消费者再平衡操作
消费者连接器的核心处理逻辑是再平衡操作,它起了承上启下的作用。初始化消费者连接器只是“创建了队列和消息流”,再平衡操作会“为消费者重新分配分区” 。
只有为消费者分配了分区,拉取线程才会开始拉取分区的消息 。因为分区要被重新分配,分区的所有者都会发生变化 ,所以在还没有重新分配分区之前 ,
所有消费者都要停止已有的拉取钱程 。
分区分配给消费者都会在ZK中记录所有者信息,所以也要先删除ZK上的节点数据。 只有和分区相关的ZK所有者 、 拉取线程都释放了,才可以开始分配分区 。
再平衡操作的步骤如下 。
(1)关闭数据拉取线程,清空队列和消息流,提交偏移量 。
(2)释放分区的所有权,删除ZK中分区和消费者的所有者关系 。
(3)将所有分区重新分配给每个消费者,每个消费者都会分到不同的分区 。
(4)将分区对应的消费者所有者关系写入ZK , 记录分区的所有权信息 。
(5)重新启动消费者的拉取线程管理器,管理每个分区的拉取线程 。
拉取线程和分区所有权的关闭和开启顺序为 : 停止拉取钱程→释放分区的所有权→添加分区的所有权→启动拉取线程。
分区的所有权
分区的所有权记录在ZK的节点,表示“主题一分区”会被指定的消费者线程所消费,或者说分区被分配给消费者 、 消费者拥有
了分区 。 要释放分区的所有权,只需要删除分区对应的ZK节点;要重建分区的所有权,数据源中除了包含分区,还要有消费者线程编号 。
ZK中不仅记录了消费者和分区的所有权映射关系,而且记录了消费组的消费者列表、主题的分区列表,这些信息为消费者分配分区提供了数据来源 。
为消费者分配分区
每一个消费者都需要分配到分区才能拉取消息,当发生再平衡时消费者都会重新新分配分区 。 为了让每个消费者都能被分配到分区,
需要从ZK中查询出所有的分区以及所有的消费者成员列表 。分区要限定主题范围,消费者要限定消费组范围 。 对于触发再平衡的消费者而言,
它所属的消费组是确定的,而且订阅的主题和分区也是确定的,所以从ZK中获取订阅相同主题的消费者成员列表、包含相同主题的分区都没有问题。
如下图 所示,消费者1订阅了主题1和主题2 ,消费者2订阅了主题1和主题3 ,消费者3订阅了主题2和主题3 。当消费者发生再平衡时,
因为消费者1订阅了主题1 和主题2 ,而主题 1和主题2的订阅者有消费者1 、 消费者2 、消费者3 ,所以消费者2和消费者3也会一起发生再平衡。
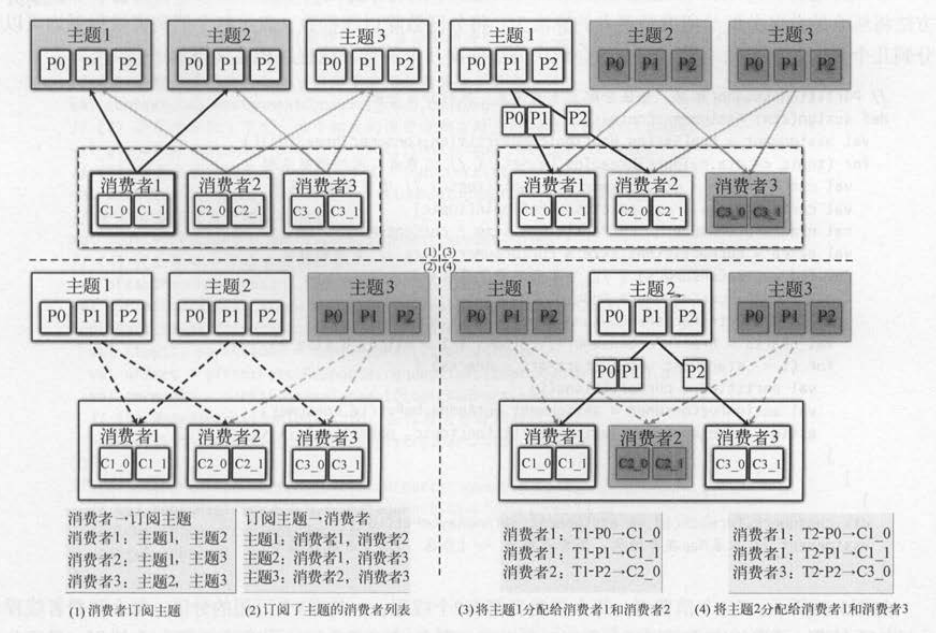
这个示例中我们并没有说明消费者 1发生再平衡操作的原因,有可能是消费者 1 的会话超时,或者消费者1刚加入消费组,或者消费者 1订阅的主题(主题1和主题2 )
分区发生变化。 也有可能是其他消费者发生再平衡 , 导致消费者 l也需要执行再平衡。
将所有的分区分配给所有消费者的算法为:将分区数除以线程数, 表示每个消费者线程平均可以分到几个分区 。 如果除不尽 ,剩余的会依次分给前面几个消费者线程。
如下图 所示,有2个消费者 , 每个消费者都有2个线程, 一共有5个可用的分区 。 每个消费者线程( 一共4个线程)都可以获取至少 1个分区( 5%4= 1 ) ,
