自 2012 年 AlexNet 以来,卷积神经网络在图像分类、目标检测、语义分割等领域获得广泛应用。随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 CNN 网络,如 VGG、GoogLeNet、ResNet、DenseNet 等。由于神经网络的性质,为了获得更好的性能,网络层数不断增加,从 7 层 AlexNet 到 16 层 VGG,再从 16 层 VGG 到 GoogLeNet 的 22 层,再到 152 层 ResNet,更有上千层的 ResNet 和 DenseNet。虽然网络性能得到了提高,但随之而来的就是效率问题。
效率问题主要是模型的存储问题和模型进行预测的速度问题。
1、存储问题。数百层网络有着大量的权值参数,保存大量权值参数对设备的内存要求很高;
2、速度问题。在实际应用中,往往是毫秒级别,为了达到实际应用标准,要么提高处理器性能(很难),要么就减少计算量。
只有解决 CNN 效率问题,才能让 CNN 走出实验室,更广泛的应用于移动端。
对于效率问题,通常的方法是进行模型压缩(Model Compression),即在已经训练好的模型上进行压缩,使得网络携带更少的网络参数,从而解决内存问题,同时可以解决速度问题。
相比于在已经训练好的模型上进行处理,轻量化模型模型设计则是另辟蹊径。轻量化模型设计主要思想在于设计更高效的「网络计算方式」(主要针对主干网卷积),从而使网络参数减少的同时,不损失网络性能。
MobileNetV1
谷歌在2017年提出专注于移动端或者嵌入式设备中的轻量级CNN网络:MobileNet。最大的创新点是深度可分离卷积。
传统卷积分成两步,每个卷积核与每张特征图进行按位相成然后进行相加,此时,计算量为DF∗DF∗DK∗DK∗M∗N,其中DF为特征图尺寸,DK为卷积核尺寸,M为输入通道数,N为输出通道数。深度可分离卷积将传统卷积的两步进行分离开来,分别是depthwise和pointwise。从下面的图可以看出,首先按照通道进行计算按位相乘的计算,此时通道数不改变;然后依然得到将第一步的结果,使用1*1的卷积核进行传统的卷积运算,此时通道数可以进行改变。使用了深度可分离卷积,其计算量为DK∗DK∗M∗DF∗DF+1∗1∗M∗N∗DF∗DF。

通过深度可分离卷积,计算量将会下降,当时,深度可分离卷积比传统卷积少8到9倍的计算量。深度可分离卷积虽然很好的减少计算量,但同时也会损失一定的准确率。

最后给出v1的整个模型结构,该网络有28层。可以看出,该网络基本去除了pool层,使用stride来进行降采样。

depthwise后接BN层和RELU6,pointwise后也接BN层和RELU6,如下图所示(图中应该是RELU6)。左图是传统卷积,右图是深度可分离卷积。更多的ReLU6,增加了模型的非线性变化,增强了模型的泛化能力。

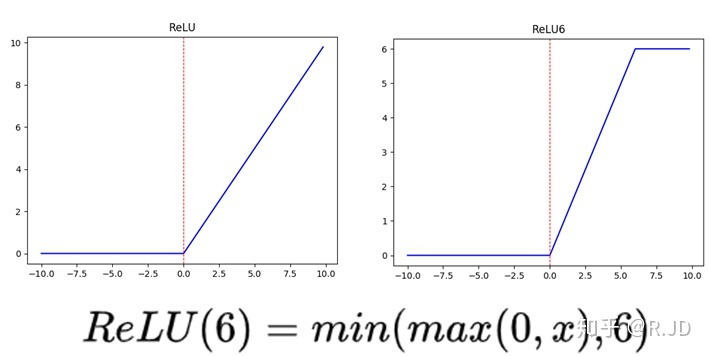
v1中使用了RELU6作为激活函数,这个激活函数在float16/int8的嵌入式设备中效果很好,能较好地保持网络的鲁棒性。
MobileNet给出了2个超参,宽度乘子α和分辨率乘子β,通过这两个超参,可以进一步缩减模型,文章中也给出了具体的试验结果。此时,我们反过来看,扩大宽度和分辨率,都能提高网络的准确率,但如果单一提升一个的话,准确率很快就会达到饱和,这就是2019年谷歌提出efficientnet的原因之一,动态提高深度、宽度、分辨率来提高网络的准确率。
MobileNetV2
2018年谷歌又一新作,在V1的基础上,引入了Inverted Residuals和Linear Bottlenecks。
在使用V1的时候,发现depthwise部分的卷积核容易费掉,即卷积核大部分为零。作者认为这是ReLU引起的。
简单来说,就是当低维信息映射到高维,经过ReLU后再映射回低维时,若映射到的维度相对较高,则信息变换回去的损失较小;若映射到的维度相对较低,则信息变换回去后损失很大,如下图所示:

