正则表达式:(字符串匹配)
- 使用单个字符串来描述匹配一系列符合某个句法规则的字符串
- 是对字符串操作的一种逻辑公式
- 应用场景:处理文本和数据
- 正则表达式过程:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;否则,匹配失败。
首先需要导入re这个模块 import re
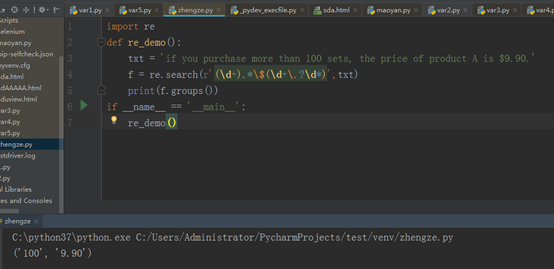
d表示数字,+表示匹配1到多个数字
.表示匹配任意的字符
*表示0到多个所有的字符
$ 将美元字符转义一下
. 将点.转义 ?表示匹配0个或者1个小数点 d 表示数字 *表示匹配0到多个数字
groups是一个方法,他可以将正则表达式里相匹配的项打印出来
re.search:搜索字符串,找到匹配的第一个字符串(搜索字符串任意位置的匹配)
re.match:从字符串开始开始匹配(只从字符串的起始位置开始匹配)

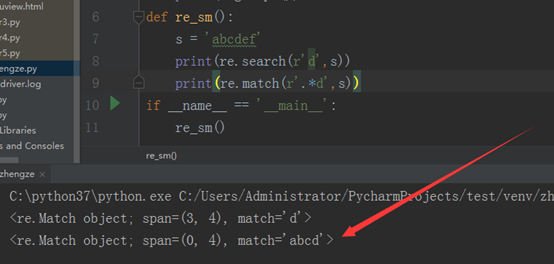
match是匹配字符串开头为‘d’的字符串,而我们给出的字符串是‘abcdef’,开头为‘a’,显然是不匹配的,所有最终的运行结果是‘None’
如果改正的话,我们可以从前边加上‘.*’,因为‘.’代表匹配任意的字符,‘*’代表0到多个字符,也就是在‘d’的前边可以有0到多个任意字符,这就可以匹配了,如下图所示:
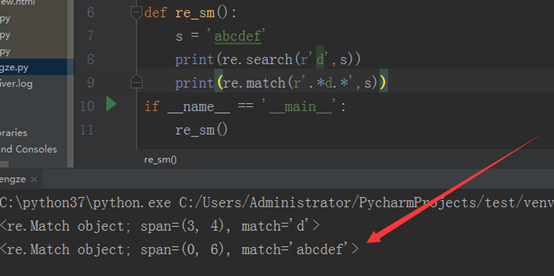
从图中可以看出,结果是abcd,后边的ef没匹配出来,同理,我们在后边也加上‘.*’,就可以得到‘abcdef’,如下图所示:
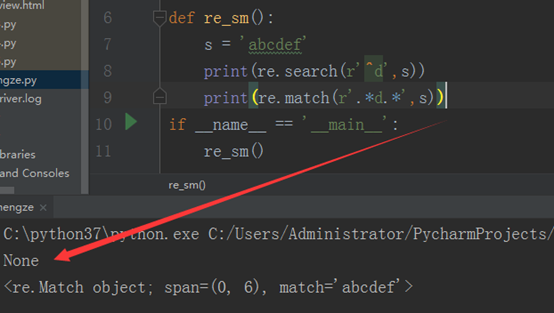
还有一种,就是我们在search那的‘d’前边加‘^’,他的意思就是严格搜索以‘d’为开头的字符串,这样的话,运行结果就不得而知了,如下:
split:使用正则表达式来分割字符串
先看程序:
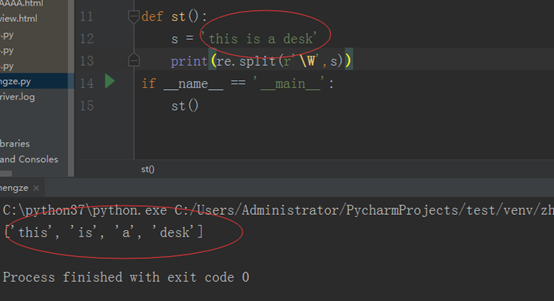
W:任意的非字母,只要不是字母,就将其作为界限,把其分割出来的。
findall:根据正则表达式从左向右搜索匹配项,返回匹配的字符串列表。Search,是搜索到匹配的第一个,他就停下来;而findall,搜索出所有的匹配项,返回的是所有匹配项的字符串列表。
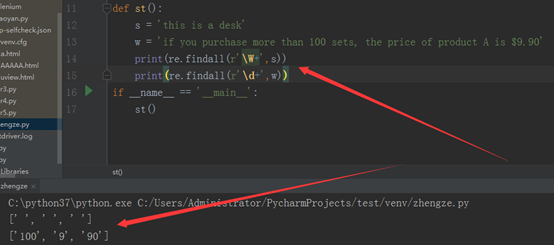
第一个print:w+,匹配1到多个字符,等匹配完this,碰到空格,还会继续往下匹配,直到最后。
第二个print:d+,匹配匹配1到多个数字,之所以没有打印出9.90,而是分开打印的,是因为碰到小数点以后,就继续往下寻找,自动与前一个匹配结果分开了。
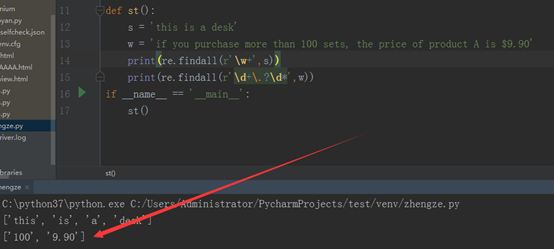
那怎么才能打印出9.90呢,我们先加一个‘.’ , 意思是匹配小数点,然后小数点在文本中可能有,也可能没有,所以,再加一个‘?’,小数点后边可能还有数字,所以再加一个d,再加一个*,表示可能有0个数字,也可能有多个数字。如下所示:
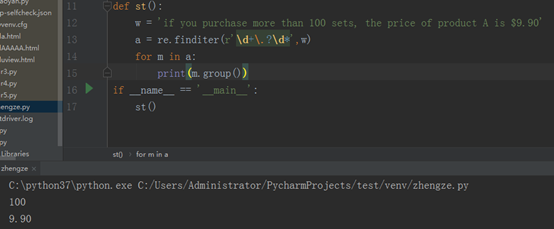
finditer:根据正则表达式从左到右搜索匹配项,返回一个迭代器迭代返回 ,迭代器里的每一个元素都是一个matchobject,你可以对matchobject进行一个操作,如下程序:
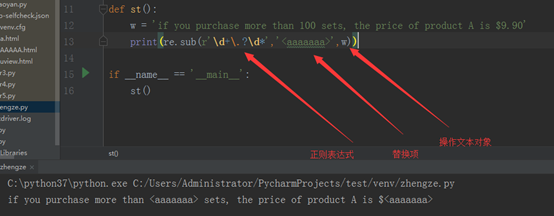
sub:字符串替换,里边有三个参数,如下:
pattern:正则表达式
repl:替换项,字符串或函数
string:待处理的字符串
程序如下所示:
以上就是今天所学,因为水平有限,可能有些地方的理解不是特别正确,还请多多指正,大家共同学习,一起进步。谢谢。