对于爬虫工作者来说网络爬虫是十分熟悉的,网络爬虫之所以会有现在的发展空间,便是因为使用爬虫程序爬取网页信息是非常便捷、快速、高效的,同事也要小心ip地址被网站反爬虫限制。其实被网站限制是一个非常简单的道理,比如我们建立一个自己的网站肯定希望自己的成果不被恶意的竞争者破坏,will白虎自己的劳动成果,只能这种反爬虫限制,我们的服务器的承载能力是有限的,假如一直抓取数据会使的服务器的承载压力过大,容易崩盘。由于这个原因很多的网站都设置了防爬虫机制,来防止网络爬虫。
当遇到网站的反爬虫机制的时候还想继续进行网站爬取,就要使用到代理ip,倘若当前的ip受到限制,就可以使用新的ip地址进行数据的抓取,在我们进行数据抓取的时候,如果不想让人直播自己的真实的ip地址,使用代理ip可以隐藏真正的ip地址,维护网络爬虫的安全。那么HTTP代理是怎样提取ip,进行数据抓取的。
1、使用极光HTTP代理软件提取ip

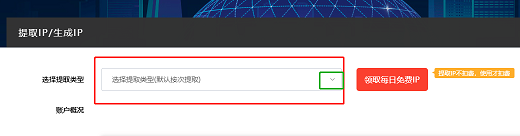

2、提取ip-ip提取完成
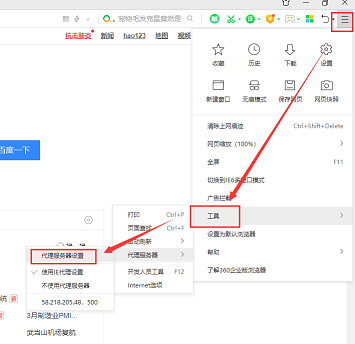
3提取ip进行使用(360浏览器为例)

在我们开展数据爬虫时采用代理也不可以肆无忌惮的进行数据收集。是因为各大网站都是有反爬虫的机制,以便更加安全稳定的数据收集要调节爬虫的速度,能够多个爬取,提升工作效率。