论文的关注点在于如何提高bounding box的定位,使用的是概率的预测形式,模型的基础是region proposal。论文提出一个locNet的深度网络,不在依赖于回归方程。论文中提到locnet可以很容易与现有的detection系统结合,但我困惑的是(1)它们的训练的方法,这点论文中没有明确的提到,而仅仅说用迭代的方法进行(2)到底两者的融合后两个网络的结构是怎样呢?可以看做一个多任务的系统,还是存在两个网络呢?
检测方法
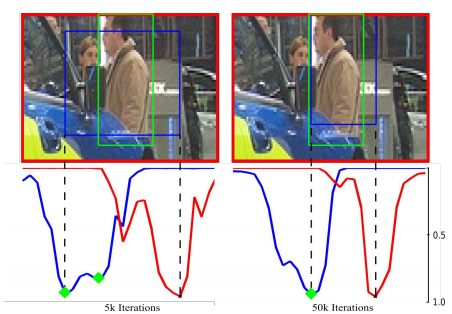
输入的候选bounding box(使用selective search或者sliding windows获得),通过迭代的方法,获得更精确的box。检测的由两个过程组成:识别模型(recognition model)以及定位模型(localization model)。识别模型为每个box计算一个置信度(confidence score),度量定位的准确性,定位模型调整box的边界生成新的候选box,再输入到识别模型中。伪代码如下,

可以看到,在识别模型中,会根据计算的置信度删除其中一些box,这样做的目的是为了减少计算的复杂度。但从过程可以看出,置信度对于定位模型几乎没有用,这个迭代的过程识别模型的计算好像没有必要。
定位模型
但上述并不是关心的重点,主要是看看这个提升定位准确性的方法。提出的locnet模型步骤总结如下
(1)对于输入的box,把它扩大一个因子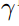 的倍数,获取一个更大的区域R,把R投影到feature map中。
的倍数,获取一个更大的区域R,把R投影到feature map中。
(2)经过一个类似于ROI pooling的层,输出固定大小的map。在这里需要展开说明。把一个区域划分成M*M的格子,这时可以产生两个向量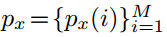 和
和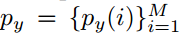 ,分别代表区域R的每一行或者列包含在bounding box中的概率,如图(左)。例如,对于ground truth box而言,对于边界内的行或列概率为1,否则为0,
,分别代表区域R的每一行或者列包含在bounding box中的概率,如图(左)。例如,对于ground truth box而言,对于边界内的行或列概率为1,否则为0,
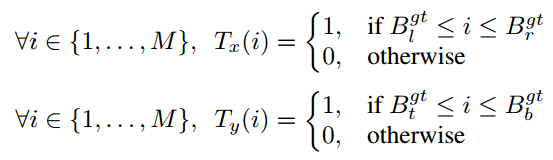
其中B代表四条边界l,r,t,b。这个称谓In – Out 概率。
除此以外,还定义了边界概率。即行或列是边界的概率。对于ground truth box,有

(3)经过几个卷积层和ReLU激活之后,出现两个分支,分别对应两个向量。然后经过max pooling得到row、column对应的向量。
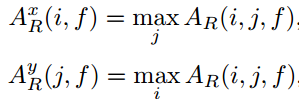
(4)经过FC层之后,使用sigmoid函数输出In –Out概率或者边界概率或者两者都输出。

