1. 下载安装介质
- 计划telegraf和influxdb 使用rpm包进行安装。Grafana使用docker容器方式安装
下载路径为:
https://repos.influxdata.com/rhel/7Server/x86_64/stable/
其实可以根据仓库自己查找就可以了。
拉取镜像为:
docker pull grafana/grafana
注意2021.8时的版本信息为:
influxdb-1.8.9.x86_64.rpm
telegraf-1.19.2-1.x86_64.rpm
grafana 8.1的版本
注意 influxdb2的版本变化比较大 资料比较少一些。
2. 安装介质
yum localinstall *.rpm
需要注意的是,设置为开机启动相关。
3. influxdb参数文件设置
- influxdb的设置
- 注意安装完之后需要启动数据库
- systemctl enable influxdb && systemctl restart influxdb 启动数据库即可。
注意可以通过influx 命令登录进数据库,一开始设置完没有密码可以直接登录,但是用有密码之后必须使用命令进行登录了。
influxdb 是一个时序数据库可以通过telegraf 等工具push监控数据进来,然后交由grafana进行图形化展示。
# 显示用户
SHOW USERS
# 创建用户
CREATE USER "username" WITH PASSWORD 'password'
# 赋予用户管理员权限
GRANT ALL PRIVILEGES TO username
# 创建管理员权限的用户
CREATE USER <username> WITH PASSWORD '<password>' WITH ALL PRIVILEGES
# 修改用户密码
SET PASSWORD FOR username = 'password'
# 撤消权限
REVOKE ALL ON mydb FROM username
# 查看权限
SHOW GRANTS FOR username
# 删除用户
DROP USER "username"
- 注意设置好权限之后就可以进行telegraf的处理了。
4. telegraf的配置文件
-
- systemctl enable influxdb && systemctl restart influxdb 启动数据库即可。
vim /etc/telegraf/vm187.conf
添加内容为:
[global_tags]
[agent]
interval = "10s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "0s"
precision = ""
hostname = ""
omit_hostname = false
[[outputs.influxdb]]
#这里需要修改。
urls = ["http://127.0.0.1:8086"]
database = "vm187"
timeout = "0s"
username = "influxdb"
password = "上一步创建的密码"
[[inputs.vsphere]]
# 这里需要设置为密码
vcenters = [ "https://yourvmcenterip/sdk" ]
username = "administrator@vsphere.local"
password = "yourvcenterpassword"
vm_metric_include = [
"cpu.demand.average",
"cpu.idle.summation",
"cpu.latency.average",
"cpu.readiness.average",
"cpu.ready.summation",
"cpu.run.summation",
"cpu.usagemhz.average",
"cpu.used.summation",
"cpu.wait.summation",
"mem.active.average",
"mem.granted.average",
"mem.latency.average",
"mem.swapin.average",
"mem.swapinRate.average",
"mem.swapout.average",
"mem.swapoutRate.average",
"mem.usage.average",
"mem.vmmemctl.average",
"net.bytesRx.average",
"net.bytesTx.average",
"net.droppedRx.summation",
"net.droppedTx.summation",
"net.usage.average",
"power.power.average",
"virtualDisk.numberReadAveraged.average",
"virtualDisk.numberWriteAveraged.average",
"virtualDisk.read.average",
"virtualDisk.readOIO.latest",
"virtualDisk.throughput.usage.average",
"virtualDisk.totalReadLatency.average",
"virtualDisk.totalWriteLatency.average",
"virtualDisk.write.average",
"virtualDisk.writeOIO.latest",
"sys.uptime.latest",
]
host_metric_include = [
"cpu.coreUtilization.average",
"cpu.costop.summation",
"cpu.demand.average",
"cpu.idle.summation",
"cpu.latency.average",
"cpu.readiness.average",
"cpu.ready.summation",
"cpu.swapwait.summation",
"cpu.usage.average",
"cpu.usagemhz.average",
"cpu.used.summation",
"cpu.utilization.average",
"cpu.wait.summation",
"disk.deviceReadLatency.average",
"disk.deviceWriteLatency.average",
"disk.kernelReadLatency.average",
"disk.kernelWriteLatency.average",
"disk.numberReadAveraged.average",
"disk.numberWriteAveraged.average",
"disk.read.average",
"disk.totalReadLatency.average",
"disk.totalWriteLatency.average",
"disk.write.average",
"mem.active.average",
"mem.latency.average",
"mem.state.latest",
"mem.swapin.average",
"mem.swapinRate.average",
"mem.swapout.average",
"mem.swapoutRate.average",
"mem.totalCapacity.average",
"mem.usage.average",
"mem.vmmemctl.average",
"net.bytesRx.average",
"net.bytesTx.average",
"net.droppedRx.summation",
"net.droppedTx.summation",
"net.errorsRx.summation",
"net.errorsTx.summation",
"net.usage.average",
"power.power.average",
"storageAdapter.numberReadAveraged.average",
"storageAdapter.numberWriteAveraged.average",
"storageAdapter.read.average",
"storageAdapter.write.average",
"sys.uptime.latest",
]
cluster_metric_include = []
datastore_metric_include = []
datacenter_metric_include = []
datacenter_metric_exclude = [ "*" ]
insecure_skip_verify = true
nohup telegraf -config /etc/telegraf/vm187.conf &
后台运行即可。
5. docker 运行grafana
docker run -d -p 3000:3000 --name=grafana -v /opt/grafana-storage:/var/lib/grafana grafana/grafana
注意需要进行持久化避免重启之后数据丢失
6.添加influxdb 的数据源
注意需要输入创建的用户和密码
端口选择为8086
7. 添加grafana的json文件或者是执行导入即可。
- 先展示一下效果
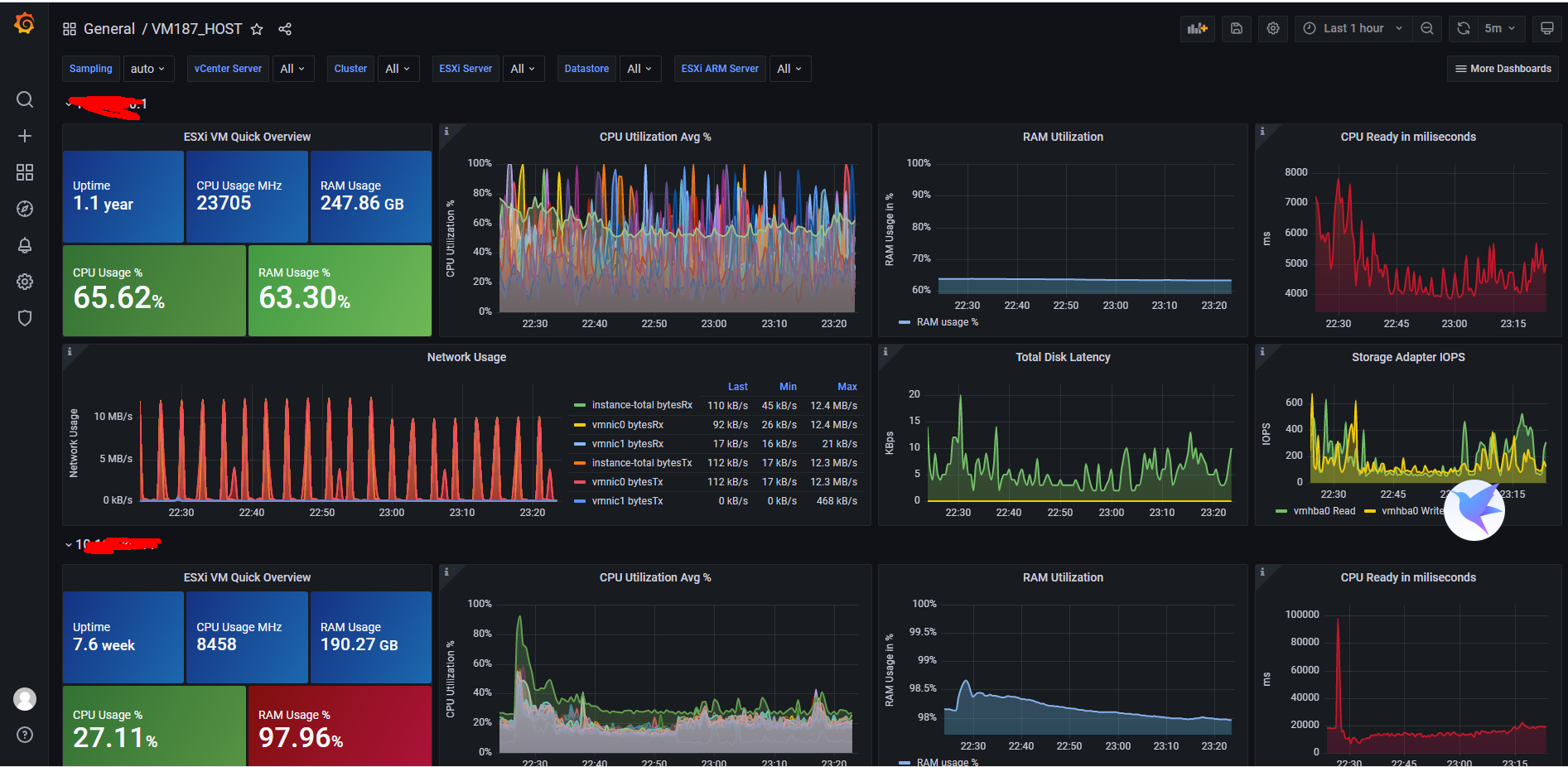
- 使用的配置文件为:
https://grafana.com/grafana/dashboards/6171