Knowledge Distillation
论文地址:https://arxiv.org/pdf/1503.02531.pdf
知识蒸馏指的是一种模型的压缩方法。
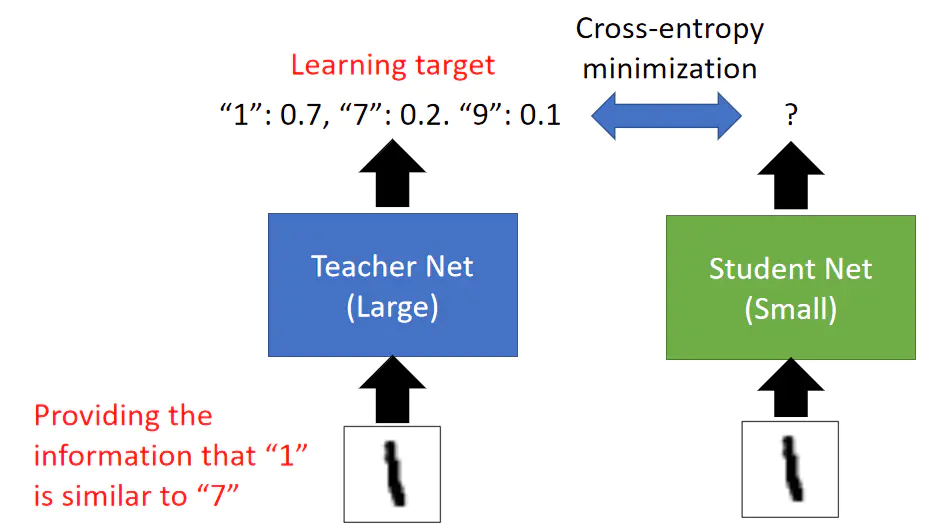
知识蒸馏的方式就是将Teacher Network输出的soft label作为标签来训练Student Network。
比如在上图中我们训练Student Network来使其与Teacher Network有同样的输出。
这样的好处是Teacher Network的输出提供了比独热编码标签更多的信息,比如对于输入的数字1,Teacher Network的输出表明这个数字是1,同时也表明了这个数字也有一点像7,也有一点像9。
另外训练Student Network时通常使用交叉熵作为损失函数,这是因为训练过程相当于要拟合两个概率分布。
知识蒸馏训练出的Student Network有一点神奇的地方就是这个Network有可能辨识从来没有见过的输入,
不如把Student Network的训练资料中的数字7移除后可能训练完成后也会认识数字7,这是因为Teacher Network输出的soft label提供了额外的信息。
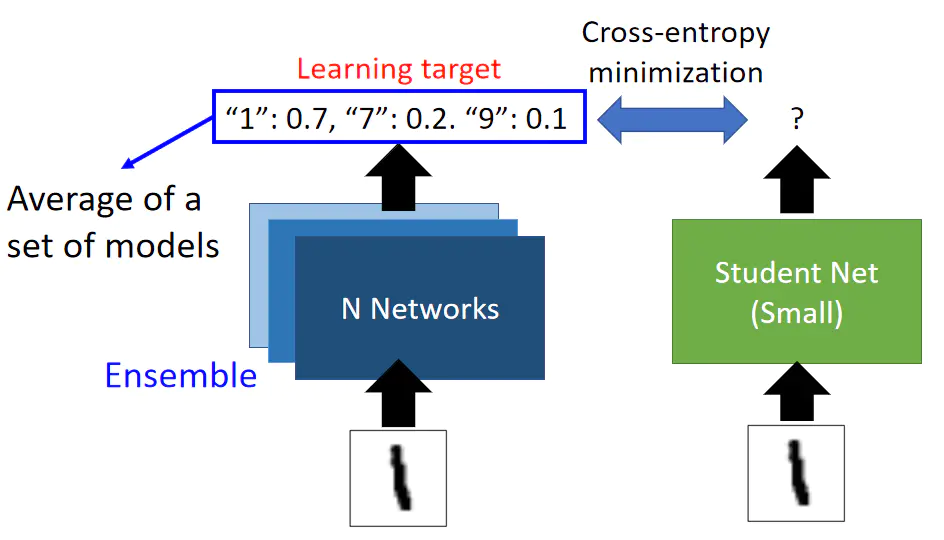
知识蒸馏的一个用处是用来拟合集成模型,有时候我们会集成(Ensemble)很多个模型来获取其输出的均值从而提高总体的效果,我们可以使用知识蒸馏的方式来使得
Student Network学习集成模型的输出,从而达到将集成模型的效果复制到一个模型上的目的: