1.写在前面
在大数据流式和实时数据计算方面,目前大多采用`kafka+spark streaming`和`kafka+flink`,这两种方式的不同在于组件的不同,spark是离线批和流式一体的大数据分布式计算引擎,而flink最初是为流式和实时计算而生的,所以在流式和实时上更加有优势。而随着flink不断的更新逐渐对批的支持也非常好。这两种方案在企业业务应用中采用任一种即可。
对于基于kafka或其他消息队列的流式和实时计算,保证数据一致性是至关重要的,是保证数据质量的前提。而相对于离线的批处理计算,流式和实时计算在保证数据的一致性较难一些。因为批处理一批计算完后,数据仍然存在分布式文件系统HDFS中,如果确保了这一批数据通过计算引擎组件计算完好到大数据处理的下一个环节,并且下一个环节的数据质量不存在问题,那么可以将这批数据从HDFS删除或者按照周期性保存,反之计算不正确,下游的数据质量有问题,那么只需要更改做些对应的调整,再次消费即可。而对于基于kafka的流式和实时计算,则需要对计算引擎消费kafka的数据做一个监测,从而确保是否对kafka的每一条数据或者每一批数据对应的offset提交,对于不懂`kafka offset`可以自行去apche官方去查看kafka的官方API和文档。而本篇博文主要是介绍`kafka+spark streaming`这个方案如何保存数据的一直性和数据质量。
2.方案及逻辑流图
2.1.方案
第一点:需要明白kafka的底层机制及工作原理,这里只简要说明,详细的参考kafka官网。kafka是将每一条写入kafka的数据按分区分布存储,将每条写入的数据作一个offset标记,这个标记的顺序是按插入数据自增的。当消费程序的时候,会按照分区区分,逐个根据offset顺序消费。当在消费数据时,如果将自动提交offset参数设置为true(enable.auto.commit=true),那么不管消费数据的结果是否正确,只要消费数据程序没有因为异常而中断,kafka都会讲数据的offset信息按照分区组合的方式存在依赖的zookeeper上。反之当enable.auto.commit=false时,消费程序及时消费结果正确,程序没有中断都不会提交offset,需要程序手动提交offset。举一个场景,如果消费程序没有出现异常,但消费数据的结果不对,应该是不提交offset的,当优化了流式消费程序,在启动消费程序,应该必须能消费到之前消费结果不对的数据。但是前者已经提交了offset,没法拿到了。而后者能够很好的解决这个问题,提交与不提交offset,由消费程序自己决定。
第二点:需要清楚spark的底层机制,这里做简要说明,详细的参考spark官网。spark在对数据进行分布式计算时(不管是流式还是离线批),都是将数据读成RDD,然后在对RDD进行spark自带算子计算和spark的方法API进行业务处理,而这两种本质上是一样的。这里以计算数据写入下游某个组件举例重点说方法API。一般情况下,spark都是将获取的数据RDD做如下操作:
1>.先对rdd进行foreach得到每个Partition
2>.在对每个Partition进行遍历得到Partition里面的数据,这里是一个迭代器(iterator),iterator里面就是实际每一条数据
rdd.foreachRDD(new VoidFunction<JavaRDD<String>>() {
@Override
public void call(JavaRDD<String> partition) throws Exception {
partition.foreachPartition(new VoidFunction<Iterator<String>>() {
@Override
public void call(Iterator<String> iterator) throws Exception {
while (iterator.hasNext()) {
String message = iterator.next();
}
});
}
});
明白一二两点后就需要思考spark streaming消费kafka数据时如何保存数据一致性,怎样去保证。这里其实不难,有两种方式:
第一种:将spark获取到的kafka数据转化成的rdd对应的kafka的offset全部拿出来,以rdd为实体,当`rdd.foreachRDD`整个无误后手动提交offset
第二种:在`rdd.foreachRDD`里面的`partition.foreachPartition`里面将每个partition对应的数据的kafka数据的offset查询出来,然后单个partition处理无误后提交单个partition对应的kafka数据的offset
第一种和第二种比较,他们的原理基本相同,第一种获取的offset其实也是第二种的数组,而第一种更加广义,第二种更加详细。
可能有读者会问,为什么不更加详细点,在`partition.foreachPartition`里面迭代每一条数据时,将每一条数据的offset获取出来,成功一条,提交该条对应的offset。为什么不这样做,有一下三点原因:
1>.分而治之,在保证数据质量的同时,要确保性能和其他指标,如果消费一条数据保存该数据的offset,势必会带来性能的影响。而按照分区的方式,一个分区里面的每一条记录都消费成功,证明这个分区处理是无误的,则提交offset。如果分区里的每一条和几条数据消费不成功,则认为该分区处理是不成功的,不提交offset,待修复后再一次消费这个partition对应的kafka的offset数据,这样肯定会造成数据重复,但一定不会造成数据遗漏。而大数据处理中,数据重复从来不是问题。但数据遗漏是不被允许的。
2>.spark streaming消费kafka数据的官方api中并没有这样的api,而是将partition作为一个整体的到offset的信息
2.2.逻辑流图
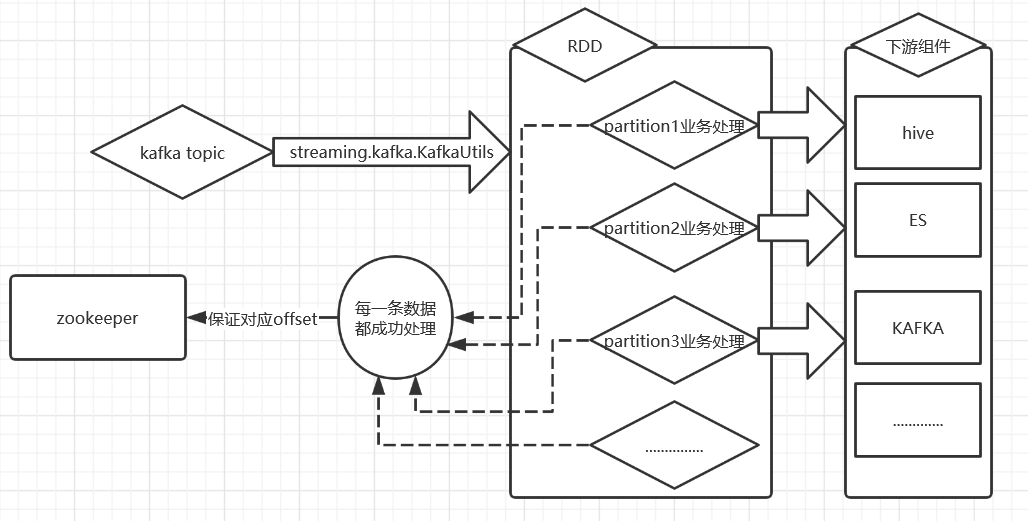
3.实现代码
这里以下游写回kafka为例
这里的版本为:kafka_2.10,spark_2.10
pom.xml引入必要的jar包
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.9.0.0</version>
</dependency>
具体实现
第一种:将spark获取到的kafka数据转化成的rdd对应的kafka的offset全部拿出来,以rdd为实体,当`rdd.foreachRDD`整个无误后手动提交offset
public class SparkStreamingKafkaToKafka{
public static void main(String args[]) throws Exception {
SparkConf conf = new SparkConf().setAppName("kafka-to-kafka-test");
setSparkConf(parameterParse, conf);
JavaSparkContext sparkContext = new JavaSparkContext(conf);
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkContext, Seconds.apply(Long.parseLong("50")));
String topic = "mytopic_test";
String saveTopic = "save_test";
final Broadcast<Map<String, Object>> kafkaParamsProducerBroadcast = sparkContext.broadcast(generatorKafkaParamsProduce());
//从kafka获取数据流
