1、线程池的优势
(1)降低创建线程和销毁线程产生的性能开销;
(2)提高响应速度,当有新任务需要执行时不需要等待线程创建就可以马上执行;
(3)合理的设置线程池大小可以避免因为线程数超过硬件资源瓶颈造成的问题。
2、线程池Api
线程池返回值ExecuterService,用于管理线程池。
java线程池中的线程,被抽象为一个静态内部类Worker,它基于AQS实现,存放在HashSet<Worker> workers成员变量中,而需要执行的任务存放在成员变量BlockingQueue<Runnable> workQueue中,线程池从workQueue中不断取出任务,放在workers中执行。
(1)Executers提供四种线程池工厂方法
* newFixedThreadPool:该方法返回一个固定数量的线程池,线程数不变,当有一个任务提交 时,若线程池中空闲,则立即执行,若没有,则会被暂缓在一个任务队列中,等待有空闲的 线程去执行。
使用LinkedBlockingQueue:链表实现的有界阻塞队列,默认和最大长度为Integer.MAX_VALUE,相当于没有上限 ,先进先出(FIFO)。
* newSingleThreadExecutor: 创建一个线程的线程池,若空闲则执行,若没有空闲线程则放入任务队列中。
也是使用LinkedBlockingQueue。
* newCachedThreadPool:不限制最大线程数量,若有空闲的线程则取出任务执行,若无空闲线程则新创建一个线程去执行任务,空闲线程会在60秒后自动回收。
使用SynchronousQueue:不存储元素的阻塞队列,新元素添加必须等里面的元素被拿走。
* newScheduledThreadPool: 创建一个可以指定线程数量的线程池,但是这个线程池还带有延迟和周期性执行任务的功能,类似定时器。
使用DelayQueue:优先级队列实现的无界阻塞队列。
(2)线程池的创建ThreadpoolExecutor
以上四种线程池都是基于ThreadpoolExecutor来构建的,它的构造参数如下:
public ThreadPoolExecutor(
int corePoolSize, //核心线程数量 int maximumPoolSize, //最大线程数 long keepAliveTime, //超时时间,超出核心线程数量以外的线程空余存活时间 TimeUnit unit, //存活时间单位 BlockingQueue<Runnable> workQueue, //保存执行任务的队列 ThreadFactory threadFactory,//创建新线程使用的工厂 RejectedExecutionHandler handler //当任务无法执行的时候的处理方式)
线程池初始化时并没有创建线程,线程池里的线程的创建与其他线程一样,但是在完成任务后,该线程不会自行销毁,而是以挂起的状态返回到线程池。当再次有任务请求时,线程池里挂起的线程会再度被激活执行任务。这样既节省了创建线程所造成的性能损耗,也可以让多个任务反复重用同一个线程。
实际应用:https://www.cnblogs.com/wang-meng/p/10163855.html
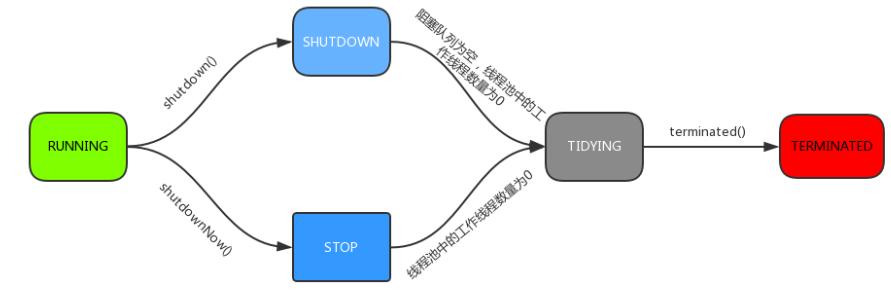
(3)线程池五中状态

线程池状态转换:
3、线程池原理分析
(1)任务执行流程
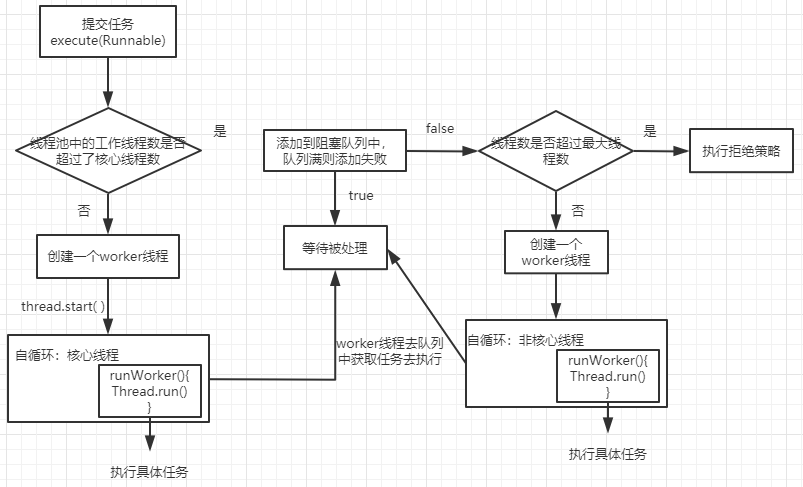
(2)execute(Runnable)源码分析
public void execute(Runnable command) { if (command == null) throw new NullPointerException(); int c = ctl.get(); if (workerCountOf(c) < corePoolSize) {//1.当前池中线程比核心数少,新建一个线程执行任务if (addWorker(command, true)) return; c = ctl.get(); } if (isRunning(c) && workQueue.offer(command)) {//2.核心池已满,但任务队列未满,添加到队列中int recheck = ctl.get(); //任务成功添加到队列以后,再次检查是否需要添加新的线程,因为已存在的线程可能被销毁了 if (! isRunning(recheck) && remove(command)) reject(command);//如果线程池处于非运行状态,并且把当前的任务从任务队列中移除成功,则拒绝该任务else if (workerCountOf(recheck) == 0)//如果之前的线程已被销毁完,新建一个线程 addWorker(null, false); } else if (!addWorker(command, false)) //3.核心池已满,队列已满,试着创建一个新线程 reject(command); //如果创建新线程失败了,说明线程池被关闭或者线程池完全满了,拒绝任务 }
