1、面向过程和面向对象区别:
1)面向过程:开发一个应用程序、一个项目,必须先了解整个过程,了解各个步骤、模块间的因果关系,使的面向过程方式去开发程序时,代码和代码之间的关联程度是非常强。所以其中任何一个因果关系出现问题或者发生变动,都会影响到整个系统。缺点:扩展性差
2)面向对象:先去了解整个业务,然后将现实的业务分割成不同的单元,再使用java程序对各个单元进行实现,实现之后我们只要给它一个环境,驱动一下,让各个单元和各个单元进行合作,形成一个系统。优点:扩展能力强
备注:因为现实世界太复杂多变,面向过程的分析方法无法满足。
java、.net:都是面向对象的;c++:一半面向对象,一半面向过程;c语言: 纯面向过程
备注:为什么面向对象成为主流?
因为更符合人类的思维模式,更容易分析显示世界,从软件开发的生命周期来看:面向对象分为(OOA 面向对象的分析、OOD 面向对象的设计、OOP面向对象的线程)
2、类和对象的概念:
1)类:是一种类型,对现实世界中具有共同特征的一堆事物进行抽象,就形成了类。
类=属相+方法 属相源于类的状态,而方法来源于动作
2)对象:现实存在的个体,具体的存在称为对象,也叫实例;也就是说一个类的具体化,就是对象或实例
备注:通常是定义类型,创建对象;在java中类相当于引用数据类型,从类到对象的过程称为实例化过程,从对象到类的过程称为抽象的过程
java语言中对象封装性:
A、属性私有化。由private修饰的数据只能在本类中访问
B、对外提供set和get方法,在方法中可以写代码做业务逻辑控制,进一步提高数据安全性,外部程序无法直接访问私有的数据,但是可以通过调用set和get方法进行调用
3、java类中可以出现的因素:
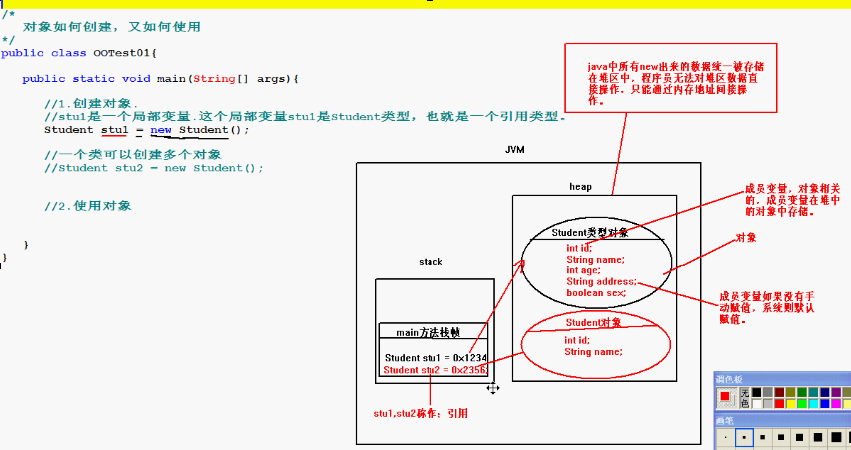
1)成员变量(实例变量、非静态变量)-->是对象相关的,在堆中的对象中存储,必须有对象才能访问。引用.成员变量名进行调用成员变量必须先声明再赋值才能使用,若无手动赋值,则在无参构造方法执行的时候会自动赋值,但是加载该类的时候并不会给其中定义的成员变量赋值
2)成员方法(实例方法、非静态方法)-->引用.成员方法名进行调用
3)静态方法 -->类名.静态方法名进行调用
4)构造函数(构造方法)-->为了创建对象,并在创建对象的时(即调用无参构造方法时)给所又的成员变量赋值
构造方法的语法: [修饰符列表] 构造方法名(形式参数列表){//构造方法名必须和类名一致
方法体;//一个类没有提供任何构造方法,系统默认提供无参数的构造方法;一个类已经手动的提供了构造方法,那么系统不会再提供任何构造方法;
}
//构造方法和普通的方法一样,同样可以构成重载
//构造方法不具有任何返回值类型,即没有返回值,关键字void 也不能加入,加入后就不是构造方法了,就成了普通的方法了
备注:
对象:
A、java语言中所有new的东西只有在heap堆内存种才能看到。
B、new表示到堆里面开辟一个空间,new 在java语言中是个关键字。
C、Student stu1=new Student();其中的new Student 表示开辟的空间是一个Sutdent类型的空间,其实是在创建对象。 而stu1是个局部变量,它的类型是Student类型。是在栈中存储的。即new Student()创建一个对象,之后将赋给局部变量:stu1,而这个局部变量是有类型的,是Student类型。
D、对象在堆里面是占一定的空间的,这个空间在内存中有它的地址。这个内存地址被赋给了stu1,那么stu1这个地址就指向了堆里面的空间,这在C语言里面叫做指针,只不过在java中没有指针这么一说,这被称做引用,
注意:把stu1当做对象是错误的,stu1专业术语别成为引用,引用中保存的是内存地址指向堆中的对象。一般情况下都是通过一个地址去访问一个对象。一个类可以创建多个对象
4、 一个标准的实体类的4大基本规则:
A、封装(属性私有化,分别提供对应的get与set方法等),
B、提供无参构造 ,
C、重写:toString(),equals(),hashCode()这3个方法,
D、实现java.io.Serializable接口!
为什么要重写toString方法?
最后重写toString方法会让你打印和输出变得更顺利
为什么要重写equals方法?
重写它就是为了以后比较对象是否相等,比如你问题中的假如父类是person,子类是student,那么当我们new了几个student后,在程序中怎么去判断这几个 student实例是否是同一个学生呢?别告诉我用“=”去判断!这时如果我们的student重写了equals(比如你按照学号来比较),那么你就可以用S1.equals(S2)来比较了。
为什么重写hashCode方法?
至于hashCode,那是因为假如我们存取数据时 是存放在键值对中时(比如Map),这时候光靠equals效率不高,这时候用对象的哈希码(即hashCode方法得到的)来查找和比较更快,所以一般重写equals方法必须重写hashCode方法,因为java规定相等的对象必须有相等的哈希码
5、java虚拟机管理的内存
1)堆区heap
所有new出来的对象都放在堆区,java程序员无法直接对堆中的数据进行操作,必须通过一个引用去访问,也就是间接去访问。
另一种解释:存放new出来的对象,此对象由垃圾收集器收集,垃圾收集器,针对的就是堆区。
2)栈区stack
每一次调用方法的时候都会在栈中分配空间,每调用一个方法,会发生压栈动作;方法结束后发生弹栈动作,并且每一个栈帧中,会存放一个局部变量;
这个局部变量保存一个内存地址,指向堆(heap)中的一个对象,什么时候这个对象会被回收走呢?当中间的这根线断了,就代表再也没有人可以访问它了。 因为所有访问堆中的数据都是通过引用来实现的。如果堆中的对象没有更多的引用指向它,则该对象变成了垃圾,等待垃圾回收器的回收。
3)方法区
方法区存放的是.class 文件代码,还包括静态变量、常量另外一种解释:方法区存放类的所有消息,包括所有的方法,静态变量,常量。
*.class 文件通过装载机,将class的文件代码放到方法区里面。然后一步一步的执行代码,代码每执行一次就调用一次方法,每调用一次方法就在栈中分配空间,在这个过程中,假如用了一个new关键字,用来创建对象,一创建对象就会在堆区分配空间,
User u1= new User();//程序执行到此处,u1不再指向堆中的对象,即u1不指向堆中的任何东西,对象变成了垃圾。
u1=null;
//System.out.println(u1.name);//java.lang.NullPointerException 使用一个空的引用去访问成员会出现:空指针异常。
备注:
类加载到虚拟机的时候,成员变量是没有值的,因为在加载的时候根本就没有创建对象;
在构造方法执行的时候,才会给成员变量赋值。所以引用数据类型的默认值都是null
对象在堆中开启空间,对象在堆中的内存地址,让一个引用去保存,将来我们要向访问这个对象,要通过地址去访问,也即是通过“引用.”的方式去访问