选择排序 每一趟从待排序的元素中,选出最小的元素,放到已经排好序的序列的后面直到全部元素排序完毕。在这个过程中,有序区逐步扩大,而无序区逐渐缩小。
直接选择排序
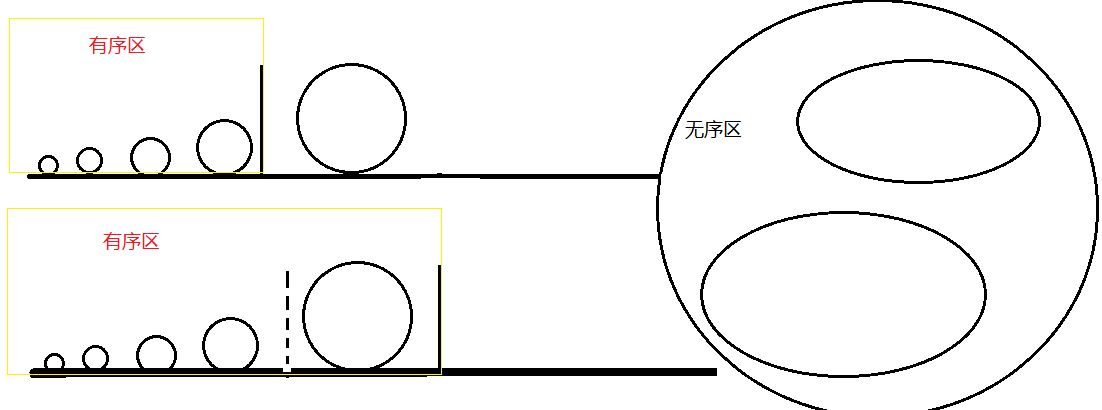
直接选择排序是将无序区内的最小元素追加到有序区的后面,从而扩大有序区的范围。而我们又是在原地排序,所有也就相当与交换无序区的第一个元素和无序区最小元素的位置。
我们需要一个游标来追踪无序区的最小元素。 假设为 K ,
我们又同时假设每一趟排序前,无序区的第一个元素就是当前无序区的最小元素。 也就是说 k 在每一次排序开始时,都是指向无序区的第一个元素。

假设有这样一个序列,最初整个序列都是无序的。k = 0; k指向6,我们假设6 是无序区里面最小的。(但这显然是不可能的)
我们遍历无序区所有元素,得到真正的最小元素的索引,赋值给k 然后将真正的最小元素和 无序区的第一个元素进行交换

如图我们已经找到了无序区最小元素并完成了交换,同时有序区长度变为了1
然后我们继续我们的排序工作。此时k=1,k指向2,我们假设 2 就是整个无序区的最小元素
我们遍历所有的无序区元素,发现,2还真是最小的元素。直接扩大有序区的范围即可,不需要交换

继续排序,k=2,k指向4,依旧遍历所有无序区的元素,发现3才是真正最小的,于是将3 和4交换,有序区范围再一次扩大

继续,k=3,指向6,遍历所有的无序区元素,发现4才是最小的,交换6 和4

继续 k = 4,指向5 ,遍历所有无序区的元素,发现5确实是最小的,扩大有序区的范围

k=5,指向6,发现6就是最大的了

有序区扩大到整个序列,排序完成。
代码如下:
def select_sort(A,n): for i in range(n): # 无序区的范围是 [0,n-1] k = i #确定每次循环 k 的初始值。仔细研究一下上图会发现 每次循环 的 i 和 k 的值相等,都是当前无序区的第一个元素的索引 for j in range(i+1,n): # 已经假设 k 指向的就是最小元素,但实际可能并不是,因此从无序区的第二个元素开始遍历所有剩余的元素,(也可以从i 开始,也就是说,从无序区的第一个元素开始,但是 k 本身就是无序区的第一个元素,它永远不可能比他自己小,所以无序区的第二个元素开始查找比较好) if A[k]>A[j]: #如果正在遍历的元素小于 k 指向的元素 k = j #那么就移动 k ,知道所有的剩余元素都遍历完,这时候才能确定真正的 k 的位置。 if k != i: # 这里判断 k 是否等与 i 的作用是为了减少操作量,就像 上图里面k=1的时候,发现它确实就是最小的,因此就没必要进行下面的操作。 A[k],A[i]=A[i],A[k] # 经过上面的查找已经找到了无序区真正的最小元素的索引,交换无序区最小元素和第一个元素。 return A A=[6,2,4,1,5,3] n =len(A) print(select_sort(A,n))