论文的重点在于后面approximation部分。
在《Rank Pooling》的论文中提到,可以通过训练RankSVM获得参数向量d,来作为视频帧序列的representation。而在dynamic论文中发现,这样的参数向量d,事实上与image是同等大小的,也就是说,它本身是一张图片(假如map![]() 与image同大小而不是提取的特征向量),那么就可以把图片输入到CNN中进行计算了。如下图可以看到一些参数向量d pooling的样例
与image同大小而不是提取的特征向量),那么就可以把图片输入到CNN中进行计算了。如下图可以看到一些参数向量d pooling的样例

参数向量d的快速计算
把计算d的过程定义一个函数![]() 。一个近似的方法是初始化
。一个近似的方法是初始化![]() ,通过梯度下降的方法求解d的最优值
,通过梯度下降的方法求解d的最优值
![]()
![]() ,最终可以得到,
,最终可以得到,

把上式展开得

其中![]() 。在这里
。在这里![]() ,于是结果为
,于是结果为![]() 。
。
Dynamic Maps Network

可以看到rank pooling操作把多个image的信息pooling到一张image。上图的结构中,可以看到rank pooling的操作要么直接作用在输入的image上,要么作用在经过多层CNN提取的feature image上,因此可以把pooling 操作定义如下函数
![]()
可以把pooling层表达成一个线性的组合 ,由于Vt是一个线性函数
,由于Vt是一个线性函数![]() ,于是重写
,于是重写

可以看到函数![]() 本身也依赖于
本身也依赖于![]() ,对于BP算法的求导而言是很困难的。
,对于BP算法的求导而言是很困难的。
使用近似的方法
从近似计算参数向量d的方法中可以看到,系数 是独立于image的。直接使用d的近似计算
是独立于image的。直接使用d的近似计算 来替代计算的线性组合,则BP算法后向传播时可以看到偏导数的解为
来替代计算的线性组合,则BP算法后向传播时可以看到偏导数的解为

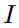 是一个单位矩阵。很明显,是一个常数。
是一个单位矩阵。很明显,是一个常数。
总结
个人认为,近似的方法很巧妙,实验结果也挺好的,但近似的方法好像不大合理的样子……