对象的内存分配流程如下:
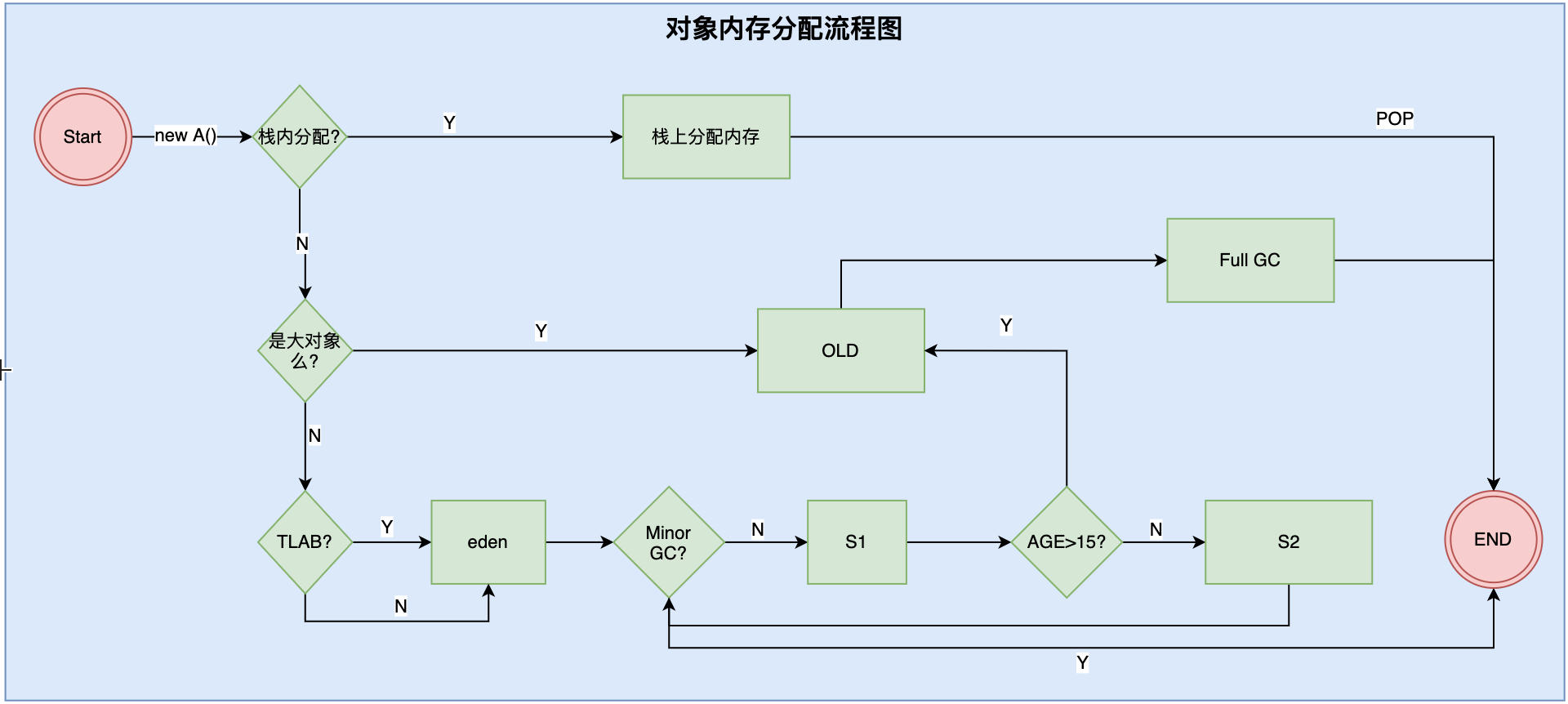
对象创建的过程中会给对象分配内存,分配内存的整体流程如下:
第一步:判断栈上是否有足够的空间。
这里和之前理解有所差别。之前一直都认为new出来的对象都是分配在堆上的,其实不是,在满足一定的条件,会先分配在栈上。那么为什么要在栈上分配?什么时候分配在栈上?分配在栈上的对象如何进行回收呢?下面来详细分析。
1.为什么要分配在栈上?
