希尔排序
希尔排序也是插入排序的一种。又名缩小增量排序。它是对直接插入排序的一种改进。
直接插入排序是每次都和前面一个元素进行比较。其步长为 1。 希尔排序则不然,它得步长是动态变化的,或者说是由大到小变化的。希尔排序根据步长将整个序列分成n组。然后在各个子组内部分别进行元素的排序。接着缩小步长,相应的序列被分成的子组也就会减少,每个分组内部的元素个数也就相应的增加。接着对子组内部的元素进行排序。再次缩小步长,再次排序。。。。直到步长为 1,即整个序列只有一个子组,也就是序列本身。这个时候再次进行排序即为最终排序。
假设有这样一串序列
a=[23,19,31,47,52,16,45,21]
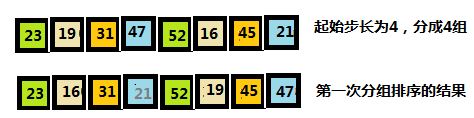 、
、
如图所示:(从小到大排序)
第一次设置步长为4,相同颜色即为一个分组。然后每个相同颜色的方框内的元素相互比较,调整大小,因为是从小到大排序,所以,小的在前,大的在后。从而得到排序结果。
然后调整步长,再次分组

如图所示:
第二次步长调整为了原来的一半,分成了两组。重复刚才的对相同颜色的方框内的元素进行排序的动作,小的在前,大的在后,得到排序结果
再次调整步长,再次分组

如图所示:
第三次步长调整,步长为 1,分组为1 ,这是最大分组了。还是重复组内排序的的动作。得到最终结果。
希尔排序就是这样,分组——排序——分组——排序——分组——排序 最终得到最终结果。
代码如下:


def shellSort( A): n = len(A) gap=n//2 # 设置初始步长, 同时也代表着分组的个数。 while gap>0: # 步长也就是分组个数最小是 1,只要不为 1 就重复下面的分组--排序动作 for i in range(gap,n): # 为什么从gap开始呢?一会说 temp=A[i] #取出每一个分组内第一个无序区元素 j=i-gap #获取该分组内,最大的有序区元素索引 while j>=0 and temp<A[j]: # 将无序区第一个元素逐个和该分组内有序区的元素比较。 A[j+gap]=A[j] # 因为每个组之间的元素之间是相隔着gap(当前步长)个其他组的元素的,所以,当赋值的时候,也要注意。 j-=gap #如果一直满足while循环条件,那么就按当前的步长向前移动 A[j+gap]=temp #退出while循环意味着,已经找到了适当的插入的位置。将当前元素插入到合适位置 gap = gap //2 # 该步长下,所有的分组都进行了排序,那么调整步长,减少分组个数,扩大分组长度。再次进行排序 return A a=[23,19,31,47,52,16,45,21] print(shellSort(a))
为什么循环时, i 要从 gap开始呢?
希尔排序是直接插入排序的改进版本。直接插入排序步长为1,直接插入排序分组也只有一个大的分组,就是它本身。而希尔排序因为步长不是1,所以其分组也是多个。虽然是多个分组,但是每个分组内部排序的时候,还是和直接插入排序是一样的——从该分组内的第二个元素开始,逐个和前面的元素进行比较,直到找到合适的位置。只是这个时候,前一个元素索引不再是 i-1 了,而是 i -gap了。还是因为步长的存在导致的。
在本例中 gap= 4
为什么从4开始呢。是因为前三个元素,i-gap 都小于0,他们各自的分组内没有前一个元素,他们本身就是各自分组的第一个元素。所以就直接从4开始。当然也可以强制从0开始,只是没什么实际意义,做无用功而已。