人脸识别是图像分析与理解最重要的应用之一,所谓人脸识别,就是利用计算机分析人脸视频或者图像,并从中提取出有效的识别信息,最终判别人脸对象的身份。人脸识别的研究可以追溯到20世纪 60年代末期,主要的思路是设计特征提取器,再利用机器学习的算法进行分类。2012深度学习引入人脸识别领域后,特征提取转由神经网络完成,深度学习在人脸识别上取得了巨大的成功。下面以时间为顺序,梳理下人脸识别各算法的发展历程。
一、传统算法
(一)基于几何特征
1、原理
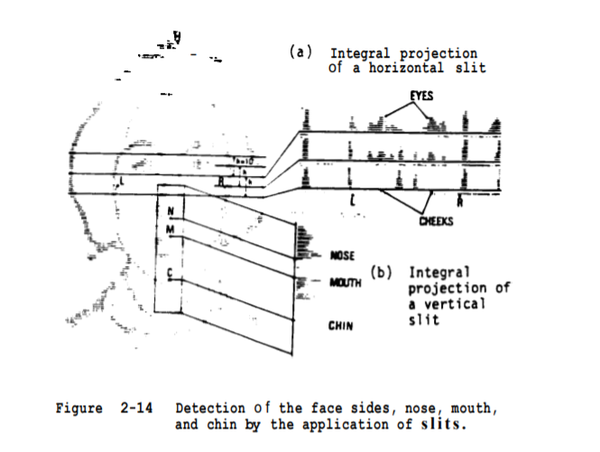
人脸由眼睛、鼻子、嘴巴、下巴等部件构成,这些部件的形状、大小,以及各部件在脸上的分布各异,构成各种各样的人脸,利用这些部件的形状和结构关系的几何描述,做为人脸识别的特征。比如:眼角点、鼻尖点和两个嘴角点,构造若干特征向量。特征向量通常包括人脸指定两点间的距离、曲率、角度等。
1973年,Kelly’s and Kanade’s PhD theses,第一篇人脸识别的paper,
2、优缺点
(1)优点
算法识别速度快,需要的内存小。
(2)缺点
一般几何特征只描述了部件的基本形状与结构关系,忽略了局部细微特征,造成部分信息的丢失,更适合于做粗分类,而且目前已有的特征点检测技术在精确率上还远不能满足要求。
(二)基于全局信息(holistic method)
基于几何特征的方法,萃取人脸部件的轮廓和几何关系,并没有用到图片中的其他信息,为了提高识别准确度,全局算法应运而生,全局算法的特征向量,包含人脸图像上所有部分的信息。
按照对全局特征处理方法的不同,介绍下面两种方法
1、PCA(Principal Components Analysis)
a.提出背景:
照片的识别,可以看成特征向量相互匹配的过程。如果2张100*100的照片,在各个维度上都相近,那么我们可以认为,这两张照片属于同一个人。但是以100 * 100的照片为例,数据维度10000维,数据维度太高,计算机处理复杂度高,需要将维度降低(因为10000维里面数据之间存在相关关系,所以可以除去重复维度信息,而保持信息不丢失)
b.降维方法
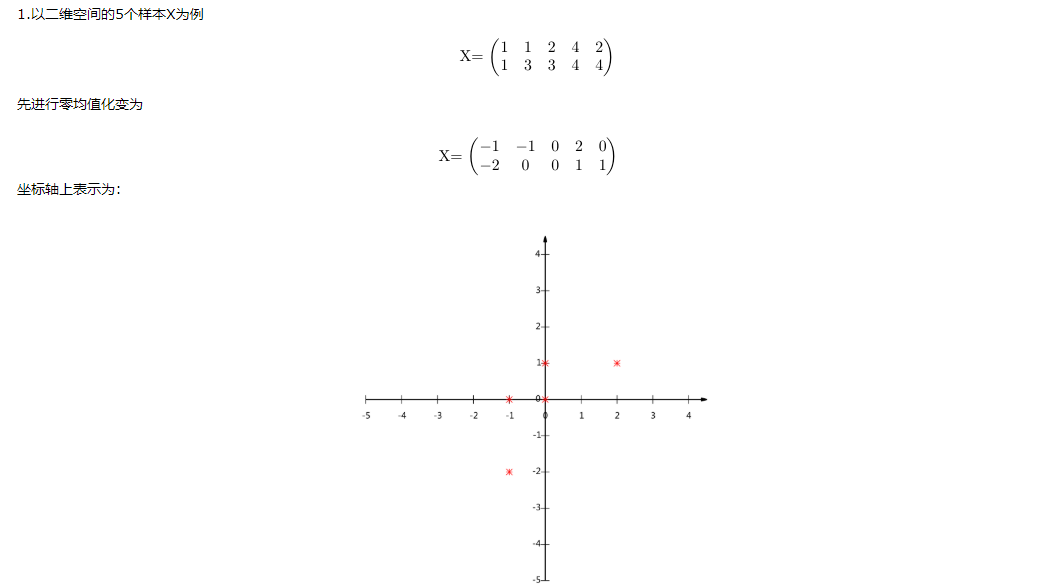