剩余 1 个分区分给第一个线程 。 最后分区分配给各个消费者的结果为: P0→C1_0, P1→C1_0, P2→C1_ 1, P3→C2_0, P3→C2_1。 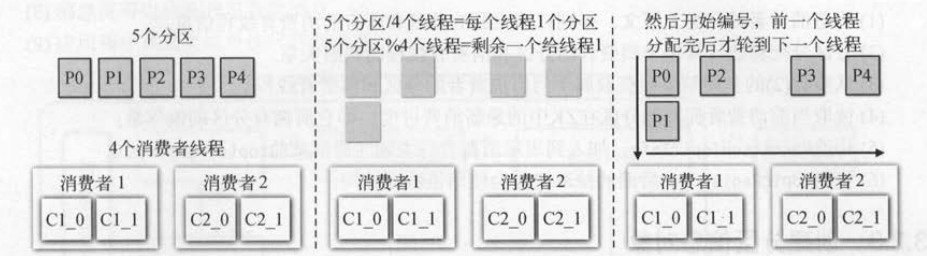
再平衡操作的基本条件是为当前消费者分配到分区,这样拉取线程才能知道要从哪里拉取消息 。分区的消费进度保存在ZK中 ,
所以也要读取ZK获取最新的偏移量 。 只有把这些工作都准备好,拉取线程才可以开始工作。
rebalance ()方法除了前面已经分析的所有权释放和添加 、拉取钱程的关闭和更新 , 剩下和分区分配相关的步骤如下 。
(1)构造消费者的分配上下文,得到订阅主题的分区和所有的消费者线程信息 。
(2) 分区分配算法计算每个消费者的分区和消费者线程的映射关系 。
(3)从步骤 (2 )的全局结果中获取属于当前消费者的分区和消费者线程 。
(4) 读取当前消费者拥有 的分区在ZK中的最新消费进度, 即它所拥有分 区 的偏移量 。
(5) 构造 PartitionToptcinfo, 加入到表示消费者的主题注册信息的 topicRegisty 中 。
(6) 更新 topicRegistry ,后面的拉取线程会使用该数据结构 。
创建分区信息对象
从ZK中读取出的分区的偏移量 , 会被用来构造分区信息对象( PartitionTopicinfo )。 分区信息对象的主要内容有 :分区 ,表示拉取线程的 “目标” ;
队列 ,作为消息的“存储”介质; 偏移量 , 作为拉取“状态” 。 消费者的拉取线程会以最新的 “状态”拉取“目标”的数据填充到“存储”队列中。
ZK的 offsetCouter是这个分区最近一次的消费偏移量 ,也是最新的拉取偏移量 。 消费者向服务端发起拉取数据请求时 ,拉取偏移量( fetchOffset )
表示要从哪里开始拉取。 消费者从服务端拉取消息写到本地后,消费偏移量( consumedOffset )表示消费到了哪里。
下图 总结了 队列从创建到填充数据,再到数据被消费的过程,具体步骤如下 。
(1)连接器根据订阅信息生成队列和消息流的映射,并且队列也会传给消息流 。
(2)为消费者分配分区时 ,会从ZK中读取分区消费到的最新位置 。
(3)根据偏移量创建分区信息, 队列也会传给分区信息对象 。
(4)分区信息被用于消费者的拉取线程 。
(5)拉取线程从服务端的分区拉取消息 。
(6)消费者拉取到消息后 , 会将最新的偏移量更新到ZK 。
(7)拉取线程将拉取到的消息填充到队列里 。
(8)消息流可以从队列里获取消息 。
(9)应用程序从消息流里迭代获取消息 。

分区信息和队列有关,那么它跟消费者客户端的线程模型也有关:一个消费者线程可以消费多个分区,而一个消费者线程对应一个队列,
所以一个队列可以保存多个分区的数据。 即对于不同的分区,可能会使用同一个队列来保存消费者拉取到的消息 。
比如,消费者设置了一个线程就只有一个队列,而分区分了两个给它,这样一个队列就要处理两个分区 。 如下图 (上)是分区信息中队列的数据来源