通过JVM内存模型中,我们知道Java的对象都是分配在堆上的。当堆空间(新生代或者老年代)快满的时候,会触发GC,没有被任何其他对象引用的对象将被回收。如果堆上出现大量这样的垃圾对象,将会频繁的触发GC,影响应用的性能。其实这些对象都是临时产生的对象,如果能够减少这样的对象进入堆的概率,那么就可以成功减少触发GC的次数了。我们可以把这样的对象放在堆上,这样该对象所占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力。
2.什么情况下会分配在栈上?
为了减少临时对象在堆内分配的数量,JVM通过逃逸分析确定该对象会不会被外部访问。如果不会逃逸可以将该对象在栈上分配内存。随栈帧出栈而销毁,减轻GC的压力。
3.什么是逃逸?
那么什么是逃逸分析呢?要知道逃逸分析,先要知道什么是逃逸?我们来看一个例子
public class Test {
public User test1() {
User user = new User();
user.setId(1);
user.setName("张三");
return user;
}
public void test2() {
User user = new User();
user.setId(2);
user.setName("李四");
}
}
Test里有两个方法,test1()方法构建了user对象,并且返回了user,返回回去的对象肯定是要被外部使用的。这种情况就是user对象逃逸出了test1()方法。
而test2()方法也是构建了user对象,但是这个对象仅仅是在test2()方法的内部有效,不会在方法外部使用,这种就是user对象没有逃逸。
判断一个对象是否是逃逸对象,就看这个对象能否被外部对象访问到。
结合栈上分配来理解为何没有逃逸出去的对象为什么应该分配在栈上呢?来看下图:
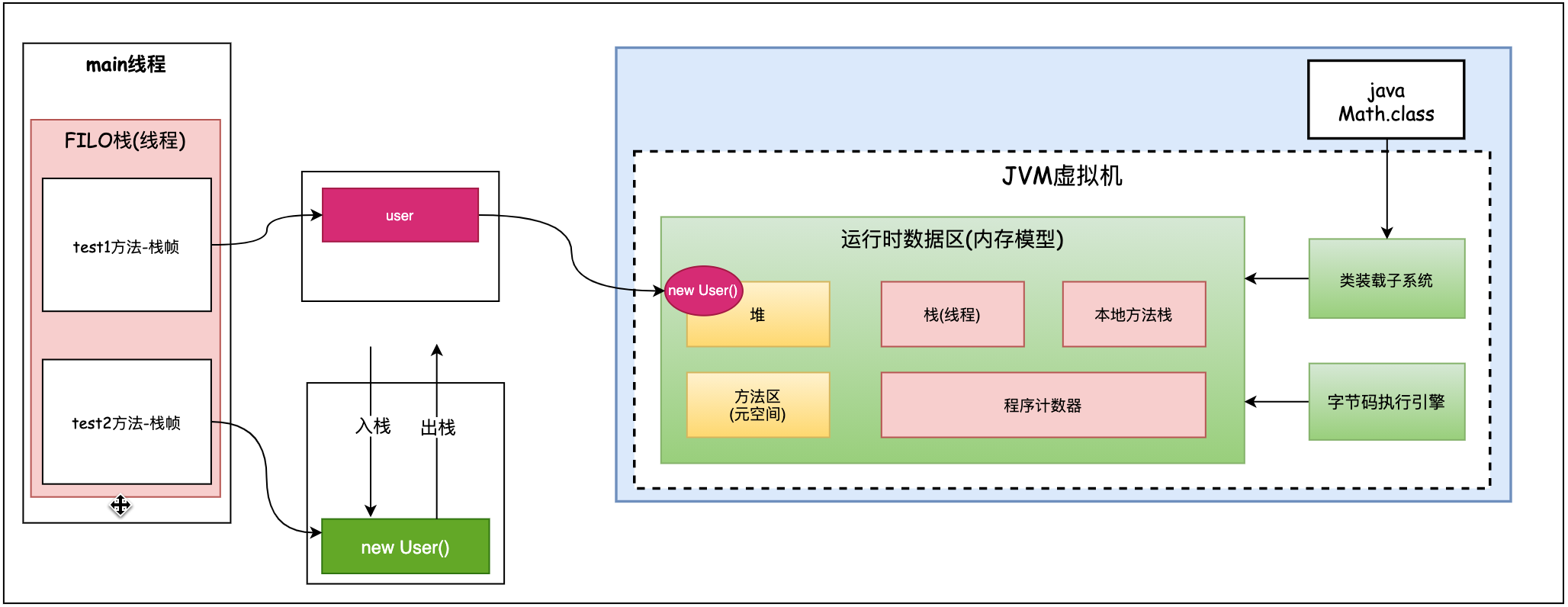
Test2()方法的user对象只会在当前方法内有效,如果放在堆里,在方法结束后,其实这个对象就已经是垃圾的,但却在堆里占用堆内存空间。如果将这个对象放入栈中,随着方法入栈,逻辑处理结束,对象就变成垃圾了,再随着栈帧出栈。这样可以节约堆空间。尤其是这种非逃逸对象很多的时候。可以节省大量的堆空间,降低GC的次数。
4.什么是对象的逃逸分析?