因此,认为对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。另外一种解释是,高维信息变换回低维信息时,相当于做了一次特征压缩,会损失一部分信息,而再经过relu后,损失的部分就更加大了。作者为了这个问题,就将ReLU替换成线性激活函数。
Inverted Residuals
这个可以翻译成“倒残差模块”。什么意思呢?我们来对比一下残差模块和倒残差模块的区别。
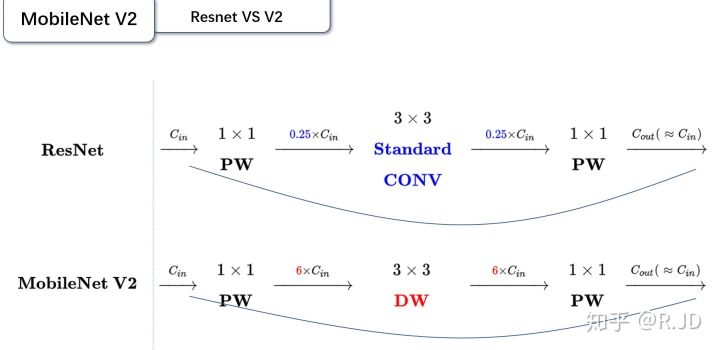
- 残差模块:输入首先经过1*1的卷积进行压缩,然后使用3*3的卷积进行特征提取,最后在用1*1的卷积把通道数变换回去。整个过程是“压缩-卷积-扩张”。这样做的目的是减少3*3模块的计算量,提高残差模块的计算效率。
- 倒残差模块:输入首先经过1*1的卷积进行通道扩张,然后使用3*3的depthwise卷积,最后使用1*1的pointwise卷积将通道数压缩回去。整个过程是“扩张-卷积-压缩”。为什么这么做呢?因为depthwise卷积不能改变通道数,因此特征提取受限于输入的通道数,所以将通道数先提升上去。文中的扩展因子为6。
Linear Bottleneck
这个模块是为了解决一开始提出的那个低维-高维-低维的问题,即将最后一层的ReLU6替换成线性激活函数,而其他层的激活函数依然是ReLU6。
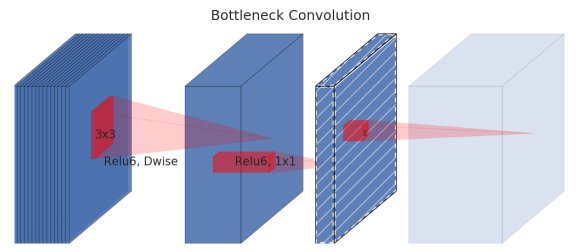
将两个模块进行结合,如下图所示。当stride=1时,输入首先经过1*1的卷积进行通道数的扩张,此时激活函数为ReLU6;然后经过3*3的depthwise卷积,激活函数是ReLU6;接着经过1*1的pointwise卷积,将通道数压缩回去,激活函数是linear;最后使用shortcut,将两者进行相加。而当stride=2时,由于input和output的特征图的尺寸不一致,所以就没有shortcut了。

