摘要:
一般情况下,我们都会根据当前的硬件资源来设计相应的卷积神经网络,如果资源升级,可以将模型结构放大以获取更好精度。我们系统地研究模型缩放并验证网络深度,宽度和分辨率之间的平衡以得到更好的性能表现。基于此思路,提出了一种新的缩放方法:利用复合系数来统一缩放模型的所有维度,达到精度最高效率最高。复合系数有:w卷积核大小,d神经网络深度,r分辨率大小。在之前的MobileNet和ResNet上已展示了这种缩放方法的高效性。
使用神经架构搜索设计了一个主干网络,并且将模型放大获取一系列模型,我们称之为Efficient,它的精度和效率比之前所有的卷积网络都好。尤其是我们的EfficientNet-B7在ImageNet上获得了最先进的 84.4%的top-1精度 和 97.1%的top-5精度,同时比之前最好的卷积网络大小缩小了8.4倍、速度提高了6.1倍。我们的EfficientNets也可以很好的迁移,并且实现了最先进的精度——CIFAR-100(91.7%)、Flowers(98.8%)、其他3个迁移学习数据集。
谷歌最新论文:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks ICML 2019
相应源码地址:EfficientNet
1、不同的网络调节方法:增大感受野,增大网络深度,增大分辨率,如下图:

其中,(a)为基线网络,也可以理解为小网络;(b)为增大感受野的方式扩展网络;(c)为增大网络深度d的方式扩展网络;(d)为增大分辨率r的方式扩展网络;(e)为本文所提出的混合参数扩展方式;模型缩放的高效性严重地依赖于baseline网络,为了进一步研究,我们使用网络结构搜索发展了一种新的baseline网络,然后将它缩放来获得一系列模型,称之为EfficientNets。
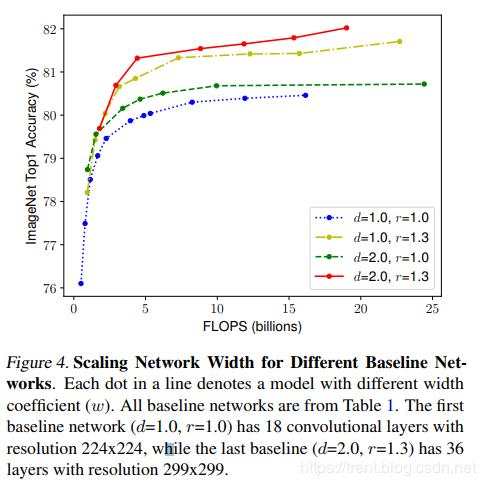
2、测试效果,在w,r,d各种情况下的准确率和效率的相互关系曲线
一般卷积的数学模型如下:
![]()
H,W为卷积核大小,C为通道数,X为输入tensor;
复合系数的确定转为如下的优化问题:
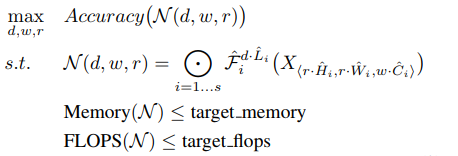
调节d,w,r使得满足内存Memory和浮点数量都小于阈值要求;
为了达到这个目标,文中提出了如下的方法:
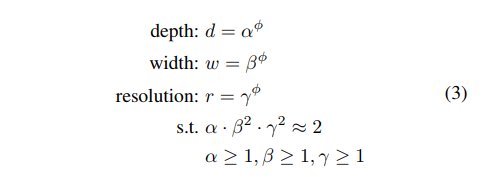
对于这个方法,我们可以通过一下两步来确定d,w,r参数:

第一步我们可以通过基线网络来调节确定最佳的,然后,用这个参数将基准网络扩展或放大到大的网络,这样就可以使大网络也具有较高的准确率和效率。同样,我们也可以将基线网络扩展到其他网络,使用同样的方法来放大;
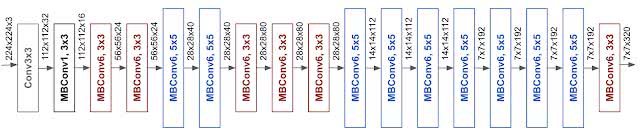
基线模型使用的是 mobile inverted bottleneck convolution(MBConv),类似于 MobileNetV2 和 MnasNet,但是由于 FLOP 预算增加,该模型较大。于是,研究人员缩放该基线模型,得到了EfficientNets模型,它的网络示意图如下:
EfficientNet效率测试:
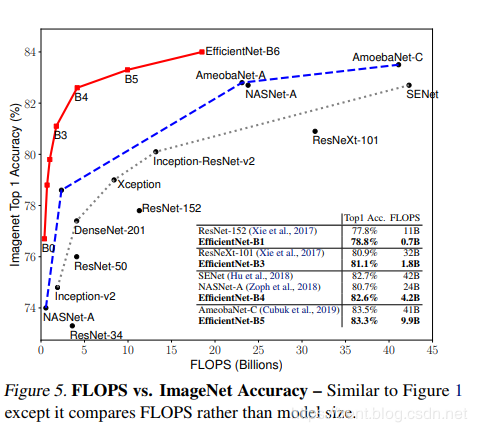
对比EfficientNets和已有的CNN模型,EfficientNet 模型要比已有CNN模型准确率更高、效率更高,其参数量和 FLOPS 都下降了一个数量级,EfficientNet-B7 在 ImageNet 上获得了当前最优的 84.4% top-1 / 97.1% top-5 准确率,而且CPU 推断速度是 Gpipe 的 6.1 倍,但是模型大小方面,EfficientNet-B7却比其他模型要小得多,同时,还对比了ResNet-50,准确率也是胜出一筹(ResNet-50 76.3%,EfficientNet-B4 82.6%)。
3、相关工作:
ConvNet精度:自从AlexNet赢得2012的ImageNet竞赛,ConvNets随着变得更大获得了更高的精度,同时GoogleNet使用6.8M的参数获得了74.8%的top-1精度,SENet使145M参数获得了82.7%的top-1精度。最近,GPipe进一步提高了精度——使用了557M的参数获得了84.3%的top-1验证精度:它如此的大以至于需要将网络划分使用特定的并行化手段训练,然后将每一部分传递到一个不同的加速器。然而这些模型主要是为ImageNet设计,但是将其迁移到其他应用上时效果也很好。
ConvNet效率:深度网络的参数过多,模型压缩是一种通用的方法减小模型大小——平衡精度和效率。当移动网络变得无处不在时,我们也通常要手动设计高效的ConvNets,比如SqueezeNets、MobileNets、ShuffleNets。最近,神经网络结构搜索在设计高效的ConvNets变得越来越流行,并且通过广泛搜索网络宽度、深度、卷积核类型和大小得到了比手动设计的模型更高的精度。然而,目前还不清楚怎么将这些技术应用到更大的模型中,通常要更大的设计空间和更贵的微调成本,在本篇论文中,我们旨在研究效率设计更大规模的ConvNets,为了实现这个目标,我们采用模型缩放。
模型缩放:有很多的方法因不同的资源限制对ConvNet进行缩放:ResNet可以通过调整深度(缩小到ResNet-18,放大到ResNet-200),WideResNet和MobileNets可以通过对宽度(#channels)缩放。公认的是更大的输入图像尺寸有利于提高精度,同时需要更多的计算量。尽管之前的研究展示了网络深度和宽度对ConvNets的表现力很重要,它仍然是一个开放的问题来高效缩放ConvNet获得更好的效率和精度。我们的工作系统地研究了ConvNet对网络深度、宽度和分辨率这三个维度进行了缩放。
参考链接:
1、https://blog.csdn.net/Trent1985/article/details/91126085
2、https://blog.csdn.net/h__ang/article/details/92801712