def querynext(t): next = {} x = 0 y = -1 next[0] = -1 x_rang = len(t)-1 while x < x_rang: if y == -1 or t[x] == t[y]: x += 1 y += 1 next[x] = y # 当第 x 个元素匹配失败时,下次匹配从第 y 个元素开始。 else: y = next[y] return next def kmpdex(s,t): i = 0 # 字符串s 的索引 目标串 j = 0 # 字符串 t 的索引 匹配串 next = querynext(t) # 通过对匹配串调用querynext() 得到一个供后续匹配查询的字典。 s_len = len(s) t_len = len(t) while i < s_len and j < t_len: if j == -1 or s[i] == t[j]: i += 1 j += 1 else: j = next[j] # 如果出现了不匹配,那么就在next 字典查询,从t串的哪个字符开始重新匹配。 if j >= t_len: return i - t_len else: return -1 s = 'acabab aabc' t = 'bab' resu = kmpdex(s,t) if resu == -1: print('没有匹配成功') else: print('从第 %s 开始匹配,共计 %s 个字符' % (resu,len(t)))
KMP 算法是对 B-F 匹配算法的改进。减少了 B-F 算法匹配失败后,回退重新匹配时过多的无效匹配次数。
该算法的关键是在开始匹配之前,通过对匹配串进行计算,预先生成一个字典。
这个字典的作用是在匹配失败后,供程序查找,下一次开始匹配时,从匹配串的哪个字符开始比较。
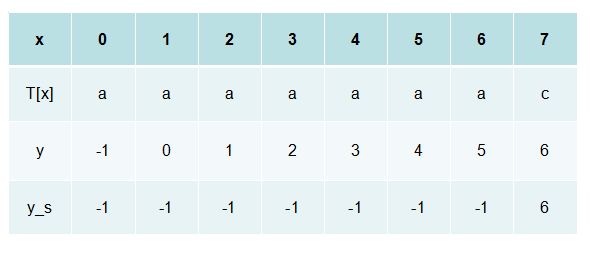
querynext函数(自定义的函数名)
该函数的目的是通过对匹配串进行计算,生成一个字典。该字典如下形式:{x:y}
x : 匹配失败时,匹配失败字符在匹配串中的索引
y : 下一次匹配时,起始匹配字符串的索引 (很多资料叫:next[x])
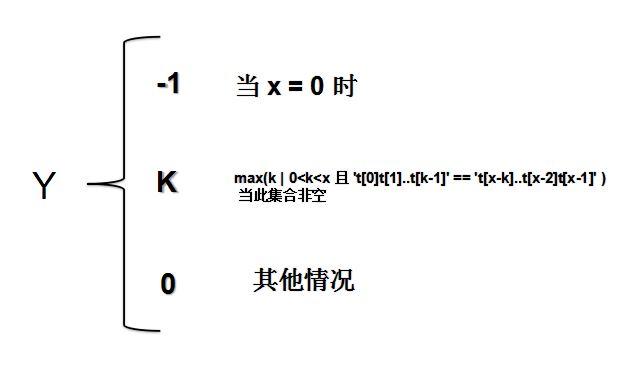
k 是一个集合的最大值
假如有一个匹配字符串 T,在 x 出匹配失败。那么从 T[0] 到 T[k-1] 取子字符串和从T[x-k] 到 T[x-1]取子字符串,如果相等,那么产生一个值放入集合中,
最后在集合中选取最大的就是 k值
如果下所示:
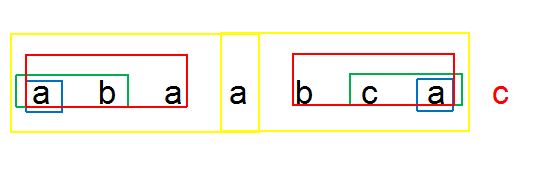
假如 匹配串 T = 'abaabcac' 在进行匹配时,在 红c 处匹配失败了。即 x=7
那么k值计算如下:
1、蓝框,两侧两个字符均为 'a' ,相等,把 1 放入集合中
2、绿框 左侧为 'ab' 右侧为'ca' 不相等
3、红框 左侧为'aba' 右侧为 'bca' 不相等
4、黄框 左侧为''abaa' 右侧为 'abcd' 不相等
还可以继续取下去,但是会发现没有相等的了。所以集合中只有一个 1 。
那么 y = 1
那么next={7:1}
同理,可以得到下图
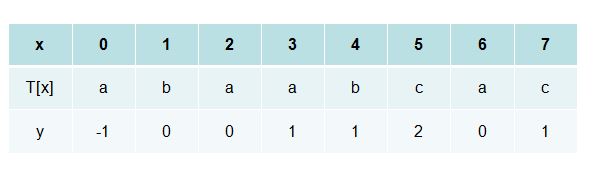
y 值有如下含义:
1、它是下次匹配时,匹配串 t 的起始匹配字符的索引(可能从0开始也可能直接跨过0,从后面的某一个元素开始)
2、它是匹配失败字符前面的最大的相等字符串的元素个数,(不包括0 和-1这两种情况)也就是 k值。
3、因为2,所以意味着当重新开始匹配时,匹配串和目标串在当前匹配位置前有y个字符相同。(所以才会产生1 那种情况)
当匹配串形如 Z= 'aaaaab'时,上面的算法依旧会发生多余的匹配。所以改进如下:
def querynext_dev(t): next = {} x = 0 y = -1 next[0] = -1 x_rang = len(t)-1 while x < x_rang: if y == -1 or t[x] == t[y]: x += 1 y += 1 if t[x] != t[y]: next[x]=y else: next[x]=next[y] else: y = next[y] return next def kmpdex(s,t): i = 0 # 字符串s 的索引 目标串 j = 0 # 字符串 t 的索引 匹配串 next = querynext_dev(t) # 通过对匹配串调用querynext() 得到一个共后续匹配查询的字典。 print(next) s_len = len(s) t_len = len(t) while i < s_len and j < t_len: if j == -1 or s[i] == t[j]: # 如果两个字符串匹配成功 i += 1 j += 1 else: j = next[j] # 如果出现了不匹配,那么就在next 字典查询,从t串的哪个字符开始重新匹配。 if j >= t_len: return i - t_len else: return -1 s = 'aabaaaabaaabaababa' t = 'aaaab' resu = kmpdex(s,t) if resu == -1: print('没有匹配的') else: print('从第 %s 开始匹配,共计 %s 个字符' % (resu,len(t)))