最后,给出v2的网络结构。其中,t为扩张系数,c为输出通道数,n为该层重复的次数,s为不长。可以看出,v2的网络比v1网络深了很多,v2有54层。

当然,少不了性能对比图。v2的准确率比v1高出不少,延时也低了很多,是一款不错的轻量化网络。

MoblieNetV3
MobileNet V3发表于2019年,该v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。
v3在v2的版本上有以下的改进:
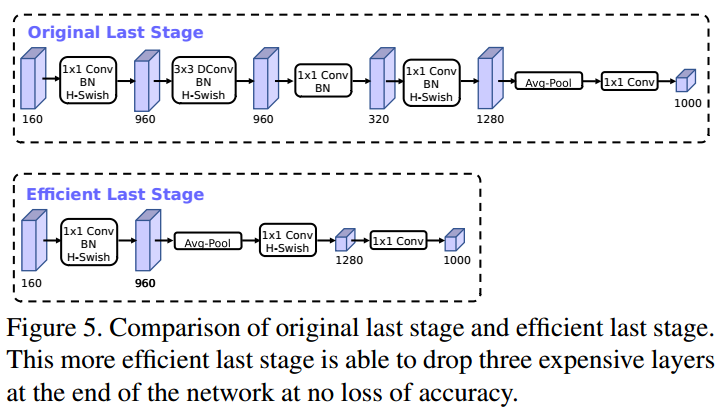
- 作者发现,计算资源耗费最多的层是网络的输入和输出层,因此作者对这两部分进行了改进。如下图所示,上面是v2的最后输出几层,下面是v3的最后输出的几层。可以看出,v3版本将平均池化层提前了。在使用1*1卷积进行扩张后,就紧接池化层-激活函数,最后使用1*1的卷积进行输出。通过这一改变,能减少10ms的延迟,提高了15%的运算速度,且几乎没有任何精度损失。其次,对于v2的输入层,通过3*3卷积将输入扩张成32维。作者发现使用ReLU或者switch激活函数,能将通道数缩减到16维,且准确率保持不变。这又能节省3ms的延时。
- 由于嵌入式设备计算sigmoid是会耗费相当大的计算资源的,因此作者提出了h-switch作为激活函数。且随着网络的加深,非线性激活函数的成本也会随之减少。所以,只有在较深的层使用h-switch才能获得更大的优势。
- 在v2的block上引入SE模块,SE模块是一种轻量级的通道注意力模块。在depthwise之后,经过池化层,然后第一个fc层,通道数缩小4倍,再经过第二个fc层,通道数变换回去(扩大4倍),然后与depthwise进行按位相加。