就是分析对象动态作用域,当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为参数传递到其他地方中。 上面的例子中,很显然test1()方法中的user对象被返回了,这个对象的作用域范围不确定,test2方法中的user对象我们可以确定当方法结束这个对象就可以认为是无效对象了,对于这样的对象我们其实可以将其分配在栈内存里,让其在方法结束时跟随栈内存一起被回收掉。
大白话说就是:判断user对象是否会逃逸到方法外,如果不会逃逸到方法外,那么就建议在堆中分配一块内存空间,用来存储临时的变量。是不是不会逃逸到方法外的对象就一定会分配到堆空间呢?不是的,需要满足一定的条件:第一个条件是JVM开启了逃逸分析。可以通过设置参数来开启/关闭逃逸分析。
-XX:+DoEscapeAnalysis 开启逃逸分析
-XX:-DoEscapeAnalysis 关闭逃逸分析
JVM对于这种情况可以通过开启逃逸分析参数(-XX:+DoEscapeAnalysis)来优化对象内存分配位置,使其通过标量替换优先分配在栈上(栈上分配),JDK7之后默认开启逃逸分析,如果要关闭使用参数(-XX:-DoEscapeAnalysis)
5.什么是标量替换?
如果一个对象通过逃逸分析能过确定他可以在栈上分配,但是我们知道一个线程栈的空间默认也就1M,栈帧空间就更小了。而对象分配需要一块连续的空间,经过计算如果这个对象可以放在栈帧上,但是栈帧的空间不是连续的,对于一个对象来说,这样是不行的,因为对象需要一块连续的空间。那怎么办呢?这时JVM做了一个优化,即便在栈帧中没有一块连续的空间方法下这个对象,他也能够通过其他的方式,让这个对象放到栈帧里面去,这个办法就是标量替换。
什么是标量替换呢?
如果有一个对象,通过逃逸分析确定在栈上分配了,以User为例,为了能够在有限的空间里能够放下User中所有的东西,我们不会在栈上new一个完整的对象了,而是只是将对象中的成员变量放到栈帧里面去。如下图:

栈帧空间中没有一块完整的空间放User对象,为了能够放下,我们采用标量替换的方式,不是将整个User对象放到栈帧中,而是将User中的成员变量拿出来分别放在每一块空闲空间中。这种不是放一个完整的对象,而是将对象打散成一个个的成员变量放到栈帧上,当然会有一个地方标识这个属性是属于那个对象的,这就是标量替换。
通过逃逸分析确定该对象不会被外部访问,并且对象可以被进一步分解时,JVM不会创建该对象,而是将该对象成员变量分解若干个被这个方法使用的成员变量所代替,这些代替的成员变量在栈帧或寄存器上分配空间,这样就不会因为没有一大块连续空间导致对象内存不够分配了。开启标量替换参数是
-XX:+EliminateAllocations
JDK7之后默认开启。
6.标量替换与聚合量
那什么是标量,什么是聚合量呢?