JavaInputDStream<String> dStream = KafkaUtils.createDirectStream(streamingContext, String.class, String.class,
StringDecoder.class, StringDecoder.class, String.class,
generatorKafkaParams(), generatorTopicOffsets(topic),
new Function<MessageAndMetadata<String, String>, String>() {
private static final long serialVersionUID = 1L;
@Override
public String call(MessageAndMetadata<String, String> msgAndMd) throws Exception {
return msgAndMd.message();
}
});
dStream.foreachRDD(new VoidFunction<JavaRDD<String>>() {
@Override
public void call(JavaRDD<String> rdd) throws Exception {
final AtomicReference<OffsetRange[]> offsetRanges = new AtomicReference<>();
final OffsetRange[] offsets = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
offsetRanges.set(offsets);
rdd.foreachPartition(new VoidFunction<Iterator<String>>() {
@Override
public void call(Iterator<String> iterator) throws Exception {
Producer<String, String> producer = new KafkaProducer<>(kafkaParamsProducerBroadcast.getValue());
while (iterator.hasNext()) {
String message = iterator.next();
if (!StringUtils.isEmpty(message)) {
Map<String, String> resultMap = (Map<String, String>) JSON.parse(message);
try {
ProducerRecord record = new ProducerRecord<String, String>(saveTopic, null, JSONObject.toJSONString(resultMap));
producer.send(record);
successCount++;
} catch (Exception e) {
e.printStackTrace();
}
}
}
producer.flush();
}
});
saveOffset(offsetRanges);
}
});
public static Map<String, String> generatorKafkaParams() {
Map<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("serializer.class", "kafka.serializer.StringEncoder");
kafkaParams.put("metadata.broker.list", "hadoop10:9092,hadoop11:9092,hadoop12:9092");
kafkaParams.put("zookeeper.connect", "hadoop10:2181,hadoop11:2181,hadoop12:2181/kafka");
kafkaParams.put("zookeeper.connection.timeout.ms", "10000");
kafkaParams.put("zookeeper.session.timeout.ms", "6000");
kafkaParams.put("zookeeper.sync.time.ms", "2000");
kafkaParams.put("group.id", "test");
kafkaParams.put("auto.offset.reset", "largest");
kafkaParams.put("auto.commit.interval.ms", "1000");
kafkaParams.put("fetch.message.max.bytes", "104857600");
kafkaParams.put("replica.fetch.max.bytes", "104857600");
return kafkaParams;
}
public static Map<TopicAndPartition, Long> generatorTopicOffsets(String topic) {
Map<TopicAndPartition, Long> topicOffsets = KafkaOffsetUtils.
getTopicOffsets("hadoop10:9092,hadoop11:9092,hadoop12:9092", topic);
Map<TopicAndPartition, Long> consumerOffsets = KafkaOffsetUtils.
getConsumerOffsets("hadoop10:2181,hadoop11:2181,hadoop12:2181/kafka",
"test", topic,
Integer.parseInt("10000"),
Integer.parseInt("6000"));
if (null != consumerOffsets && consumerOffsets.size() > 0) {
topicOffsets.putAll(consumerOffsets);
}
return topicOffsets;
}
public static void saveOffset(final AtomicReference<OffsetRange[]> offsetRanges) throws Exception {
org.codehaus.jackson.map.ObjectMapper objectMapper = new org.codehaus.jackson.map.ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString("hadoop10:2181,hadoop11:2181,hadoop12:2181/kafka")
.connectionTimeoutMs(Integer.parseInt("10000"))
.sessionTimeoutMs(Integer.parseInt("6000"))
.retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
for (OffsetRange offsetRange : offsetRanges.get()) {
final byte[] offsetBytes = objectMapper.writeValueAsBytes(offsetRange.untilOffset());
String nodePath = "/consumers/" + groupIdBroadcast.getValue()
+ "/offsets/" + offsetRange.topic() + "/" + offsetRange.partition();
if (null != curatorFramework.checkExists().forPath(nodePath)) {
curatorFramework.setData().forPath(nodePath, offsetBytes);
} else {
curatorFramework.create().creatingParentsIfNeeded().forPath(nodePath, offsetBytes);
}
}
curatorFramework.close();
}
public static Map<String, Object> generatorKafkaParamsProduce() {
Map<String, Object> kafkaParams = new HashMap<String, Object>();
kafkaParams.put("bootstrap.servers", "hadoop10:9092,hadoop11:9092,hadoop12:9092");
// 消息内容使用的反序列化类
kafkaParams.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaParams.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return kafkaParams;
}
}
第二种:在`rdd.foreachRDD`里面的`partition.foreachPartition`里面将每个partition对应的数据的kafka数据的offset查询出来,然后单个partition处理无误后提交单个partition对应的kafka数据的offset
public class SparkStreamingKafkaToKafka{
public static void main(String args[]) throws Exception {
SparkConf conf = new SparkConf().setAppName("kafka-to-kafka-test");
setSparkConf(parameterParse, conf);
JavaSparkContext sparkContext = new JavaSparkContext(conf);
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkContext, Seconds.apply(Long.parseLong("50")));
String topic = "mytopic_test";
String saveTopic = "save_test";
final Broadcast<Map<String, Object>> kafkaParamsProducerBroadcast = sparkContext.broadcast(generatorKafkaParamsProduce());
//从kafka获取数据流
JavaInputDStream<String> dStream = KafkaUtils.createDirectStream(streamingContext, String.class, String.class,
StringDecoder.class, StringDecoder.class, String.class,
generatorKafkaParams(), generatorTopicOffsets(topic),
new Function<MessageAndMetadata<String, String>, String>() {
private static final long serialVersionUID = 1L;
@Override
public String call(MessageAndMetadata<String, String> msgAndMd) throws Exception {
return msgAndMd.message();
}
});
dStream.foreachRDD(new VoidFunction<JavaRDD<String>>() {
@Override
public void call(JavaRDD<String> rdd) throws Exception {
final OffsetRange[] offsets = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
rdd.foreachPartition(new VoidFunction<Iterator<String>>() {
@Override
public void call(Iterator<String> iterator) throws Exception {
Producer<String, String> producer = new KafkaProducer<>(kafkaParamsProducerBroadcast.getValue());
OffsetRange offset = offsets[TaskContext.get().partitionId()];
long dataCount = offset.count();//数据总量
long successCount = 0;//写入成功总量
while (iterator.hasNext()) {
String message = iterator.next();
if (!StringUtils.isEmpty(message)) {
Map<String, String> resultMap = (Map<String, String>) JSON.parse(message);
try {
ProducerRecord record = new ProducerRecord<String, String>(saveTopic, null, JSONObject.toJSONString(resultMap));
producer.send(record);
successCount++;
} catch (Exception e) {
e.printStackTrace();
}
}
}
//根据offset将数据的处理结果写到mysql表中,如果dataCount=0,证明这一批流没有数据,不需要写
if (dataCount > 0) {
long failedCount = dataCount - successCount;//写入失败总量
if (failedCount == 0) {
saveOffsetSingle(offset);
}
}
producer.flush();
}
});
}
});
}
public static Map<String, String> generatorKafkaParams() {
Map<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("serializer.class", "kafka.serializer.StringEncoder");
kafkaParams.put("metadata.broker.list", "hadoop10:9092,hadoop11:9092,hadoop12:9092");
kafkaParams.put("zookeeper.connect", "hadoop10:2181,hadoop11:2181,hadoop12:2181/kafka");
kafkaParams.put("zookeeper.connection.timeout.ms", "10000");
kafkaParams.put("zookeeper.session.timeout.ms", "6000");
kafkaParams.put("zookeeper.sync.time.ms", "2000");
kafkaParams.put("group.id", "test");
kafkaParams.put("auto.offset.reset", "largest");
kafkaParams.put("auto.commit.interval.ms", "1000");
kafkaParams.put("fetch.message.max.bytes", "104857600");
kafkaParams.put("replica.fetch.max.bytes", "104857600");
return kafkaParams;
}
public static Map<TopicAndPartition, Long> generatorTopicOffsets(String topic) {
Map<TopicAndPartition, Long> topicOffsets = KafkaOffsetUtils.
getTopicOffsets("hadoop10:9092,hadoop11:9092,hadoop12:9092", topic);
Map<TopicAndPartition, Long> consumerOffsets = KafkaOffsetUtils.
getConsumerOffsets("hadoop10:2181,hadoop11:2181,hadoop12:2181/kafka",
"test", topic,
Integer.parseInt("10000"),
Integer.parseInt("6000"));
if (null != consumerOffsets && consumerOffsets.size() > 0) {
topicOffsets.putAll(consumerOffsets);
}
return topicOffsets;
}
public static void saveOffsetSingle(final OffsetRange offsetRange) throws Exception {
org.codehaus.jackson.map.ObjectMapper objectMapper = new org.codehaus.jackson.map.ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString("hadoop10:2181,hadoop11:2181,hadoop12:2181/kafka")
.connectionTimeoutMs(Integer.parseInt("10000"))
.sessionTimeoutMs(Integer.parseInt("6000"))
.retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
final byte[] offsetBytes = objectMapper.writeValueAsBytes(offsetRange.untilOffset());
String nodePath = "/consumers/" + "test"
+ "/offsets/" + offsetRange.topic() + "/" + offsetRange.partition();
if (null != curatorFramework.checkExists().forPath(nodePath)) {
curatorFramework.setData().forPath(nodePath, offsetBytes);
} else {
curatorFramework.create().creatingParentsIfNeeded().forPath(nodePath, offsetBytes);
}
curatorFramework.close();
}
public static Map<String, Object> generatorKafkaParamsProduce() {
Map<String, Object> kafkaParams = new HashMap<String, Object>();
kafkaParams.put("bootstrap.servers", "hadoop10:9092,hadoop11:9092,hadoop12:9092");
// 消息内容使用的反序列化类
kafkaParams.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaParams.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return kafkaParams;
}
}
对kafka offset操作的工具类
package com.surfilter.dp.timer.util;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import com.google.common.collect.ImmutableMap;
import java.util.Map.Entry;
import java.util.concurrent.atomic.AtomicReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryUntilElapsed;
import kafka.api.PartitionOffsetRequestInfo;
//import kafka.cluster.Broker;
import kafka.cluster.BrokerEndPoint;
import kafka.common.TopicAndPartition;
import kafka.javaapi.OffsetRequest;
import kafka.javaapi.OffsetResponse;
import kafka.javaapi.PartitionMetadata;
import kafka.javaapi.TopicMetadata;
import kafka.javaapi.TopicMetadataRequest;
import kafka.javaapi.TopicMetadataResponse;
import kafka.javaapi.consumer.SimpleConsumer;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.streaming.kafka.OffsetRange;
//import kafka.cluster.Broker;
public class KafkaOffsetUtils {
public static long getOffset(SimpleConsumer consumer, String topic, int partition, long whichTime, String clientName) {
TopicAndPartition topicAndPartition = new TopicAndPartition(topic, partition);
Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<TopicAndPartition, PartitionOffsetRequestInfo>();
requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(whichTime, 1));
kafka.javaapi.OffsetRequest request = new kafka.javaapi.OffsetRequest(
requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out.println("Error fetching data Offset Data the Broker. Reason: " + response.errorCode(topic, partition));
return 0;
}
long[] offsets = response.offsets(topic, partition);
// long[] offsets2 = response.offsets(topic, 3);
return offsets[0];
}
public static TreeMap<Integer, PartitionMetadata> findLeader(
String brokerHost, int a_port, String a_topic) throws Exception {
TreeMap<Integer, PartitionMetadata> map = new TreeMap<Integer, PartitionMetadata>();
SimpleConsumer consumer = null;
try {
consumer = new SimpleConsumer(brokerHost, a_port, 100000, 64 * 1024, "leaderLookup" + new Date().getTime());
List<String> topics = Collections.singletonList(a_topic);
TopicMetadataRequest req = new TopicMetadataRequest(topics);
kafka.javaapi.TopicMetadataResponse resp = consumer.send(req);
List<TopicMetadata> metaData = resp.topicsMetadata();
for (TopicMetadata item : metaData) {
for (PartitionMetadata part : item.partitionsMetadata()) {
map.put(part.partitionId(), part);
}
}
} catch (Exception e) {
throw new Exception("Error communicating with Broker [" + brokerHost
+ "] to find Leader for [" + a_topic + ", ]", e);
} finally {
if (consumer != null) {
consumer.close();
}
}
return map;
}
/**
* 为了解决kafka.common.OffsetOutOfRangeException
* 当streaming zk里面记录kafka偏移小于kafka有效偏移,就会出现OffsetOutOfRangeException
*
* @param topic 主题
* @param bootstrapServers kafka配置{e.g rzx162:9092,rzx164:9092,rzx166:9092}
*/
public static Map<Integer, Long> getEarliestOffset(String topic, String bootstrapServers) throws Exception {
String[] servers = bootstrapServers.split(",");
List<String> kafkaHosts = new ArrayList<String>();
List<Integer> kafkaPorts = new ArrayList<Integer>();
for (int i = 0, size = servers.length; i < size; i++) {
String[] hostAndPort = servers[i].split(":");
try {
String host = hostAndPort[0];
Integer port = Integer.parseInt(hostAndPort[1]);
kafkaHosts.add(host);
kafkaPorts.add(port);
} catch (Exception e) {
e.printStackTrace();
}
}
if (kafkaHosts.size() < 1) {
throw new Exception("parse bootstrapServers error!");
}
Map<Integer, Long> partionAndOffset = getOffset(topic, kafkaHosts, kafkaPorts, false);
return partionAndOffset;
}
/**
* 初始化到最新数据
*
* @param topic 主题
* @param bootstrapServers kafka配置{e.g rzx162:9092,rzx164:9092,rzx166:9092}
*/
public static Map<Integer, Long> getLastestOffset(String topic, String bootstrapServers) throws Exception {
String[] servers = bootstrapServers.split(",");
List<String> kafkaHosts = new ArrayList<String>();
List<Integer> kafkaPorts = new ArrayList<Integer>();
for (int i = 0, size = servers.length; i < size; i++) {
String[] hostAndPort = servers[i].split(":");
try {
String host = hostAndPort[0];
Integer port = Integer.parseInt(hostAndPort[1]);
kafkaHosts.add(host);
kafkaPorts.add(port);
} catch (Exception e) {
e.printStackTrace();
}
}
if (kafkaHosts.size() < 1) {
throw new Exception("parse bootstrapServers error!");
}
Map<Integer, Long> partionAndOffset = getOffset(topic, kafkaHosts, kafkaPorts, true);
return partionAndOffset;
}
public static Map<Integer, Long> getOffset(String topic, String bootstrapServers, boolean isLast) throws Exception {
String[] servers = bootstrapServers.split(",");
List<String> kafkaHosts = new ArrayList<String>();
List<Integer> kafkaPorts = new ArrayList<Integer>();
for (int i = 0, size = servers.length; i < size; i++) {
String[] hostAndPort = servers[i].split(":");
try {
String host = hostAndPort[0];
Integer port = Integer.parseInt(hostAndPort[1]);
kafkaHosts.add(host);
kafkaPorts.add(port);
} catch (Exception e) {
e.printStackTrace();
}
}
if (kafkaHosts.size() < 1) {
throw new Exception("parse bootstrapServers error!");
}
Map<Integer, Long> partionAndOffset = getOffset(topic, kafkaHosts, kafkaPorts, isLast);
return partionAndOffset;
}
private static Map<Integer, Long> getOffset(String topic, List<String> kafkaHosts,
List<Integer> kafkaPorts, boolean isLast) throws Exception {
Map<Integer, Long> partionAndOffset = null;
for (int i = 0, size = kafkaHosts.size(); i < size; i++) {
String host = kafkaHosts.get(i);
int port = kafkaPorts.get(i);
try {
partionAndOffset = getOffset(topic, host, port, isLast);
} catch (Exception e) {
throw new Exception("topic(" + topic + "),kafkaHost(" + host + "),kafkaPort(" + port + "), Kafka getEarliestOffset error!", e);
}
if (partionAndOffset.size() > 0) {
break;
} else {
continue;
}
}
return partionAndOffset;
}
private static Map<Integer, Long> getOffset(String topic, String kafkaHost, int kafkaPort, boolean isLast) throws Exception {
Map<Integer, Long> partionAndOffset = new HashMap<Integer, Long>();
TreeMap<Integer, PartitionMetadata> metadatas = null;
try {
metadatas = KafkaOffsetUtils.findLeader(kafkaHost, kafkaPort, topic);
} catch (Exception e) {
throw new Exception("topic(" + topic + "),kafkaHost(" + kafkaHost + "),kafkaPort(" + kafkaPort + "), Kafka findLeader error!", e);
}
for (Entry<Integer, PartitionMetadata> entry : metadatas.entrySet()) {
int partition = entry.getKey();
String leadBroker = entry.getValue().leader().host();
String clientName = "Client_" + topic + "_" + partition;
SimpleConsumer consumer = null;
try {
consumer = new SimpleConsumer(leadBroker, kafkaPort, 100000, 64 * 1024, clientName);
long offset = -1;
if (isLast) {
// 获取最新偏移
offset = KafkaOffsetUtils.getOffset(consumer, topic, partition,
kafka.api.OffsetRequest.LatestTime(), clientName);
} else {
// 获取最早偏移
offset = KafkaOffsetUtils.getOffset(consumer, topic, partition,
kafka.api.OffsetRequest.EarliestTime(), clientName);
}
partionAndOffset.put(partition, offset);
} catch (Exception e) {
throw new Exception("topic(" + topic + "),kafkaHost(" + kafkaHost + "),kafkaPort(" + kafkaPort +
"), Kafka fetch earliestOffset error!", e);
} finally {
if (consumer != null) {
consumer.close();
}
}
}
return partionAndOffset;
}
/**
* 获得zookeeper里存放的某个topic已消费的偏移量信息
*
* @param zkServers kafka在zookeeper里的地址
* @param groupID kafka消费者归属的组的名称
* @param topic topic名称
* @param connectionTimeout 连接超时时间(毫秒)
* @param sessionTimeout session超时时间(毫秒)
* @return Map<TopicAndPartition , Long>
*/
public static Map<TopicAndPartition, Long> getConsumerOffsets(String zkServers, String groupID, String topic,
int connectionTimeout, int sessionTimeout) {
Map<TopicAndPartition, Long> retVals = new HashMap<TopicAndPartition, Long>();
ObjectMapper objectMapper = new ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString(zkServers).connectionTimeoutMs(connectionTimeout)
.sessionTimeoutMs(sessionTimeout).retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
try {
String nodePath = "/consumers/" + groupID + "/offsets/" + topic;
if (curatorFramework.checkExists().forPath(nodePath) != null) {
List<String> partitions = curatorFramework.getChildren().forPath(nodePath);
for (String partiton : partitions) {
int partitionL = Integer.valueOf(partiton);
Long offset = objectMapper.readValue(curatorFramework.getData().forPath(nodePath + "/" + partiton), Long.class);
TopicAndPartition topicAndPartition = new TopicAndPartition(topic, partitionL);
retVals.put(topicAndPartition, offset);
}
}
} catch (Exception e) {
e.printStackTrace();
}
curatorFramework.close();
return retVals;
}
public static Map<TopicAndPartition, Long> getConsumerOffsetsOfTopics(String zkServers, String groupID, List<String> topics,
int connectionTimeout, int sessionTimeout) {
Map<TopicAndPartition, Long> retVals = new HashMap<TopicAndPartition, Long>();
ObjectMapper objectMapper = new ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString(zkServers).connectionTimeoutMs(connectionTimeout)
.sessionTimeoutMs(sessionTimeout).retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
for (int i = 0; i < topics.size(); i++) {
try {
String nodePath = "/consumers/" + groupID + "/offsets/" + topics.get(i);
if (curatorFramework.checkExists().forPath(nodePath) != null) {
List<String> partitions = curatorFramework.getChildren().forPath(nodePath);
for (String partiton : partitions) {
int partitionL = Integer.valueOf(partiton);
Long offset = objectMapper.readValue(curatorFramework.getData().forPath(nodePath + "/" + partiton), Long.class);
TopicAndPartition topicAndPartition = new TopicAndPartition(topics.get(i), partitionL);
retVals.put(topicAndPartition, offset);
}
}
} catch (Exception e) {
e.printStackTrace();
}
curatorFramework.close();
}
return retVals;
}
/**
* 获得kafka里某个topic的分区和偏移量信息
*
* @param kafkaBrokers kafka集群的节点
* @param topic kafka的主题
* @return Map<TopicAndPartition , Long>
*/
public static Map<TopicAndPartition, Long> getTopicOffsets(String kafkaBrokers, String topic) {
Map<TopicAndPartition, Long> retVals = new HashMap<TopicAndPartition, Long>();
for (String kafkaBroker : kafkaBrokers.split(",")) {
SimpleConsumer simpleConsumer = new SimpleConsumer(kafkaBroker.split(":")[0],
Integer.valueOf(kafkaBroker.split(":")[1]), 10000, 1024, "consumer");
TopicMetadataRequest topicMetadataRequest = new TopicMetadataRequest(Arrays.asList(topic));
TopicMetadataResponse topicMetadataResponse = simpleConsumer.send(topicMetadataRequest);
for (TopicMetadata metadata : topicMetadataResponse.topicsMetadata()) {
for (PartitionMetadata part : metadata.partitionsMetadata()) {
// Broker leader = part.leader();//kafka 0.8.1.1
BrokerEndPoint leader = part.leader(); //kafka 0.9.0
if (leader != null) {
TopicAndPartition topicAndPartition = new TopicAndPartition(topic, part.partitionId());
PartitionOffsetRequestInfo partitionOffsetRequestInfo = new PartitionOffsetRequestInfo(
kafka.api.OffsetRequest.LatestTime(), 10000);
OffsetRequest offsetRequest = new OffsetRequest(ImmutableMap.of(topicAndPartition,
partitionOffsetRequestInfo), kafka.api.OffsetRequest.CurrentVersion(), simpleConsumer.clientId());
OffsetResponse offsetResponse = simpleConsumer.getOffsetsBefore(offsetRequest);
if (!offsetResponse.hasError()) {
long[] offsets = offsetResponse.offsets(topic, part.partitionId());
retVals.put(topicAndPartition, offsets[0]);
}
}
}
}
simpleConsumer.close();
}
return retVals;
}
public static Map<TopicAndPartition, Long> getTopicsOffsets(String kafkaBrokers, List<String> topics) {
Map<TopicAndPartition, Long> retVals = new HashMap<TopicAndPartition, Long>();
for (String kafkaBroker : kafkaBrokers.split(",")) {
SimpleConsumer simpleConsumer = new SimpleConsumer(kafkaBroker.split(":")[0],
Integer.valueOf(kafkaBroker.split(":")[1]), 10000, 1024, "consumer");
TopicMetadataRequest topicMetadataRequest = new TopicMetadataRequest(topics);
