对于HashMap只是学习了下put,remove方法,hashMap是数组+链表+红黑树组成
所以下面贴出我自己给代码的注释,看不懂的见谅哈,毕竟我也是刚了解,如果有错误的地方请指出,非常感谢
put方法(图片和代码一起吧,屏幕小的时候 看图片合适点,看图片的话建议下载下来看,比较清晰):
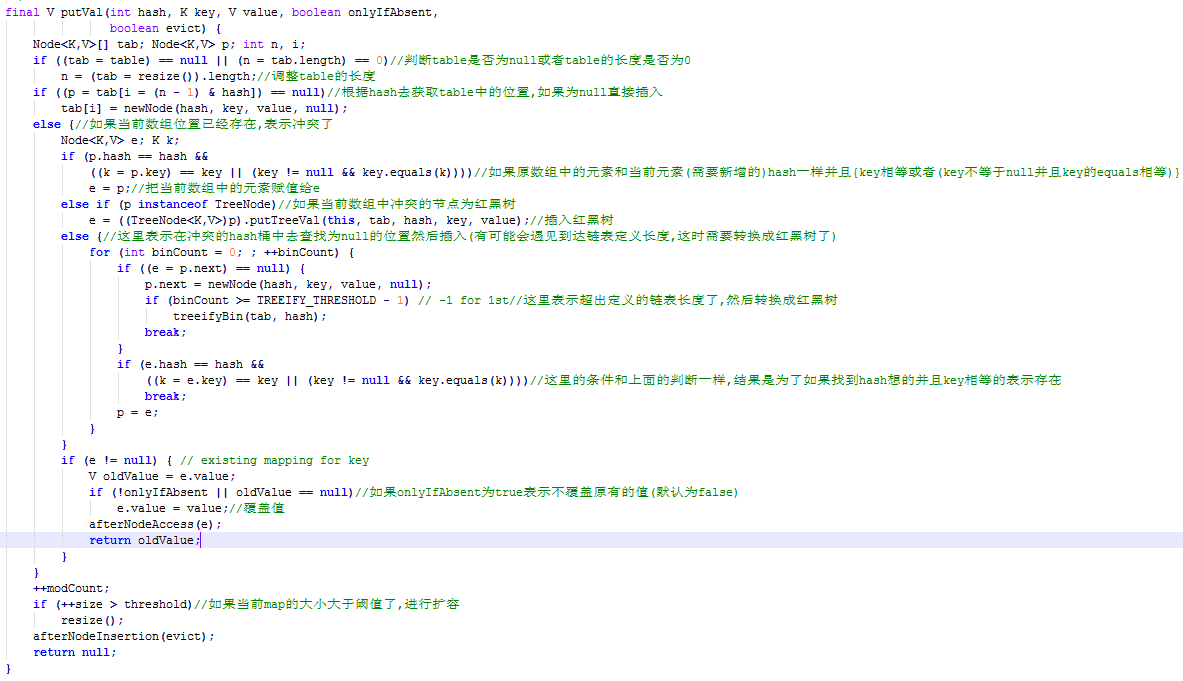


final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0)//判断table是否为null或者table的长度是否为0 n = (tab = resize()).length;//调整table的长度 if ((p = tab[i = (n - 1) & hash]) == null)//根据hash去获取table中的位置,如果为null直接插入 tab[i] = newNode(hash, key, value, null); else {//如果当前数组位置已经存在,表示冲突了 Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))//如果原数组中的元素和当前元素(需要新增的)hash一样并且{key相等或者(key不等于null并且key的equals相等)} e = p;//把当前数组中的元素赋值给e else if (p instanceof TreeNode)//如果当前数组中冲突的节点为红黑树 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//插入红黑树 else {//这里表示在冲突的hash桶中去查找为null的位置然后插入(有可能会遇见到达链表定义长度,这时需要转换成红黑树了) for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//这里表示超出定义的链表长度了,然后转换成红黑树 treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))//这里的条件和上面的判断一样,结果是为了如果找到hash想的并且key相等的表示存在 break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null)//如果onlyIfAbsent为true表示不覆盖原有的值(默认为false) e.value = value;//覆盖值 afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold)//如果当前map的大小大于阈值了,进行扩容 resize(); afterNodeInsertion(evict); return null; }
remove方法:

final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {//如果table不等于null并且table的长度大于0 并且p(根据需要删除的元素的hash值去查询)是否在table中 Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))//如果当前删除元素的hash值和查找到的元素hash值一样并且key相等或者(key不等于null并且key的equals相等)表示这个p元素就是需要删除的元素 node = p;//把p赋值给node else if ((e = p.next) != null) {//否则的话表示都在一个hash桶中,在桶(链表)中查找 if (p instanceof TreeNode)//如果是红黑树 node = ((TreeNode<K,V>)p).getTreeNode(hash, key);//根据key和hash获取需要删除的元素 else {//如果不是红黑树,则表示是链表--进行遍历 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e;//如果找到则赋值给node break; } p = e; } while ((e = e.next) != null); } } if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) {//如果node不等于null并且(如果matchValue为false,则不用比较值是否相等)--这里表示找到了需要删除的元素 if (node instanceof TreeNode)//如果找到的删除元素是红黑树 ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);//红黑树删除 else if (node == p)//如果删除的元素和p等价 tab[index] = node.next;//把table下标的元素值设置成node(需要删除的元素下一个节点) else p.next = node.next;//把node(需要删除的节点)下一个节点给node的父节点的下一个节点 ++modCount;//HashMap结构被修改的次数++ --size;//容量-- afterNodeRemoval(node); return node; } } return null; }
get方法相对来说比较简单,请读者自己看吧~嘿嘿
关于Hash方法原理(转载:https://www.zhihu.com/question/20733617)我也是不太明白~:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Java 7中是这样的

static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
上面这段代码其实叫做"扰动函数"
下面摘自https://www.zhihu.com/question/20733617
大家都知道上面代码里的key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。
理论上散列值是一个int型,如果直接拿散列值作为下标访问HashMap主数组的话,考虑到2进制32位带符号的int表值范围从-2147483648到2147483648。前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。
但问题是一个40亿长度的数组,内存是放不下的。你想,HashMap扩容之前的数组初始大小才16。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来访问数组下标。源码中模运算是在这个indexFor( )函数里完成的。
bucketIndex = indexFor(hash, table.length);
indexFor的代码也很简单,就是把散列值和数组长度做一个"与"操作,
static int indexFor(int h, int length) {
return h & (length-1);
}
顺便说一下,这也正好解释了为什么HashMap的数组长度要取2的整次幂。因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。
10100101 11000100 00100101
& 00000000 00000000 00001111
----------------------------------
00000000 00000000 00000101 //高位全部归零,只保留末四位
但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复,就无比蛋疼。
这时候“扰动函数”的价值就体现出来了,说到这里大家应该猜出来了。看下面这个图,
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
最后我们来看一下Peter Lawley的一篇专栏文章《An introduction to optimising a hashing strategy》里的的一个实验:他随机选取了352个字符串,在他们散列值完全没有冲突的前提下,对它们做低位掩码,取数组下标。
结果显示,当HashMap数组长度为512的时候,也就是用掩码取低9位的时候,在没有扰动函数的情况下,发生了103次碰撞,接近30%。而在使用了扰动函数之后只有92次碰撞。碰撞减少了将近10%。看来扰动函数确实还是有功效的。
但明显Java 8觉得扰动做一次就够了,做4次的话,多了可能边际效用也不大,所谓为了效率考虑就改成一次了。
感觉大概就是为了进行稀释碰撞(冲突)的次数--纯属个人理解