标量即不可被进一步分解的量,而JAVA的基本数据类型就是标量(如:int,long等基本数据类型以及 reference类型等),标量的对立就是可以被进一步分解的量,而这种量称之为聚合量。而在JAVA中对象就是可以被进一步分解的聚合量。
7. 总结+案例分析
new出来的一部分对象是可以放在栈上的,那什么样的对象放在栈上呢?通过逃逸分析判断一个对象是否会逃逸到方法外,如果不会逃逸到方法外,那么就建议在堆中分配一块内存空间来存储这样的变量。那是不是说所有不会逃逸到方法外的对象就一定会分配到堆空间呢?不是的,需要满足一定的条件:
- 开启逃逸分析
- 开启标量替换
下面举例分析:
public class AllotOnStack {
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
alloc();
}
long end = System.currentTimeMillis();
System.out.println(end-start);
}
private static void alloc() {
User user = new User();
user.setId(1);
user.setName("zhuge");
}
}
上面有一段代码,在main方法中调用1亿次alloc()方法。在alloc()方法中,new了User对象,但是这个对象是没有逃逸出alloc()方法的。for循环运行了1亿次,这时会产生1亿个对象,如果分配在堆上,那么会有大量的GC产生;如果分配在栈上,那么几乎不会有GC产生。这里说的是几乎,也就是不一定完全没有gc产生,产生gc还可能是因为其他情况。
为了能够看到在栈上分配的明显的效果,我们分几种情况来分析:
- 默认情况下
设置参数:
我当前使用的是jdk8,默认开启逃逸分析(‐XX:+DoEscapeAnalysis),开启标量替换的(‐XX:+EliminateAllocations)。
-Xmx15m -Xms15m -XX:+PrintGC
设置上面的参数:将堆内存设置的小一些,并且设置打印GC日志,方便我们清晰的看到结果。
运行结果:
10
我们看到没有产生任何的GC。因为开启了逃逸分析,开启了标量替换。这就说明,对象没有分配在堆上,而是分配在栈上了。
有没有疑惑,为什么栈上可以放1亿对象?
因为产生一个对象,当这个方法执行完的时候,对象会随栈帧一起被回收。然后分配下一个对象,这个对象执行完再次被回收。以此类推。
- 关闭逃逸分析,开启标量替换
这种情况是关闭了逃逸分析,开启了标量替换。设置jvm参数如下:
-Xmx15m -Xms15m -XX:+PrintGC -XX:-DoEscapeAnalysis -XX:+EliminateAllocations
其实只有开启了逃逸分析,标量替换才会生效。所以,这种情况是不会将对象分配在栈上的,都分配在堆上,那么会产生大量的GC。我们来看运行结果:
[GC (Allocation Failure) 4842K->746K(15872K), 0.0003706 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0003987 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0004303 secs]
......
[GC (Allocation Failure) 4842K->746K(15872K), 0.0004012 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0003712 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0003978 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0003969 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0011955 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0004206 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0004172 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0013991 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0006041 secs]
[GC (Allocation Failure) 4842K->746K(15872K), 0.0003653 secs]
773
我们看到产生了大量的GC,并且耗时从原来的10毫秒延长到773毫秒
- 开启逃逸分析,关闭标量替换
这种情况是关闭了逃逸分析,开启了标量替换。设置jvm参数如下:
-Xmx15m -Xms15m -XX:+PrintGC -XX:+DoEscapeAnalysis -XX:-EliminateAllocations
其实只有开启了逃逸分析,标量替换不生效,表示的含义是如果对象在栈空间放不下了,那么会直接放到堆空间里。我们来看运行结果:
[GC (Allocation Failure) 4844K->748K(15872K), 0.0003809 secs]
[GC (Allocation Failure) 4844K->748K(15872K), 0.0003817 secs]
.......
