停更博客好长一段时间了,其实并不是没写了,而是转而做笔记了,但是发现做笔记其实印象无法更深刻,因此决定继续以写博客来记录或者复习巩固所学的知识,与此同时跟大家分享下自己对深度学习或者机器学习相关的知识点,当然浅薄之见如有说错表达错误的,欢迎大家指出来。废话不多说,进入今天的主题:Batch Normalization。
Batch Normalization(BN)是由Sergey Ioffe和Christian Szegedy在2015年的时候提出的,后者同时是Inception的提出者(深度学习领域的大牛),截止至动手写这篇博客的时候Batch Normalization的论文被引用了12304次,这也足以说明BN被使用地有多广泛。在正式介绍BN之前,有必要了解下feature scaling(特征归一化),这是不论做传统机器学习也好或者现在深度学习也好,预处理阶段可以说是必不可少的一步也是确保模型能够正常学习非常重要的一步。
1、为什么需要使用feature scaling?
Feature scaling指的是对输入的数据特征进行归一化操作(一般有min-max normalization或者min-max standardization两种)以确保所有特征的值处于同一维度。假设现在有x1和x2是两个特征,从公式a = Sigmoid(WTX + b)计算loss可以知道,如果x1和x2的特征值差别很大的话但是假设他们对结果的影响力一致的话(如下图所示),那么意味着w1的数值维度会比较大, w2的数值维度则会比较小,而如果要使w1和w2有一个同等的变化(如果这样子需要设置不同的learning rate进行更新,针对w2的步长要设置编辑哦大而w1比较小来更新,以此来使模型的loss达到收敛,参照图2来理解,这里要稍微想象一下,我最开始也比较困惑为什么使如此),那么意味着x1w1的结果就比较小,而x2w2的结果会比较大(根据个人建模的经验来说,如果特征数值维度差别很大的话,一般模型很难训练,直白点说就是loss几乎不收敛,可能刚开始收敛,后面就乱串了,有其他经历的朋友可以留言告知下)。由此可以影响训练速度和精度,因为针对不同的特征,需要不同的学习率来调整,由此拖慢了训练速度。
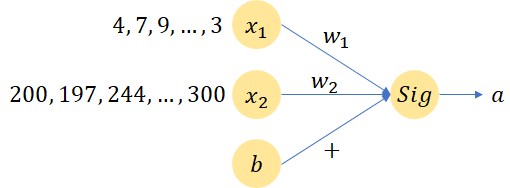
图1 简单的神经元计算流程
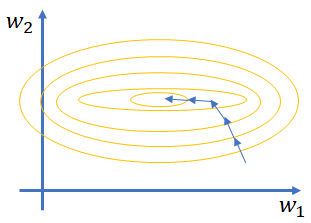
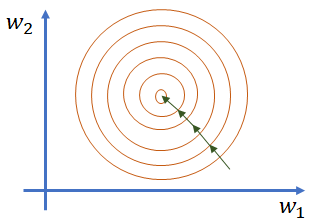
图2 特征值差异较大时的训练过程(左)和特征值大小处于同一维度的训练过程(右)
一般的feature scaling是如何做呢?计算每个dimension的mean和每个dimension的std(feature scaling之后的每一维的值的均值为0,方差为1),做feature scaling之后梯度下降收敛会快点。当对输入的特征做完feature scaling之后,不免会引起一定困惑,那就是在神经网络中由于网络结构含有多层隐藏层,每一层隐藏层的输出是下一层的输入,那么这些隐藏层的输入(下面统一用这种说辞,避免混淆)是否需要也进行feature scaling呢?经过Sergey Ioffe和Christian Szegedy的验证答案是肯定的。
2、神经网络中隐藏层为什么要做feature scaling?