线程池执行任务,先通过addWorker方法构造一个Worker,并且把当前任务firstTask封装到Worker中。那Worker有什么用:
* 每个Worker都是一个线程,同时里面包含一个要执行的任务firstTask
* 最终通过runWorker方法执行任务
Worker类继承了AQS,并实现了Runnable接口,所以其兼具了firstTask和thread属性:firstTask保存了execute传入的要执行的任务,thread是在调用构造方法时通过ThreadFactory创建的用来处理任务的线程。Worker使用AQS实现了独占锁功能,不使用ReentrantLock是因为Worker不允许锁重入,主要用于判断线程是否空闲以及是否可被中断。
* 在执行任务的线程和刚创建的线程不能被中断
* 线程池在执行shutdown方法或tryTerminate方法以及setCorePoolSize时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态,如果可重入则会中断正在运行的线程。
所有创建的Worker线程都存储在HashSet<Worker>中,通过AtomicInteger ctl(32位二进制)记录线程池内线程数,高3位表示线程池状态,低29位表示线程数。
(3)任务执行方法——runWorker
while(task != null || task = getTask() != null){ task.run(); } processWorkerExit(Worker w);
runWorker做两件事:
* 如果Worker创建时没有初始化任务,则去任务队列中取
* Worker线程执行完会被回收。非核心线程一定被回收,如果设置了允许核心线程被回收则核心线程也会被回收。
4、其他
(1)不建议使用Executers创建的线程池。
(2)线程池大小的设置:取决于硬件和软件环境
任务执行情况:
* IO密集型(IO较多,CPU利用率较低),线程池大小=CPU核数的2倍
* CPU密集型(CPU利用率较高),线程池大小=CPU核数+1
(3)execute和submit的区别:
* execute只接受Runnable类型参数,submit可以接受Runnable和Callable类型
* 发生异常时,execute在执行时会将异常抛出,submit在执行时不会抛出异常,只有在future.get()获取返回结果时才会将异常重新封装并抛出。
* submit可以带返回结果:
future.get()获得返回结果,阻塞方法。
将Callable封装成Future。FutureTask自己实现了一个阻塞队列(单向链表),通过一种状态机制(state),任务完成前将当前线程放入队列中,获得结果后将线程唤醒。
部分参考:https://www.cnblogs.com/warehouse/p/10720781.html
自定义线程池:
public class TestThreadPool { static final Logger LOGGER = LoggerFactory.getLogger(TestThreadPool.class); /** * 核心线程数,计算密集型=CPU核数+1,IO密集型=CPU核数*2 */ private static final int CORE_WORKER = Runtime.getRuntime().availableProcessors() * 2; /** * 最大线程数 */ private static final int MAX_WORKER = CORE_WORKER * 2; /** * 非核心线程空闲存活时间 */ private static final long KEEP_ALIVE_TIME = 60L; /** * 线程池名称格式 */ private static final String THREAD_POOL_NAME = "myThreadPool-%d"; /** * 线程池工厂,这里daemon(true)定义成守护线程, * 守护线程和非守护线程(用户线程)的区别:当所有用户线程结束,只剩下守护线程时,JVM也就退出了,守护线程不是不可或缺的。 */ private static final ThreadFactory factory = new BasicThreadFactory.Builder().namingPattern(THREAD_POOL_NAME).daemon(true).build(); /** * 阻塞队列,定义一个500大小的阻塞队列 */ private static final BlockingQueue<Runnable> blockingQueue = new LinkedBlockingQueue<>(500); /** * 线程池 */ private static ThreadPoolExecutor executor; static { try { //初始化线程池 executor = new ThreadPoolExecutor(CORE_WORKER,MAX_WORKER,KEEP_ALIVE_TIME, TimeUnit.SECONDS,blockingQueue,factory); }catch (Exception e){ LOGGER.error("init threadPool error,e:{}",e); } //使用JVM的钩子方法,在JVM退出前会执行该方法,执行完才会关闭,该方法多用于清理内存 Runtime.getRuntime().addShutdownHook(new Thread(new Runnable(){ @Override public void run() { executor.shutdown(); //执行该方法后不再接受新任务 try { // 等待未完成任务结束 if (!executor.awaitTermination(60, TimeUnit.SECONDS)) { executor.shutdownNow(); // 取消当前执行的任务 LOGGER.warn("Interrupt the worker, which may cause some task inconsistent. Please check the biz logs."); // 等待任务取消的响应 if (!executor.awaitTermination(60, TimeUnit.SECONDS)) LOGGER.error("Thread pool can't be shutdown even with interrupting worker threads, which may cause some task inconsistent. Please check the biz logs."); } } catch (InterruptedException ie) { // 重新取消当前线程进行中断 executor.shutdownNow(); LOGGER.error("The current server thread is interrupted when it is trying to stop the worker threads. This may leave an inconcistent state. Please check the biz logs."); } } })); } public static boolean execute(Runnable runnable){ try { executor.execute(runnable); }catch (RejectedExecutionException e){ //#拒绝后可以再放入一个队列里再去执行 } return true; } public static <T> Future<T> submit(Callable<T> task){ try { return executor.submit(task); }catch (RejectedExecutionException e){ //#拒绝后可以再放入一个队列里再去执行 } return null; } }
5、线程池应用场景
(1)快速响应用户请求
比如在一个页面需要给用户展示很多数据,一个一个加载会很慢,所以可以采用线程池分多个模块异步加载,然后再将每个线程获取到的结果拼装到一起。这里用到了带返回结果的任务处理方式,submit()。
(2)快速处理批量任务