[GC (Allocation Failure) 4844K->748K(15872K), 0.0003751 secs]
[GC (Allocation Failure) 4844K->748K(15872K), 0.0004613 secs]
[GC (Allocation Failure) 4844K->748K(15872K), 0.0005310 secs]
[GC (Allocation Failure) 4844K->748K(15872K), 0.0003402 secs]
[GC (Allocation Failure) 4844K->748K(15872K), 0.0003661 secs]
[GC (Allocation Failure) 4844K->748K(15872K), 0.0004457 secs]
[GC (Allocation Failure) 4844K->748K(15872K), 0.0004528 secs]
[GC (Allocation Failure) 4844K->748K(15872K), 0.0005270 secs]
657
我们看到开启了逃逸分析,但是没有开启标量替换也产生了大量的GC。
通常,我们都是同时开启逃逸分析和标量替换。
第二步:判断是否是大对象,不是放到Eden区
判断是否是大对象,如果是则直接放入到老年代中。如果不是,则判断是否是TLAB?如果是则在Eden去分配一小块空间给线程,把这个对象放在Eden区。如果不采用TLAB,则直接放到Eden区。
什么是TLAB呢?本地线程分配缓冲(Thread Local Allocation Buffer,TLAB)。简单说,TLAB是为了避免多线程争抢内存,在每个线程初始化的时候,就在堆空间中为线程分配一块专属的内存。自己线程的对象就往自己专属的那块内存存放就可以了。这样多个线程之间就不会去哄抢同一块内存了。jdk8默认使用的就是TLAB的方式分配内存。
通过-XX:+UseTLAB参数来设定虚拟机是否启用TLAB(JVM会默认开启-XX:+UseTLAB),-XX:TLABSize 指定TLAB大小。
1.对象是如何在Eden区分配的呢?
这一块的详细信息参考文章:https://www.cnblogs.com/ITPower/p/15384588.html
这里放上内存分配的图,然后我们案例来证实:

案例代码:
public class GCTest {
public static void main(String[] args) throws InterruptedException {
byte[] allocation1, allocation2;
allocation1 = new byte[60000*1024];
}
}
来看这段代码,定义了一个字节数组allocation2,给他分配了一块内存空间60M。
来看看程序运行的效果,这里为了方便检测效果,设置一下jvm参数打印GC日志详情
-XX:+PrintGCDetails 打印GC相信信息
a) Eden去刚好可以放得下对象
运行结果:
Heap
PSYoungGen total 76288K, used 65536K [0x000000076ab00000, 0x0000000770000000, 0x00000007c0000000)
eden space 65536K, 100% used [0x000000076ab00000,0x000000076eb00000,0x000000076eb00000)
