Azkaban介绍
Azkaban 是由 Linkedin 公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban 使用 job 配置文件建立任务之间的依赖关系,并提供一个易于使用的 web 用户界面维护和跟踪你的工作流。
Azkaban 功能特点:
- 提供功能清晰,简单易用的 Web UI 界面
- 提供 job 配置文件快速建立任务和任务之间的依赖关系
- 提供模块化和可插拔的插件机制,原生支持 command、Java、Hive、Pig、Hadoop
- 基于 Java 开发,代码结构清晰,易于二次开发
Azkaban安装部署
Azkaban的组成如下:

mysql服务器:用于存储项目、日志或者执行计划之类的信息
web服务器:使用 Jetty 对外提供 web 服务,使用户可以通过 web 页面方便管理
executor服务器:负责具体的工作流的提交、执行
Azkaban 有两种部署方式:solo server mode 和 cluster server mode
- solo server mode( 单机模式):该模式中 webServer 和 executorServer 运行在同一个进程中,进程名是 AzkabanSingleServer。可以使用自带的 H2 数据库或者配置 mysql 数据。该模式适用于小规模的使用。
- cluster server mode( 集群模式):该模式使用 MySQL 数据库,webServer 和executorServer 运行在不同进程中,该模式适用于大规模应用。
其实在单机模式中,AzkabanSingleServer 进程只是把 AzkabanWebServer 和AzkabanExecutorServer 合到一起启动而已。
准备安装包
Azkaban Web 服务器:
azkaban-web-server-2.5.0.tar.gz
Azkaban 执行服务器:
azkaban-executor-server-2.5.0.tar.gz
MySQL
本文档中默认已安装好 mysql 服务器。
下载地址: http://azkaban.github.io/downloads.html
上传安装包
将安装包上传到集群,最好上传到安装 hive、sqoop 的机器上,方便命令的执行。
新建 azkaban 目录,用于存放 azkaban 运行程序。
azkaban web服务器安装
解压 azkaban-web-server-2.5.0.tar.gz
命令: tar –zxvf azkaban-web-server-2.5.0.tar.gz
将 解 压 后 的 azkaban-web-server-2.5.0 移 动到 azkaban 目录 中 , 并 重 新 命名 webserver
命令: mv azkaban-web-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-web-server-2.5.0 server
azkaban执行服器安装
解压 azkaban-executor-server-2.5.0.tar.gz
命令:tar –zxvf azkaban-executor-server-2.5.0.tar.gz
将解压后的 azkaban-executor-server-2.5.0 移动到 azkaban 目录中,并重新命名 executor
命令:mv azkaban-executor-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-executor-server-2.5.0 executor
azkaban脚本导入
解压: azkaban-sql-script-2.5.0.tar.gz
命令:tar –zxvf azkaban-sql-script-2.5.0.tar.gz
将解压后的 mysql 脚本,导入到 mysql 中:
进入 mysql
mysql> create database azkaban;
mysql> use azkaban;
Database changed
mysql> source /home/hadoop/azkaban-2.5.0/create-all-sql-2.5.0.sql;
创建SSL配置(https)
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成 keystor 的密码及相应信息,输入的密码请劳记,
信息如下:
输入 keystore 密码:
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入<jetty>的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:
完成上述工作后,将在当前目录生成 keystore 证书文件,将 keystore 拷贝到 azkaban web 服务器根目录中.如:cp keystore azkaban/webserver
修改配置文件
注:先配置好服务器节点上的时区
先生成时区配置文件 Asia/Shanghai,用交互式命令 tzselect 即可
拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
azkaban web服务器配置
进入 azkaban web 服务器安装目录 conf 目录
修改 azkaban.properties 文件
#Azkaban Personalization Settings azkaban.name=Test #服务器 UI 名称,用于服务器上方显示的名字 azkaban.label=My Local Azkaban #描述 azkaban.color=#FF3601 #UI 颜色 azkaban.default.servlet.path=/index # web.resource.dir=web/ #默认根 web 目录 default.timezone.id=Asia/Shanghai #默认时区,已改为亚洲/上海 默认为美国 #Azkaban UserManager class user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类 user.manager.xml.file=conf/azkaban-users.xml #用户配置,具体配置参加下文 #Loader for projects executor.global.properties=conf/global.properties # global 配置文件所在位置 azkaban.project.dir=projects #
database.type=mysql #数据库类型 mysql.port=3306 #端口号 mysql.host=hadoop03 #数据库连接 IP mysql.database=azkaban #数据库实例名 mysql.user=root #数据库用户名 mysql.password=root #数据库密码 mysql.numconnections=100 #最大连接数
# Velocity dev mode velocity.dev.mode=false # Jetty 服务器属性. jetty.maxThreads=25 #最大线程数 jetty.ssl.port=8443 #Jetty SSL 端口 jetty.port=8081 #Jetty 端口 jetty.keystore=keystore #SSL 文件名 jetty.password=123456 #SSL 文件密码 jetty.keypassword=123456 #Jetty 主密码 与 keystore 文件相同 jetty.truststore=keystore #SSL 文件名 jetty.trustpassword=123456 # SSL 文件密码 # 执行服务器属性 executor.port=12321 #执行服务器端口 # 邮件设置 mail.sender=xxxxxxxx@163.com #发送邮箱 mail.host=smtp.163.com #发送邮箱 smtp 地址 mail.user=xxxxxxxx #发送邮件时显示的名称 mail.password=********** #邮箱密码 job.failure.email=xxxxxxxx@163.com #任务失败时发送邮件的地址 job.success.email=xxxxxxxx@163.com #任务成功时发送邮件的地址 lockdown.create.projects=false # cache.directory=cache #缓存目录
azkaban 执行服务器配置
进入执行服务器安装目录 conf,修改 azkaban.properties
#Azkaban default.timezone.id=Asia/Shanghai #时区 # Azkaban JobTypes 插件配置 azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 插件所在位置 #Loader for projects executor.global.properties=conf/global.properties azkaban.project.dir=projects #数据库设置 database.type=mysql #数据库类型(目前只支持 mysql) mysql.port=3306 #数据库端口号 mysql.host=192.168.20.200 #数据库 IP 地址 mysql.database=azkaban #数据库实例名 mysql.user=azkaban #数据库用户名 mysql.password=oracle #数据库密码 mysql.numconnections=100 #最大连接数 # 执行服务器配置 executor.maxThreads=50 #最大线程数 executor.port=12321 #端口号(如修改,请与 web 服务中一致) executor.flow.threads=30 #线程数
用户配置
进入 azkaban web 服务器 conf 目录,修改 azkaban-users.xml
vi azkaban-users.xml 增加 管理员用户
<azkaban-users> <user username="azkaban" password="azkaban" roles="admin" groups="azkaban" /> <user username="metrics" password="metrics" roles="metrics"/> <user username="admin" password="admin" roles="admin,metrics" /> <role name="admin" permissions="ADMIN" /> <role name="metrics" permissions="METRICS"/> </azkaban-users>
启动
web 服务器
在 azkaban web 服务器目录下执行启动命令
bin/azkaban-web-start.sh
注:在 web 服务器根目录运行
执行服务器
在执行服务器目录下执行启动命令
bin/azkaban-executor-start.sh ./
注:只能要执行服务器根目录运行
启动完成后,在浏览器(建议使用谷歌浏览器)中输入 https://服务器 IP 地址:8443 ,即可访问 azkaban 服务了.在登录中输入刚才新的户用名及密码(用户配置中添加的),点击 login.
Azkaban实战
Command类型单一 job示例
- 创建 job 描述文件
vi command.job
#command.job type=command command=echo 'hello'
- 将job资源文件打包成 zip文件

