密集轨迹的方法是通过在视频帧上密集地采样像素点并且在追踪,从而构造视频的局部描述子,最后对视频进行分类的方法依然是传统的SVM等方法。
生成密集轨迹:
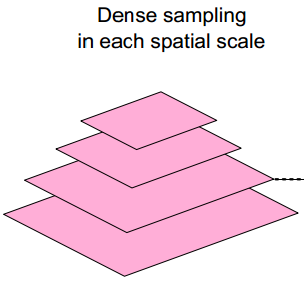
(1)从8个不同的空间尺度中采样,它们的尺度差因子为![]() ,而采样的点只需要简单地每间隔W = 5个像素取一个点即可。
,而采样的点只需要简单地每间隔W = 5个像素取一个点即可。
(2)对于下一个点位置的估计,通过估计密集光流场获得,有以下计算公式:![]()
,其中M是均值过滤器,![]() 就是计算的光流场,
就是计算的光流场,![]() 是Pt周围的点。这样可以对采样点逐帧追踪。
是Pt周围的点。这样可以对采样点逐帧追踪。
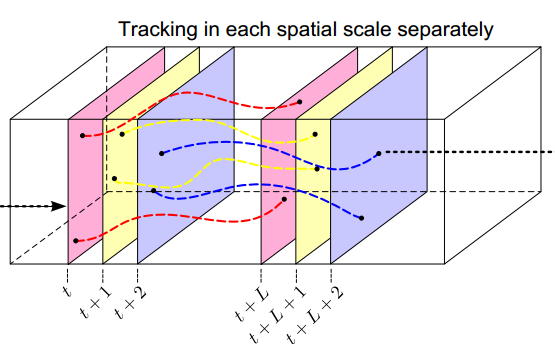
(3)为了防止轨迹点的漂移,密集轨迹最多追踪L帧。当在一个W*W的邻域内没有发现追踪点,那么采样一个点。
(4)在均匀的图像区域,是不需要去追踪点的。对于每一个特征点,计算它自相关矩阵的最小特征值(特征值意味着变化的情况,这里其实搞的不是很明白),因为此处只对动态的信息感兴趣。
(5)构造轨迹编码局部的动作模式,通过偏移量序列![]() 描述这条轨迹。这样的描述子应该也作为视屏描述子的一部分的。如果把它归一化,可以得到
描述这条轨迹。这样的描述子应该也作为视屏描述子的一部分的。如果把它归一化,可以得到
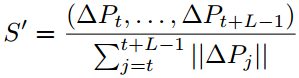
沿轨迹的描述子:(如下图)
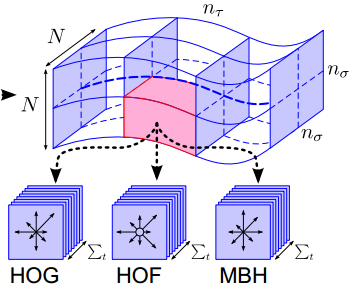
1、 HOGHOF描述特征

2、MBH特征

SVM分类器:
使用BOF的方法,构造word,最后使用SVM分类器进行视频的分类。