from space 10752K, 0% used [0x000000076f580000,0x000000076f580000,0x0000000770000000)
to space 10752K, 0% used [0x000000076eb00000,0x000000076eb00000,0x000000076f580000)
ParOldGen total 175104K, used 0K [0x00000006c0000000, 0x00000006cab00000, 0x000000076ab00000)
object space 175104K, 0% used [0x00000006c0000000,0x00000006c0000000,0x00000006cab00000)
Metaspace used 3322K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 365K, capacity 388K, committed 512K, reserved 1048576K
- 新生代约76M
- Eden区约65M,占用了100%
- from/to月1M,占用0%
- 老年代月175M,占用0%
- 元数据空间约3M,占用365k。
我们看到新生代Eden区被放满了。其实我们的对象只有60M,Eden区有65M,为什么会被放满呢?因为Eden区还存放了JVM启动的一些类。因为Eden区能够放得下,所以不会放到老年代里。
元数据空间约3M是存放的方法区中类代码信息的镜像。我们在上面类型指针里面说过方法区中元数据信息在堆中的镜像。
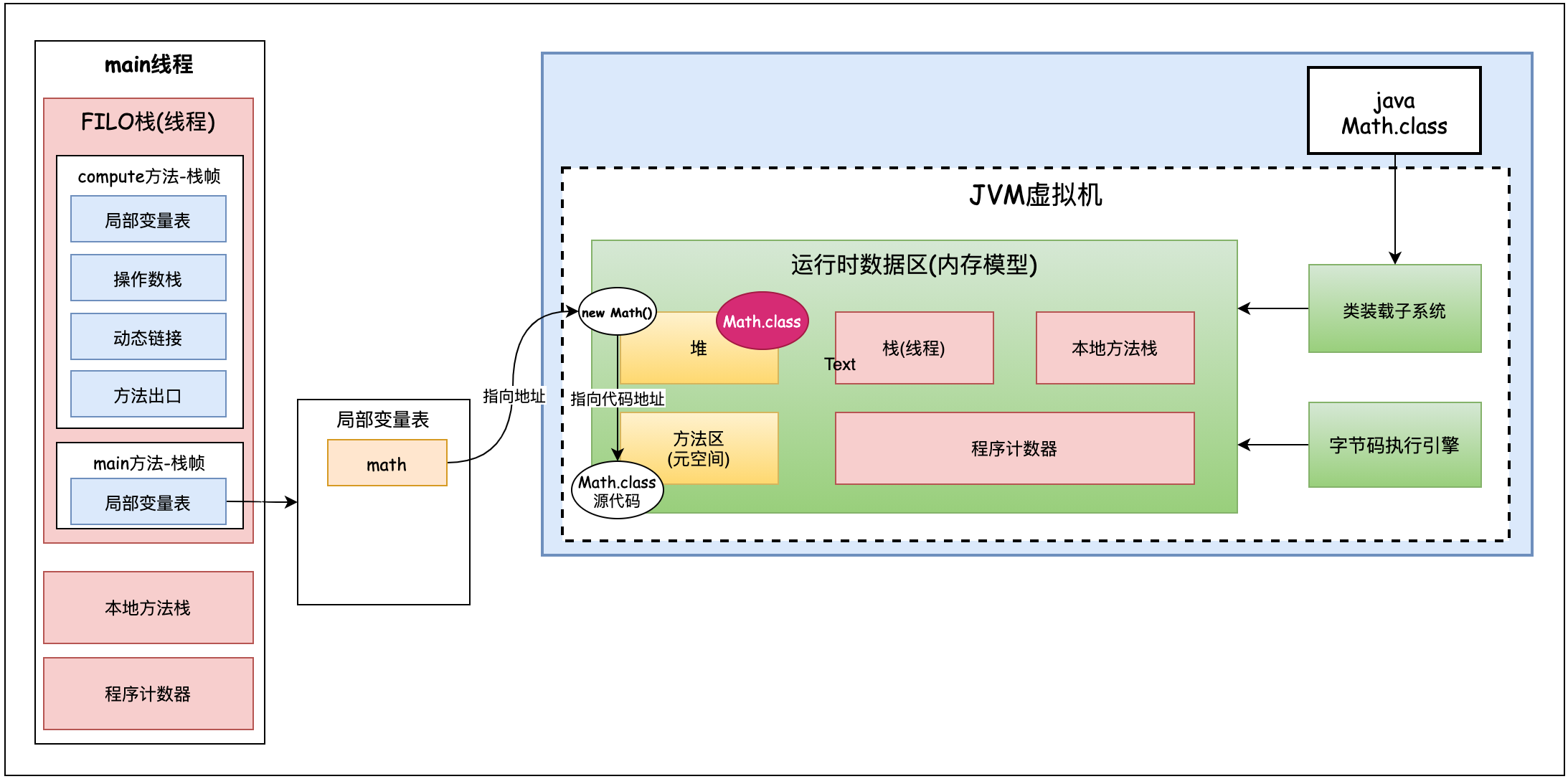
对于Math类来说,他还有一个类对象, 如下代码所示:
Class<? extends Math> mathClass = math.getClass();这个类对象是存储在哪里的呢?这个类对象是方法区中的元数据对象么?不是的。这个类对象实际上是jvm虚拟机在堆中创建的一块和方法区中源代码相似的信息。如下图堆空间右上角。
b) Eden区满了,会触发GC
public class GCTest {
public static void main(String[] args) throws InterruptedException {
byte[] allocation1, allocation2;
/*, allocation3, allocation4, allocation5, allocation6*/
allocation1 = new byte[60000*1024];
allocation2 = new byte[8000*1024];
}
}
来看这个案例,刚刚设置allocation1=60M Eden区刚好满了,这时候在为对象allocation2分配8M,因为Eden满了,这是会触发GC,60M from/to都放不下,会直接放到old老年代,然后将allocation2的8M放到Eden区。来看运行结果:
[GC (Allocation Failure) [PSYoungGen: 65245K->688K(76288K)] 65245K->60696K(251392K), 0.0505367 secs] [Times: user=0.25 sys=0.04, real=0.05 secs]
Heap
PSYoungGen total 76288K, used 9343K [0x000000076ab00000, 0x0000000774000000, 0x00000007c0000000)