损失函数
最重要的是定义损失函数了。使用的是伯努利分布的模型,即每行或列有两种可能(是或者不是),取对数后,这也是logistic 回归常用的损失函数交叉熵,对于In –Out概率有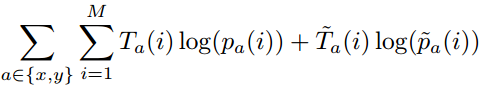
其中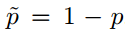 ,对于
,对于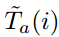 同理。对于边界概率有
同理。对于边界概率有
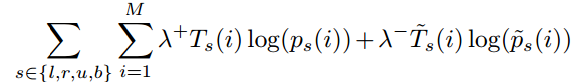
这里有两个平衡因子,因为作为边界的行或列较少,所以增大他们的权重,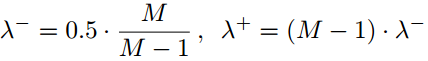
。
问题引入:对于整个模型,让人觉得奇怪的最后分支对应的row和column的max pooling的情况,竟然可以通过这样蕴含边界的信息,真的搞不明白为什么。这让人思考pooling这个操作究竟为什么这么牛逼,无所不能的样子。知乎上有人问过这个问题:CNN网络的pooling层有什么用,图像分类中的max pooling和average pooling是对特征的什么来操作的,结果是什么?但好像得出结论是,这是一个拍脑袋的结果……而对此系统分析的论文《A Theoretical analysis of feature pooling in Visual Recognition》也说这是一个经验的操作,而且貌似论文结果也没得出为什么来……
论文《A Theoretical analysis of feature pooling in Visual Recognition》的笔记,当一回搬运工,主要是记录Pooling Binary Feature部分,后面的已经看不明白了,最终得出结论是:Pooling 可以把联合特征转变为一个更重要的表示,同时忽略其他无关的细节。
简单起见,假设 服从伯努利分布,则均值池化操作为
服从伯努利分布,则均值池化操作为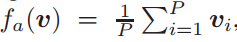 ,最大化池化操作
,最大化池化操作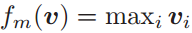 。
。
论文中讨论的是分布的可分性,给定两个类别C1、C2,则计算可分性的两个条件分布(最大值池化)为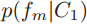 和
和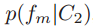 ,均值池化
,均值池化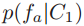 以及
以及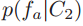 。虽然是给定类别下的条件分布,但事实上也隐含着它属于某个类别的概率,即后验。因此可以用来计算两个分布的可分性。
。虽然是给定类别下的条件分布,但事实上也隐含着它属于某个类别的概率,即后验。因此可以用来计算两个分布的可分性。
使得两个分布可分性增大的方法是,使他们的均值期望距离增大,或者使得他们的样本标准差变小。
对于均值池化,因为前面假设服从伯努利分布,所以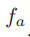 的分布(注意此时不是条件概率分布,对于条件概率分布,它们各自下的均值
的分布(注意此时不是条件概率分布,对于条件概率分布,它们各自下的均值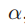 会不同)均值为
会不同)均值为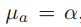 ,但是方差变小了为
,但是方差变小了为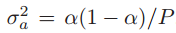 。
。
对于最大值池化,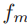 的均值为
的均值为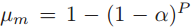 ,方差为
,方差为 。定义
。定义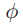 为类条件下的可分性,对于均值的距离为
为类条件下的可分性,对于均值的距离为
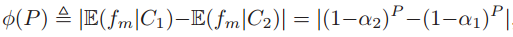
其中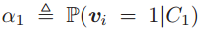 以及
以及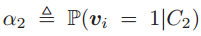 。上式是P的函数,把P扩展到实数域,可以得到
。上式是P的函数,把P扩展到实数域,可以得到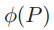 的最值点为
的最值点为
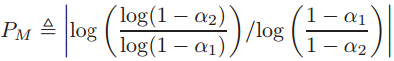
函数先升后降,极限为0。假设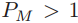 ,当P=1时就是均值的期望距离,此时会有许多的P,可以使得距离增大。假设
,当P=1时就是均值的期望距离,此时会有许多的P,可以使得距离增大。假设 ,如果
,如果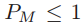 ,可以推出
,可以推出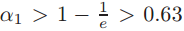 ,这表明它的一个选择的特征代表超过半数的图像中的patch(这句话我的理解是,因为
,这表明它的一个选择的特征代表超过半数的图像中的patch(这句话我的理解是,因为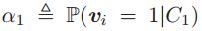 即类别下选择/生成特征的概率,即激活的概率过高),但通常而言这个不会发生在codebook包含超过100个codeword的时候(因为
即类别下选择/生成特征的概率,即激活的概率过高),但通常而言这个不会发生在codebook包含超过100个codeword的时候(因为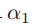 很高)。
很高)。
对于最大值池化的方差,同样会经历一个先升后降的过程。
据以上,论文总结了几个点:
1、最大池化特别适合在特征都是非常稀疏的时候来分离(即,有着非常低的概率去激活,这时很少出现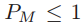 的情况)
的情况)
2、使用所有可用的样本去执行池化也许不是最优的
3、最优化池化技术会随着字典的尺寸增加而增加。