其实ResNet这篇论文看了很多次了,也是近几年最火的算法模型之一,一直没整理出来(其实不是要到用可能也不会整理吧,懒字头上一把刀啊,主要是是为了将resnet作为encoder嵌入到unet架构中,自己复现模型然后在数据集上进行测试所以才决定进行整理),今天把它按照理解尽可能详细的解释清楚跟大家一起分享一下,哪里没有说明白或者说错的,欢迎指出留言。
深度残差神经网络(Residual Networks)是2015年(12月在arxiv.org可下载)何凯明大神提出来的一个神经网络模型,获得了2015年多个竞赛数据集的第一。模型被提出主要是为了解决如下两个主要问题:
- 减缓深度学习模型难以训练的问题(e.g. 超过100层的神经网络)
- 模型退化(degradation problem)问题,这个之后会详细解释什么是退化(表示看了论文很迷茫,还是看了不少别人的博客才恍然大悟)
这里还有一点需要被注意的是,深度残差网络是基于这么一个假设:越深的网络理应具备更好的学习能力。这个后来也确实被证明层数的增加确实带来不一样的效果,不论以什么样的形式叠加和计算(如AlexNet、GoogLeNet、DenseNet等等)。
一、简要介绍
虽然假设越深的网络应该具备更好的表征学习能力,但是接踵而来的问题也很明显,如梯度消失和梯度爆炸(vanishing/exploding gradients)会阻碍收敛的情况。但是归一化(normalized initialization & batch normalization)都极大程度的缓解了梯度所带来的问题。相反的,深度学习网络所面对的不是收敛不收敛的问题,反而是随着层数的增加所面临的网络退化问题,原文如是说:with the network depth increasing, accuracy gets saturated and then degrades rapidly。需要注意的是网络的退化不是因为过拟合等导致的。
那什么是“退化”呢?这里主要分成两块来详细进行解释:
①随着网络训练层数的增加,退化问题会以正确性达到饱和程度,这是可预见或者说符合预期的。但是何为“可预见”呢?这主要是搭建网络的时候,一般期望足够深的网络是具备相应的学习能力的,以此来保证所创建的模型能足以良好地表征(modelling)数据中所有的特征。那么这个时候就会想,是否额外增加层数会加强网络的学习能力并使其能完全学习到数据中的所有特征。然而根据观察并不是如此,当网络层数的增加(层数增加在准确率饱和区间之后),网络的预测准确率不升反降。当然这个可以认为是过拟合导致的。但是如果不是过拟合导致的原因呢?

②假设现在有一个N层网络,它的训练误差为e1,对于另外一个网络M层网络(M > N),我们的期望是至少该M层网络的表现能力跟N层网络的表现能力是一致的。假设M层网络的前面部分网络是N层网络构成,然后剩下的M-N层网络由恒等映射网络构成,也就是说剩下的这些网络的每一层的输入和输出保持一致,没有任何多余的因素加入,这么做的原因是希望后续的网络能很好的学习前N层网络学习的结果,如果存在这么一个M层网络,就希望它具备更好的表征能力。但是事实却不是如此,上图来自于原论文,可以看出深层网络并没有带来更好的结果。这就是所谓的网络退化问题,也是ResNet提出来最主要要解决的问题。那ResNet是如何解决退化问题的呢?
二、残差模块
残差模块就是ResNet提出来解决退化问题的,其主要结构如下图所示。也就是说经过叠加的基层神经网络之后,原本前面的输出会和这几层叠加神经网络输出叠加(论文中称之为恒等映射)作为下一个叠加模块的输入。假设放到卷积神经网络中,它的表现形式就是(output + ((conv + bn + relu) + (conv + bn))) + relu。这么做有一个优势就是恒等映射并不会引入新的训练参数或者增加额外的计算开销。

除此之外,残差神经网络还具备如下两个有点:①比没有引入残差模块的普通叠加网络来说具备更好的收敛及更易于优化,②除此之外,对比一般残差网络能极大地提升训练和预测地准确度。下图是ResNet-34的网络结构图:
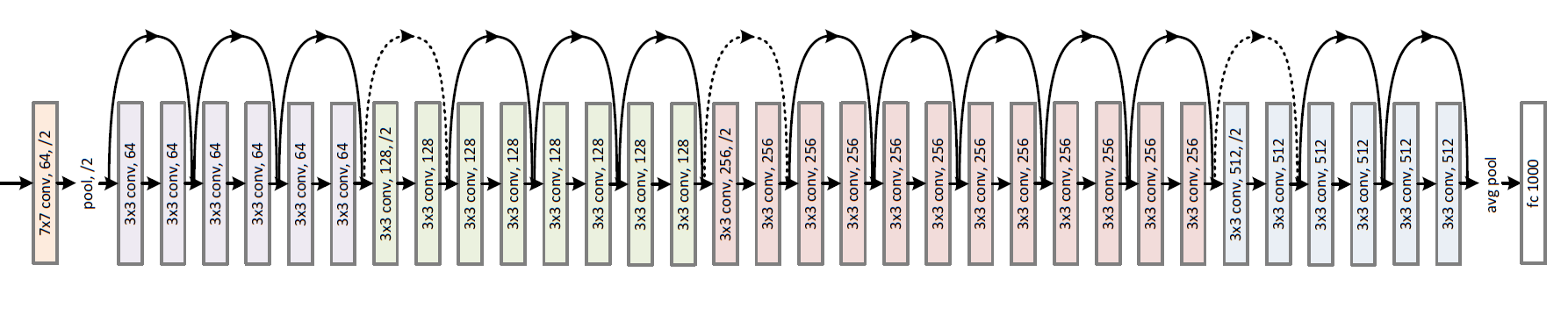
这里有些朋友对Highway Networks(15年5月)可能有了解觉得ResNet跟其是一个类型的网络,甚至有说ResNet就是变种的highway networks(这个跟论文的发布前后有关系,因为highway networks比resnet早几个月诞生,其实有点撞车的意味)。当然何凯明大神在论文中有指出他们跟highway networks的差别,主要体现在下两方面:
- highway network提出的short-cut connection with gating function是与数据独立开来的,并且有学习参数,而ResNet的identity mapping(恒等映射)是没有任何参数的;
- highway network没有提到任何关于深度网络(特别是100层以上的网络)所体现出来的性能和在特定数据上训练的结果(这点ResNet确实做得更好,其实深度学习领域相关的算法往往是先有实践后有理论,所以实验的论证是非常有必要的,ResNet在这上面做的实验是很充足,这点也反映在论文上面);