最后,v3的结构如下图所示。作者提供了两个版本的v3,分别是large和small,对应于高资源和低资源的情况。两者都是使用NAS进行搜索出来的。
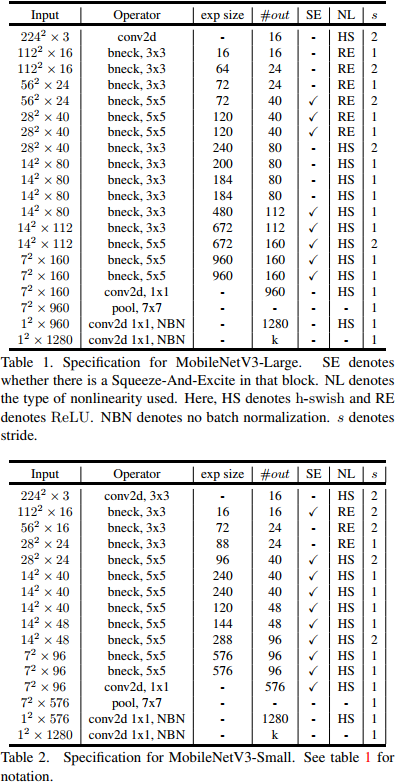
从下面的试验结果,可以看出v3-large的准确率和计算速度都高于v2。所以,AutoML搭出来的网络,已经能代替大部分调参了。
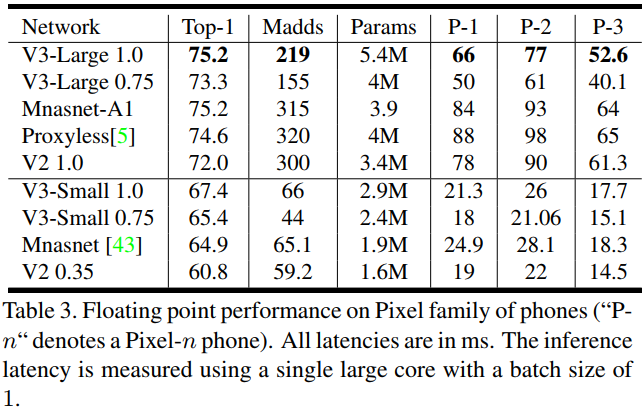
MobileNetV3网络结构分为三部分:
- 起始部分:1个卷积层,通过3x3的卷积,提取特征;
- 中间部分:多个卷积层,不同Large和Small版本,层数和参数不同;
- 最后部分:通过两个1x1的卷积层,代替全连接,输出类别;
网络框架如下,其中参数是Large体系:
源码如下(Pytorch):
def forward(self, x): # 起始部分 out = self.init_conv(x) # 中间部分 out = self.block(out) # 最后部分 out = self.out_conv1(out) batch, channels, height, width = out.size() out = F.avg_pool2d(out, kernel_size=[height, width]) out = self.out_conv2(out) out = out.view(batch, -1) return out
起始部分
起始部分,在Large和Small中均相同,也就是结构列表中的第1个卷积层,其中包括3个部分,即卷积层、BN层、h-swish激活层。
init_conv_out = _make_divisible(16 * multiplier) self.init_conv = nn.Sequential( nn.Conv2d(in_channels=3, out_channels=init_conv_out, kernel_size=3, stride=2, padding=1), nn.BatchNorm2d(init_conv_out), h_swish(inplace=True), )
h-swish 和 h-sigmoid
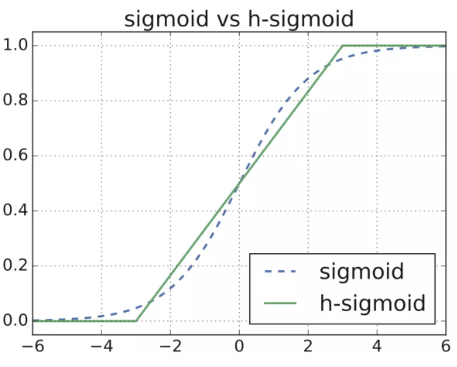
h-swish是非线性激活函数,公式如下:
![]()
图形如下:

