1. 大数据治理平台架构

2. 数据处理环节详细流程架构
V1.0流程架构
说明:初版为了开发效率和快速验证流程,将原始kafka的数据写入hive原始表,写入hive标准表,写入kafka标准topic。每一类数据对应一个kafka原始topic,对应一个hive原始表,对应一个hive标准表,针对于特定的需要做实时轨迹分析的业务每一类数据对应一个kafka标准topic。这里只说明这三个环节的方案。因为从标准库入ES,Hbase,Clickhouse相对不复杂
入原始库流程:
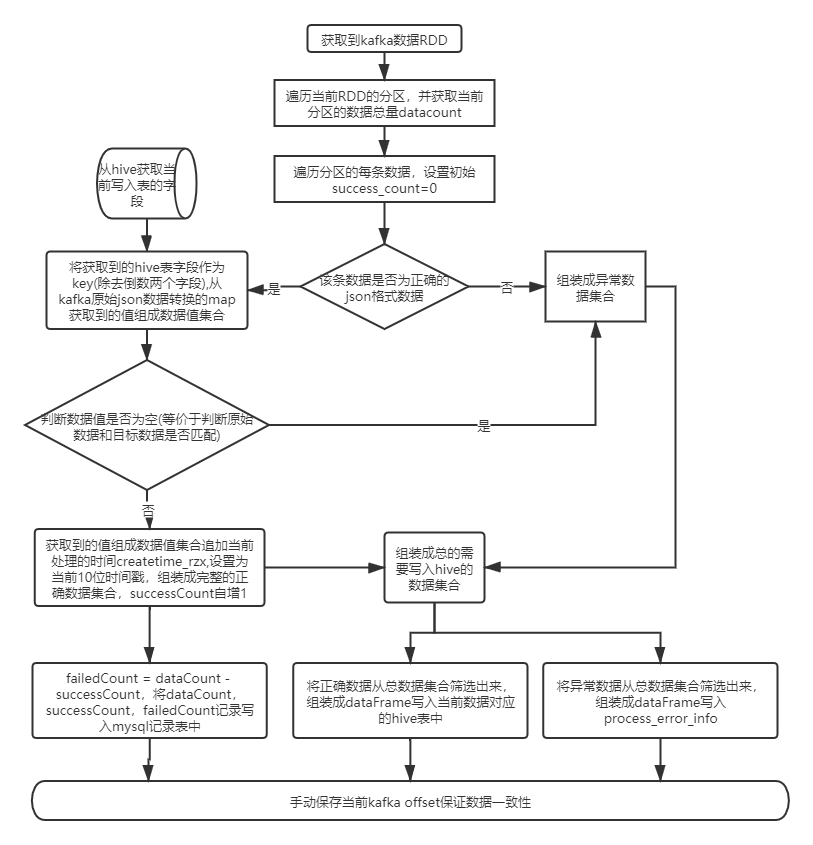
入标准库流程:
入标准topic流程:

V2.0流程架构
说明,在V1.0基础实践中发现存在如下几个问题:
a.数据种类的过多导致原始kafka的topic过多,按一类数据一个topic一个任务的方式处理会造成spark任务过多,导致yarn资源不足。所有类数据topic统一处理会带来某类数据异常导致整个任务对数据的处理的影响,排查甄别出哪类数据导致的异常非常繁琐。
b.原始kafka的topic过多带来的对kafka维护成本过高,入保证kafka数据的一致性。
c.多类数据统一处理也不符合按照数据类别为一个实体的思想
基于以上问题,V2.0版本采用数据总线的方式,做了如下改善方案
a.针对入原始表的所有类别数据,统一入到一个总的topic。针对于特定的需要做实时轨迹分析的业务所有类型的原始数据统一入到一个总的原始kafka的topic,kafka的原始数据是json格式的,在原有的json格式添加一个key/value,记录当前数据的来源。这样的方式不但能节省yarn资源提高性能,同时分发写入各个原始库个kafka标准topic也比较方便。
b.V1.0标准库是从kafka原始topic中处理写入,V2.0中,hive标准库从hive原始库中获取,将流式计算转化为离线计算,避免了流式计算中某些时段没有数据导致的资源浪费,整体上性能比流式计算要好,因为有数据就处理,无数据就不处理。
入原始库流程:

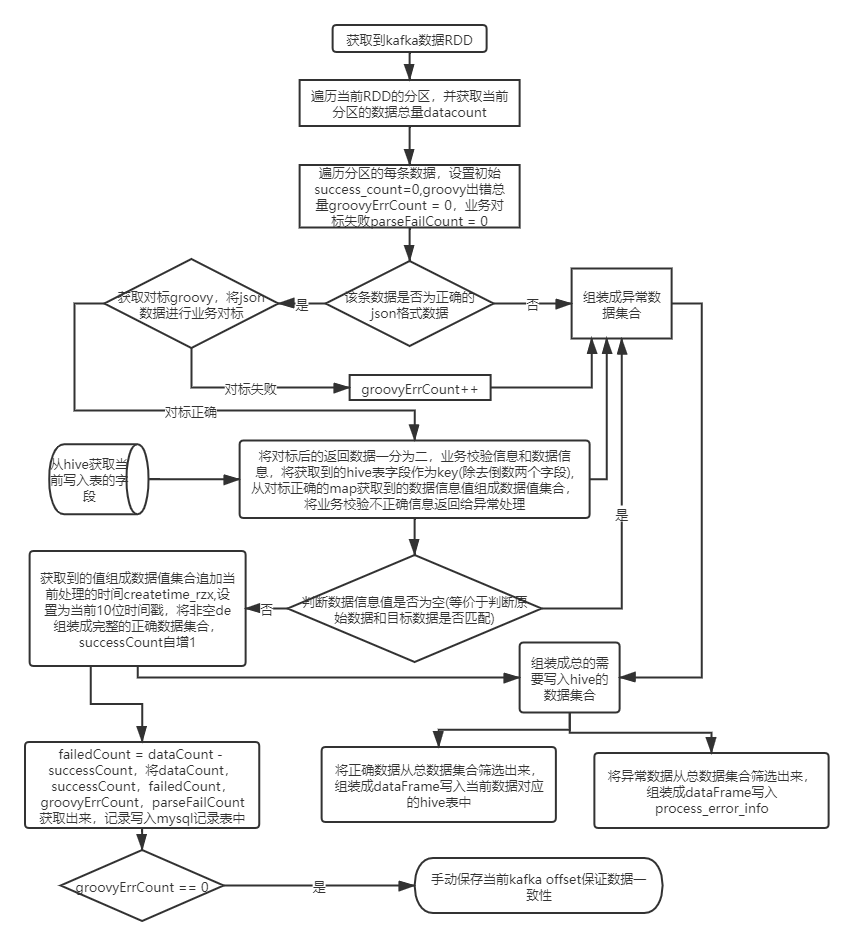
从原始库入标准库:

入标准topic流程:
该逻辑与入原始库一致,因为篇幅原因不做展示。结合V1.0版和V2.0版的入原始库流程就可以明白