eden space 65536K, 13% used [0x000000076ab00000,0x000000076b373ef8,0x000000076eb00000)
from space 10752K, 6% used [0x000000076eb00000,0x000000076ebac010,0x000000076f580000)
to space 10752K, 0% used [0x0000000773580000,0x0000000773580000,0x0000000774000000)
ParOldGen total 175104K, used 60008K [0x00000006c0000000, 0x00000006cab00000, 0x000000076ab00000)
object space 175104K, 34% used [0x00000006c0000000,0x00000006c3a9a010,0x00000006cab00000)
Metaspace used 3323K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 365K, capacity 388K, committed 512K, reserved 1048576K
和我们预测的一样
- 年轻代76M,已用9343k
- Eden65M,占用了13%,这13%就有allocation2分配的80M,另外的部分是jvm运行产生的
- from区10M,占用6%。这里面存的肯定不是allocation1的60M,因为存不下,这里的应该是和jvm有关的数据
- to去10M,占用0%
- 老年代175M,占用了60M,这60M就是allocation1回收过来的
- 元数据占用3M,使用365k。这一块数据没有发生变化,因为元数据信息没有变。
第三步 是大对象 放入到老年代
1.什么是大对象?
- Eden园区放不下了肯定是大对象。
- 通过参数设置什么是大对象。-XX:PretenureSizeThreshold=1000000 (单位是字节) -XX:+UseSerialGC。如果对象超过设置大小会直接进入老年代,不会进入年轻代,这个参数只在 Serial 和ParNew两个收集器下有效。
- 长期存活的对象将进入老年代。虚拟机采用分代收集的思想来管理内存,虚拟机给每个对象设置了一个对象年龄(Age)计数器。 如果对象在 Eden 出生并经过第一次 Minor GC 后仍然能够存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间中,并将对象年龄设为1。对象在 Survivor 中每熬过一次 MinorGC,年龄就增加1岁,当它的年龄增加到一定程度(默认为15岁,CMS收集器默认6岁,不同的垃圾收集器会略微有点不同),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 -XX:MaxTenuringThreshold 来设置。
2.为什么要将大对象直接放入到老年代呢?
为了避免为大对象分配内存时的复制操作而降低效率。
3.什么情况要手动设置分代年龄呢?
如果我的系统里80%的对象都是有用的对象,那么经过15次GC后会在Survivor中来回翻转,这时候不如就将分代年龄设置为5或者8,这样减少在Survivor中来回翻转的次数,直接放入到老年代,节省了年轻代的空间。