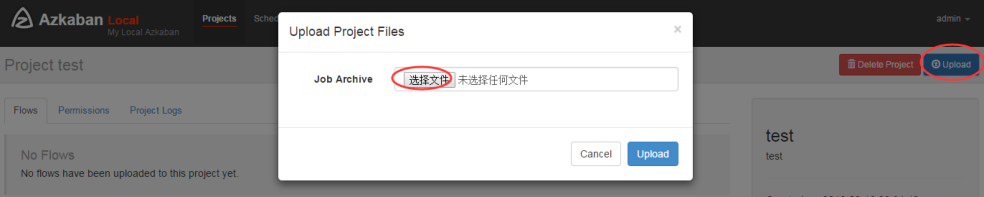
- 通过 azkaban 的 web 管理平台创建 project 并上传 job 压缩包
- 首先创建 Project

-
- 上传 zip 包
- 启动执行该 job

Command 类型多 job 工作流 flow
- 创建有依赖关系的多个 job 描述
第一个 job:foo.job
# foo.job type=command command=echo foo
第二个 job:bar.job 依赖 foo.job
# bar.job type=command dependencies=foo command=echo bar
- 将所有 job 资源文件打到一个 zip 包中

- 在 azkaban 的 web 管理界面创建工程并上传 zip 包
- 启动工作流 flow
HDFS操作任务
- 创建 job 描述文件
# fs.job type=command command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop fs -mkdir /azaz
- 将 job 资源文件打包成 zip 文件
- 通过 azkaban 的 web 管理平台创建 project 并上传 job 压缩包
- 启动执行该 job
MapReduce任务
mr 任务依然可以使用 command 的 job 类型来执行
- 创建 job 描述文件,及 mr 程序 jar 包(示例中直接使用 hadoop 自带的 example jar)
# mrwc.job type=command command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop jar hadoop-mapreduce- examples-2.6.1.jar wordcount /wordcount/input /wordcount/azout
- 将所有 job 资源文件打到一个 zip 包中

- 在 azkaban 的 web 管理界面创建工程并上传 zip 包
- 启动 job
HIVE脚本任务
- 创建 job 描述文件和 hive 脚本
Hive 脚本: test.sql
use default; drop table aztest; create table aztest(id int,name string) row format delimited fields terminated by ','; load data inpath '/aztest/hiveinput' into table aztest; create table azres as select * from aztest; insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
Job 描述文件:hivef.job
# hivef.job type=command command=/home/hadoop/apps/hive/bin/hive -f 'test.sql'
- 将所有 job 资源文件打到一个 zip 包中创建工程并上传 zip 包,启动 job