源码如下:
out = F.relu6(x + 3., self.inplace) / 6. return out * x
H-sigmoid是非线性激活函数,用于SE结构,源码如下:
return F.relu6(x + 3., inplace=self.inplace) / 6.
卷积计算公式:
- 输入图片:W×W
- 卷积核:F×F
- 步长:S
- Padding的像素值:P
- 输出图片大小为:N×N
N = (W − F + 2P ) / S + 1 #其中,向下取整,多余的像素不参于计算。
中间部分
中间部分是多个含有卷积层的块(MobileBlock)的网络结构,Large的网络结构:
其中:
- SE:Squeeze-and-Excite结构,压缩和激发;
- NL:Non-Linearity,非线性;HS:h-swish激活函数,RE:ReLU激活函数;
- bneck:bottleneck layers,瓶颈层;
- exp size:expansion factor,膨胀参数;
每一行都是一个MobileBlock,即bneck。
源码:
self.block = [] for in_channels, out_channels, kernel_size, stride, nonlinear, se, exp_size in layers: in_channels = _make_divisible(in_channels * multiplier) out_channels = _make_divisible(out_channels * multiplier) exp_size = _make_divisible(exp_size * multiplier) self.block.append(MobileBlock(in_channels, out_channels, kernal_size, stride, nonlinear, se, exp_size)) self.block = nn.Sequential(*self.block)
MobileBlock
三个必要步骤:
- 1x1卷积,由输入通道,转换为膨胀通道;
- 3x3或5x5卷积,膨胀通道,使用步长stride;
- 1x1卷积,由膨胀通道,转换为输出通道。
两个可选步骤:
- SE结构:Squeeze-and-Excite;
- 连接操作,Residual残差;步长为1,同时输入和输出通道相同;
其中激活函数有两种:ReLU和h-swish。
结构如下,参数为特定,非通用:
def forward(self, x): # MobileNetV2 out = self.conv(x) # 1x1卷积 out = self.depth_conv(out) # 深度卷积 # Squeeze and Excite if self.SE: out = self.squeeze_block(out) # point-wise conv out = self.point_conv(out) # connection if self.use_connect: return x + out else: return out
其中,1x1卷积:
self.conv = nn.Sequential( nn.Conv2d(in_channels, exp_size, kernel_size=1, stride=1, padding=0), nn.BatchNorm2d(exp_size), activation(inplace=True) )
SE模块:
self.depth_conv = nn.Sequential( nn.Conv2d(exp_size, exp_size, kernel_size=kernal_size, stride=stride, padding=padding, groups=exp_size), nn.BatchNorm2d(exp_size), )
1x1逐点卷积
self.point_conv = nn.Sequential( nn.Conv2d(exp_size, out_channels, kernel_size=1, stride=1, padding=0), nn.BatchNorm2d(out_channels), activation(inplace=True) )
SE结构
- 池化;
- Squeeze线性连接 + RELU + Excite线性连接 + h-sigmoid;
- resize;
- 权重与原值相乘;
class SqueezeBlock(nn.Module): def __init__(self, exp_size, divide=4): super(SqueezeBlock, self).__init__() self.dense = nn.Sequential( nn.Linear(exp_size, exp_size // divide), nn.ReLU(inplace=True), nn.Linear(exp_size // divide, exp_size), h_sigmoid() ) def forward(self, x): batch, channels, height, width = x.size() out = F.avg_pool2d(x, kernel_size=[height, width]).view(batch, -1) out = self.dense(out) out = out.view(batch, channels, 1, 1) return out * x
残差结构
最终的输出与原值相加,源码如下:
self.use_connect = (stride == 1 and in_channels == out_channels) if self.use_connect: return x + out else: return out
最后部分
最后部分(Last Stage),通过将Avg Pooling提前,减少计算量,将Squeeze操作省略,直接使用1x1的卷积,如图:
out = self.out_conv1(out) batch, channels, height, width = out.size() out = F.avg_pool2d(out, kernel_size=[height, width]) out = self.out_conv2(out)
第1个卷积层conv1,SE结构同上,源码如下:
out_conv1_in = _make_divisible(96 * multiplier) out_conv1_out = _make_divisible(576 * multiplier) self.out_conv1 = nn.Sequential( nn.Conv2d(out_conv1_in, out_conv1_out, kernel_size=1, stride=1), SqueezeBlock(out_conv1_out), h_swish(inplace=True), )
第2个卷积层:
out_conv2_in = _make_divisible(576 * multiplier) out_conv2_out = _make_divisible(1280 * multiplier) self.out_conv2 = nn.Sequential( nn.Conv2d(out_conv2_in, out_conv2_out, kernel_size=1, stride=1), h_swish(inplace=True), nn.Conv2d(out_conv2_out, self.num_classes, kernel_size=1, stride=1), )
最后,调用resize方法,将Cx1x1转换为类别,即可:
out = out.view(batch, -1)
除此之外,还可以设置multiplier参数,等比例的增加和减少通道的个数,满足8的倍数,源码如下:
def _make_divisible(v, divisor=8, min_value=None): if min_value is None: min_value = divisor new_v = max(min_value, int(v + divisor / 2) // divisor * divisor) # Make sure that round down does not go down by more than 10%. if new_v < 0.9 * v: new_v += divisor return new_v
至此,网络结构完成。