Kafka集群的任意一个消息代理节点发起主题元数据请求(ToplcMetadata )。
因为一个主题有多个分区,所以主题元数据也包括了所有分区的元数据,这其中就有每个分区的主副本信息 。 有了分区的主副本后,拉取管理器会把属于同
一个主副本的不同分区分配给相同的拉取线程。
总结一下 。 后台线程找出有主副本的分区、 创建拉取线程、为拉取线程指定分区都是由拉取管理器完成的,因为只有管理器才有资格管理所有的线程。
拉取管理器管理所有的拉取线程,而每个拉取线程则管理自己的分区和偏移量,每个角色都各司其职。 拉取管理器不需要关心底层分区的偏移盘,
拉取线程向己会根据偏移量,执行分区的拉取任务 。
2. 创建拉取线程
客户端涉及和分区相关的工作线程,通常以消息代理节点为粒度,让一个线程管理这个消息代理节点上的多个分区 。 工作线程通常都是重量级的对象,
不适合每个分区都启动一个单独的线程,能够合并的分区尽量要放在同一工作线程中处理。
那么如何对所有分区进行分组,保证分组后同一组的所有分区都共用一个拉取线程?分组条件是BrokerAndFetcherId ,其中 Broker表示分区的主副本节点,
拉取编号 FetcherId 的计算方法是:对主题进行散列化加上分区编号的结果,再和线程数numFetchers进行取模。
Kafka 中有两种对象会拉取消息一一消费者和备份副本,拉取管理器也有对应 的两种实现 。 消费者管理器会创建消费者的拉取线程,副本管理器会创建副本的拉取线程。
因为拉取消息时必须知道从哪个目标节点上拉取。
消费者和备份副本的拉取线程都需要知道分区的偏移盐, 即在消费者再平衡时从ZK读取。。 而备份副本的偏移量并没有保存在ZK中 ,而是保存在备份副本的本地内存中 。
3. 拉取线程的拉取状态
消费者拉取管理器创建消费者拉取线程时,会把它持有的‘‘代表分配给当前消费者的页有分区信息”数据传递个每个拉取线程,因为分区信息对象中的队列会用来存放分区的
拉去结果,如果没有把分区信息传给每个拉取线程,拉取线程就无法获得其中的队列,就没有地方来存放拉取到的消息 ZKRebalancerListener将分区信息集合传给拉取管理器
(否则管理器也不知道它到底要拉取哪些分区),拉取管理器再把分区信息、集合传给每个拉取线程 。 
抽象拉取线程
抽象拉取线程定义了拉取工作的主要流程 , 拉取线程工作时,首先要确定数据源(即拉取状态),每次拉取到消息还要更新拉取状态,
确保下一次拉取请求时获得的拉取状态是最新的 。
1. 构建拉取请求
拉取管理器后台线程调用拉取线程的保存了每个分区的拉取状态 ( partitionMap)。 拉取线程的运行方法会根据拉取状态构建并处理拉取请求 。
2. 处理拉取请求
消费者和备份副本的拉取工作都一样,拉取线程向服务端拉取消息的步骤如下 。
(1) buildFetchRequest( partitionMap )根据保存的每个分区的拉取状态构建拉取请求 。
(2) fetch(fetchRequest )根据拉取请求向目标节点拉取消息,并返回响应结果 。
(3) processPartitionData(pa 「ti.ti.onData )处理拉取到的分区结果数据 。
每个拉取线程都在自己本地保存了当前负责所有分区的拉取状态,拉取线程每次在收到拉取请求的响应结果后,会用本次拉取消息集最后一条消息的偏移量来更新partitionMap ,
下一次会从上一次拉取的最后一个位置继续拉取。 这样就可以保证拉取线程的每一次拉取请求总是拉取新的消息集,而且不会重复 。 所以,除了第一次拉取请求获取拉取状态是从ZK读取,
后面的拉取请求都直接从partitionMap 中读取 。
消费者拉取线程
消费者拉取管理器在创建拉取线程时 , 会将表示分区及其分区信息对象的全局 partitionMap作为类级别的变量传给每个拉取线程,
但每个拉取线程在拉取时实际上只会负责一部分的分区 。 拉取线程在拉取到分区数据后,需要将拉取结果保存到分区信息的队列中 。
因为每个拉取线程都持有全局的partitionMap引 用,所以 processPartitionData ()方法在处理拉取结果时,可以获取到分区信息中的队
列,并将拉取结果填充到队列中 。
消费者拉取线程构建拉取请求后,通过SimpleConsumer代表和服务端的网络连接。 SimpleConsumer使用同步类型的阻塞通道发送请求和接收响应 。
消费者和备份副本的拉取线程采用了不同的方式和服务端建立网络连接。 
消费者和备份副本的拉取线程在收到拉取消息后处理方式不同,比如备份副本会把数据写到自己本地的日志文件中,消费者则会把数据填充到分区信息对象的队列
中供消费者客户端应用程序获取。
拉取出现错误的处理方式
拉取线程向服务端发送拉取请求如果收到OFFSET_OUT_OF_RANGE错误码表示拉取请求的拉取偏移量超出服务端分区的范围 , 拉取线程就要根据消费者设置的
重置策略设置拉取偏移盐,并且更新分区的拉取状态 。 下一次发送拉取请求时 ,拉取线程使用重置的偏移量拉取分区的消息 。
消费者拉取线程拉取消息过程中还可能遇到其他的错误,通常是分区的主副本发生变化,导致拉取线程不能再从之前的节点上读取数据。
此时,拉取线程会调用 handlePartitionsWithErrors()抽象方法进行处理。
首先,这个分区不应该继续拉取,所以要将其从拉取状态集合中移除,这样下次拉取请求就不会存在这个错误的分区了
然后,将分区加入到消费者拉取管理器的 noleaderPartitionset 中,
这样 LeaderFinderThread就会重新选择分区的主副本让拉取线程连接最新的节点 。
如下图所示,总结从分配分区给消费者,到拉取线程拉取消息返回给消费者的具体步骤如下。
(1)再平衡操作将分区分配给消费者,读取ZK的偏移量作为分区信息的拉取偏移量 。
(2)分区信息 的 队列用来存储结果数据,拉取偏移量作为拉取线程初始的拉取位置 。
(3)拉取线程拉取分区的数据,初始时从拉取偏移量开始拉取消息 。
(4 ) partitionMap表示分区的最新拉取状态,每次拉取数据后都要更新拉取状态 。
(5)拉取线程创建拉取请求,并通过 SimpleConsumer发送请求和接收响应结果 。
(6)拉取钱程拉取到分区消息后 , 将分区数据 的消息集填充到分区信息对象的 队列 。
(7)创建消费者连接对象时,会创建队列和消息流, 一个 队列关联了 一个消息流 。
(8)消费者客户端从消息流中迭代读取结果数据,实际上就是从队列中拉取消息 。
目前为止,虽然拉取线程从服务端成功拉取到了最新消息,并放到分区信息对象的队列里,但是客户端其实 “还没有开始读取队列中的消息” 。
消费者的客户端应用程序需要通过“迭代消息流” ,才能从队列中读取出消息 。 而只有消费者客户端成功消费到数据 , 才表示消息已经到达客户端。 否则在
这之前尽管数据已经在客户端进程中,但是还没有到达客户端应用程序,就不算做被消费,只能说“正在等待被消费” 。 