路线,图(下)展示了分区信息和客户端线程模型的关系 。
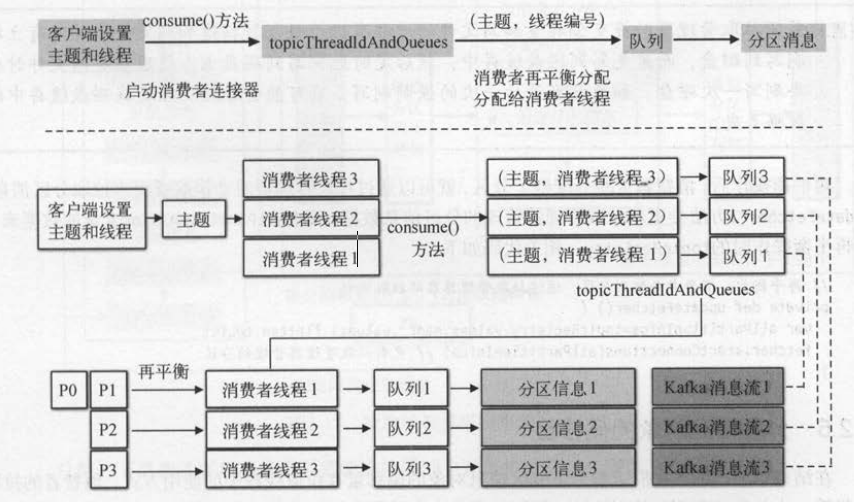
topicRegistry结构是双层嵌套的字典:主题→(分区→分区信息)。topicRegistry表示分配给当前消费者的所有分区信息,并且会被提供给拉取线程 。
分区信息在ZKRebalanceListener端生成,并传输到拉取线程被真正使用 。 注意 : 拉取线程和分区并不存在直接关联,而是通过负责管理所有
拉取线程的消费者拉取线程管理器进行关联 。
关闭和更新拉取线程管理器
再平衡操作中我们已经分析了分区的所有权、分区的分配,剩下和l拉取线程( ConsumerFetcherThread )相关的是 : 关闭和更新消费者的拉取线程
管理器( ConsumerFetcherManager,下文简称“拉取管理器”)。再平衡操作前, closeFetchersForQueues ()方法关闭拉取管理器时,
也要关闭它管理的所有线程 。
除了拉取线程应该关闭 , 和拉取线程相关的数据结构也需要清理,比如分区信息对象的队列需要清空 。 另外 , 消费者在拉取数据时会周期性地
提交偏移量到ZK中,在关闭拉取管理器时也要提交一次所有分区的偏移量。
再平衡操作后,消费者重新分配到了分区,就可以通过拉取管理器启动拉取钱程来拉取分区消息 。updateFetcher()方法会更新拉取管理器
管理的分区信息数据,其中 allPartitioninfos变量的数据来自于再平衡操作时的topicRegistry。
分区信息对象的偏移量
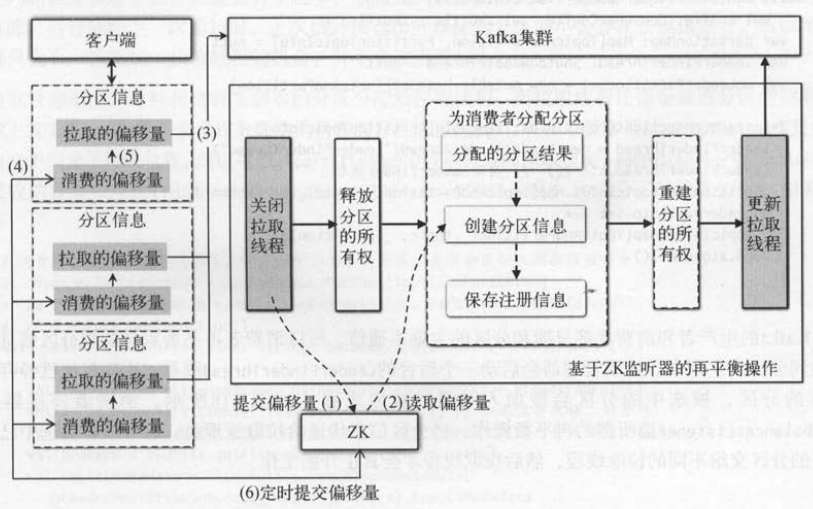
我们来看一下分区信息对象的偏移量在拉取钱程中的使用方式 。 消费者的拉取线程第一次拉取消息时,
会从ZK中读取fetchedOffset来决定要从分区的哪个位置开始拉取消息 。消费者在读取到消息后,会更新分区的consumedOffset 。
同时,消费者也会使用consumedOffset作为分区的消费进度并定时地提交到ZK中 。
分区信息对象的偏移盘在拉取线程中起到很重要的作用,具体步骤如下 。
(1)关闭拉取线程时提交 consumedOffset偏移量到 ZK 。
(2)重新启动拉取线程时读取ZK中的偏移量 。
(3)将ZK的偏移量作为刚开始的 fetchedOffset 。
(4)客户端读取到消息后会更新 consumedOffset。
(5)在这之后每次拉取使用的 fetchedOffset都来向于最新的 consumedOffset。
(6)客户端进程定时提交偏移量和 (1)类似,也是取 consumedOff set写到ZK 中 。
总结一下消费者客户端使用消费者连接器的主要工作,具体步骤如下 。
(1 ) 创建队列和消息流,前者用于保存消费者拉取的消息,后者会读取消息 。
(2)注册各种事件的监听器,当事件发生时,消费组所有消费者成员都会再平衡 。
(3)再平衡会为消费者重新分配分区,并构造分区信息加入 topicRegistry 。
(4)拉取线程获取 topicRegistry 中分配给消费者的所有分区信息开始工作 。