TopicMetadataResponse topicMetadataResponse = simpleConsumer.send(topicMetadataRequest);
for (TopicMetadata metadata : topicMetadataResponse.topicsMetadata()) {
for (PartitionMetadata part : metadata.partitionsMetadata()) {
// Broker leader = part.leader();//kafka 0.8.1.1
BrokerEndPoint leader = part.leader(); //kafka 0.9.0
if (leader != null) {
TopicAndPartition topicAndPartition = new TopicAndPartition(metadata.topic(), part.partitionId());
PartitionOffsetRequestInfo partitionOffsetRequestInfo = new PartitionOffsetRequestInfo(
kafka.api.OffsetRequest.LatestTime(), 10000);
OffsetRequest offsetRequest = new OffsetRequest(ImmutableMap.of(topicAndPartition,
partitionOffsetRequestInfo), kafka.api.OffsetRequest.CurrentVersion(), simpleConsumer.clientId());
OffsetResponse offsetResponse = simpleConsumer.getOffsetsBefore(offsetRequest);
if (!offsetResponse.hasError()) {
long[] offsets = offsetResponse.offsets(metadata.topic(), part.partitionId());
retVals.put(topicAndPartition, offsets[0]);
}
}
}
}
simpleConsumer.close();
}
return retVals;
}
public static void saveOffset(final Broadcast<String> kafkaZkConnectBroadcast,
final Broadcast<String> zkConnectionTimeoutBroadcast,
final Broadcast<String> zkSessionTimeoutBroadcast, final Broadcast<String> groupIdBroadcast,
final AtomicReference<OffsetRange[]> offsetRanges) throws Exception {
org.codehaus.jackson.map.ObjectMapper objectMapper = new org.codehaus.jackson.map.ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString(kafkaZkConnectBroadcast.getValue())
.connectionTimeoutMs(Integer.parseInt(zkConnectionTimeoutBroadcast.getValue()))
.sessionTimeoutMs(Integer.parseInt(zkSessionTimeoutBroadcast.getValue()))
.retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
for (OffsetRange offsetRange : offsetRanges.get()) {
final byte[] offsetBytes = objectMapper.writeValueAsBytes(offsetRange.untilOffset());
String nodePath = "/consumers/" + groupIdBroadcast.getValue()
+ "/offsets/" + offsetRange.topic() + "/" + offsetRange.partition();
if (null != curatorFramework.checkExists().forPath(nodePath)) {
curatorFramework.setData().forPath(nodePath, offsetBytes);
} else {
curatorFramework.create().creatingParentsIfNeeded().forPath(nodePath, offsetBytes);
}
}
curatorFramework.close();
}
public static void saveOffsetSingle(final Broadcast<String> kafkaZkConnectBroadcast,
final Broadcast<String> zkConnectionTimeoutBroadcast,
final Broadcast<String> zkSessionTimeoutBroadcast, final Broadcast<String> groupIdBroadcast,
final OffsetRange offsetRange) throws Exception {
org.codehaus.jackson.map.ObjectMapper objectMapper = new org.codehaus.jackson.map.ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString(kafkaZkConnectBroadcast.getValue())
.connectionTimeoutMs(Integer.parseInt(zkConnectionTimeoutBroadcast.getValue()))
.sessionTimeoutMs(Integer.parseInt(zkSessionTimeoutBroadcast.getValue()))
.retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
final byte[] offsetBytes = objectMapper.writeValueAsBytes(offsetRange.untilOffset());
String nodePath = "/consumers/" + groupIdBroadcast.getValue()
+ "/offsets/" + offsetRange.topic() + "/" + offsetRange.partition();
if (null != curatorFramework.checkExists().forPath(nodePath)) {
curatorFramework.setData().forPath(nodePath, offsetBytes);
} else {
curatorFramework.create().creatingParentsIfNeeded().forPath(nodePath, offsetBytes);
}
curatorFramework.close();
}
}
这里还是推荐用第二种方法,第二种方法在业务处理过程中更加的灵活可用。