2.1 Internal Covariate Shift
在正式进入正题之前,同样十分有必要解释下Internal Covariate shift(ICS)是什么以及对深度学习训练模型的影响?在此之前,又得再先确认一个概念,那就是:深度学习和机器学习在进行模型训练的时候都是基于数据IID(Independently identically distribution,独立同分布)的情况。那什么是独立同分布呢?独立(两个事件没有关联)意味着数据之间(一般指训练数据和测试数据,测试数据一般又指未见过的数据)是相互独立的,同分布则指明数据具有相同分布形状并且具有相同分布的参数(这里可以想象下为为什么针对采样自统一分布的数据进行模型训练和学习,例如想象下参数的变化,数据集拆分符合分布规律等等,也就能明白IID是如何影响深度学习模型和机器学习模型的),更直观点说就是选取用于训练的数据要具有全局代表性,以便可以对未知的数据进行预测。
那什么又是ICS呢?在神经网络的设计往往都是含有多个隐藏层,而像之前说的当前隐藏层的输出是下一个隐藏层的输入,把这个输入当作一个分布来看的话,而由于为了使训练收敛参数不断处于更新之中,当前隐藏层的参数更新之后会影响下一个隐藏层的输入,也就是说由于参数的改变,输入改变了(也就是分布改变了),这个跟基于IID的假设是相违背的,出现这种现象则称之为ICS(可通过设置小一点的学习率可以改善,但是小的学习率影响训练速度因为步长变短了)。
2.2 Batch Normalization
为了降低ICS所带来的影响,BN就被提出来了。这里我们来看下通常神经网络结构是如何设计的: x with feature scaling -> layer1 -> a1(feature scaling?) -> layer2 -> a2(feature scaling?) 。那既然是叫Batch Normalization,那么就意味着这个normalization是针对一个Batch一个batch的。这里再复习下Batch训练的一些基本原理,batch的意思是训练网络的时候一次性拿几个样本并行的做计算,比如batch=4,那么就是四个样本作为输入一起乘上同一个参数(如下图3所示)。
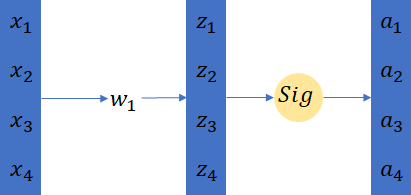
图3 Batch Training
实际运算中,batch=4的四个样本会被拼成一整个matrix,这里从编程的角度想想会更好理解,例如要对1万张图片进行训练,选取batch=4,假设每个图片的高和宽为224和224,通道数为3,那么他们的shape就是(4,224,224,3),这个用numpy或者PyTorch或者TensorFlow来在电脑上展示出来都是一个矩阵。Batch normalization是如何作用在batch上的呢?一般是先BN后activation,如果先做activation再做BN的话,input就有可能落在saturation值域上(tanh和sigmoid都容易存在这个问题),那么就会产生gradient vanishing(梯度消失)的问题。接下来看看Batch Normalization的计算,一般是基于batch计算μ和σ的(均值和标准差),由于整个数据集量很大,如果是针对整个数据集计算μ和σ的话,那么计算开销很大,所以BN是作用在batch上的数据,这也由此引申出一个问题,那就是在使用BN的时候,batch应该尽量设置比较大(batch < n where n is the number of samples),BN的计算演示图如下图所示:

图4 引入BN的神经网络结构图
那么使用BN的话怎么进行训练呢?使用BN的时候,在做BP的时候也同样需要去更新计算出来的batch的μ和σ,因为μ和σ也会影像training loss。在经过BN之后,数据的值的分布是服从mean为0,方差为1的。但是有时候并不是服从这样子的分布才是网络更robust,所以此时希望对做了BN之后的数值做一个scale和偏移。这也就是论文中的β和γ存在的因素。但是仔细的人应该可以看出来,最后一个公式是计算μ和σ的来normalize输入的逆过程,如果当μ、σ(calculated from batch)和γ(缩放)、β(平移)一样的话,就等于BN没有任何作用。但是此时需要注意的是,μ和σ是受到每一层的输入的影响的,但是γ和β是独立的,不受输入的影响,并且γ和β是整个网络的参数。通过上面的讲述,可以清楚看到BN在训练神经网络模型的过程中引入了(更正)两个新的需要被训练的参数:γ和β(与此同时μ和σ会根据输入的Batch做更新)。这里有一点需要注意的是加入缩放和平移的主要原因是:保证数据每一次数据经过归一化后还能保有原有学习来的特征,同时完成归一化操作加速训练。下图是来自论文的上述参数的每个计算公示:

图5 原论文中的计算公式
使用BN在测试阶段同样会遇到一个问题,因为我们知道在training的时候是一个Batch一个Batch进行训练的,但是测试的时候(做预测时)是没有所谓的batch之说的。这个时候一个比较实用的操作就是计算在训练过程μ和σ的moving average,并且让在靠近训练结束的位置占比较大的权重,而刚开始训练的时候占比较小的权重。
最后,来看看使用BN所带来的好处都有哪些:
- 减少训练时间,这是因为ICS所带来的的影响减小了,由此可以使用较大的学习率;
- 避免梯度爆炸或者梯度消失(尤其在使用sigmoid和tanh这类激活函数的时候);
- 学习率受参数初始化的影响减小;
- 让训练的模型不那么容易过拟合(overfitting);
- 减少对正则化的依赖(如减少使用dropout);
而BN的坏处也是显而易见的:
- BN所求得的均值和方法是为了能使输入的batch数据分布能代表整个网络,这个时候我们往往希望Batch尽可能地大以保证其代表性,但是如果batch太小,则计算出来地均值和方查无法代表整个数据分布,此时模型的表现就有可能差强人意;
- Batch尽可能地大又会导致其他问题的产生,那就是有可能导致输入的数据量超过了内存的大小、训练时间不减反降;