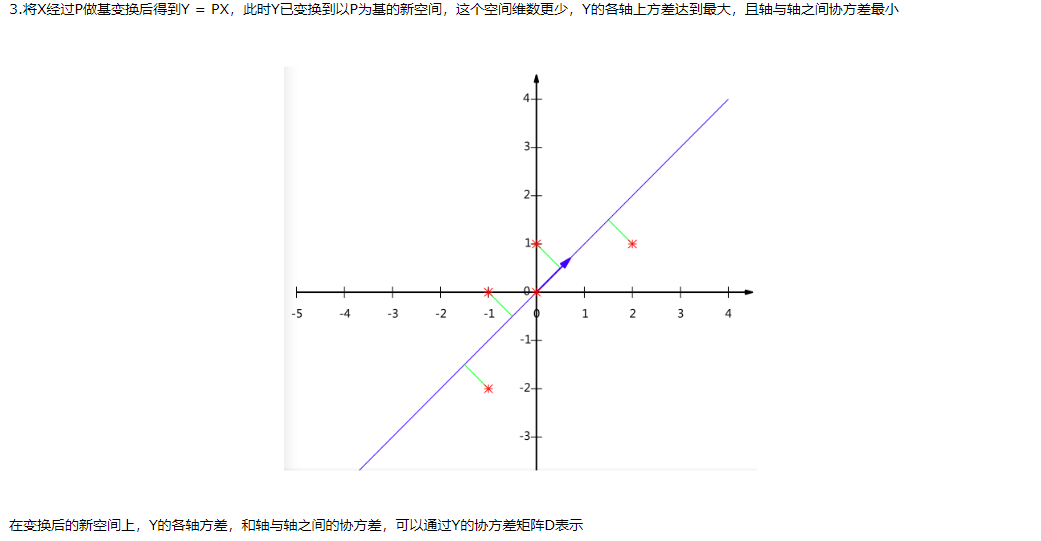

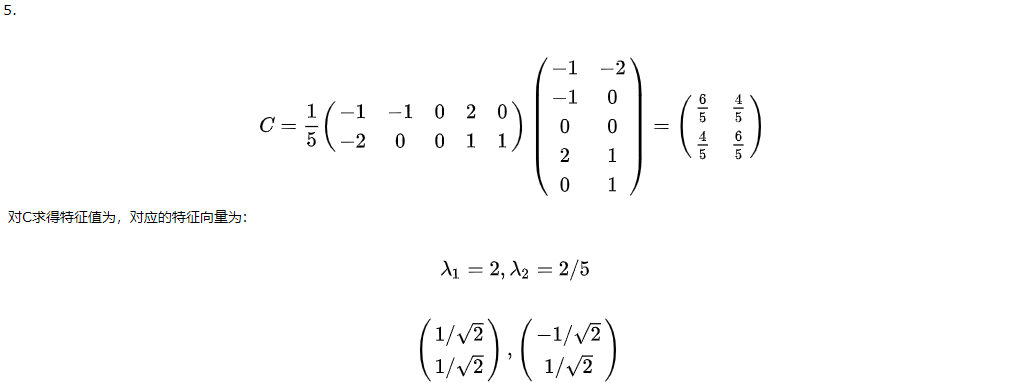
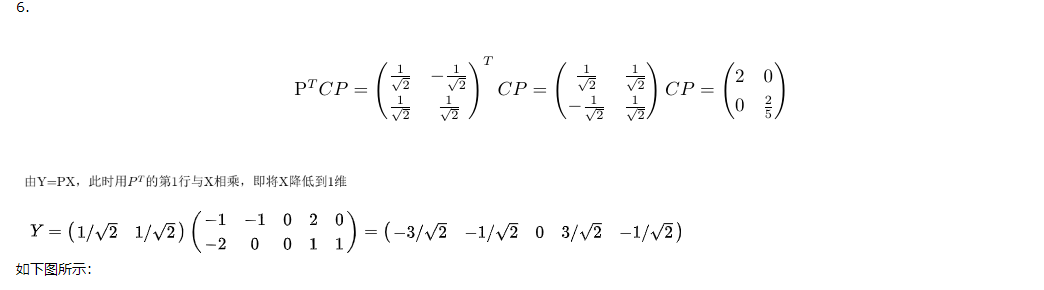
降低维度后,再拿这个压缩过的向量做识别即可。典型的方法有egienface等。

PCA所作的是将数据映射到最方便表示这组数据的坐标系上,映射时没有利用任何数据分类信息。做PCA其实是在信息损失尽可能低的情况下,将数据降维。如果在降维的时候加入分类信息,效果会不会更好?
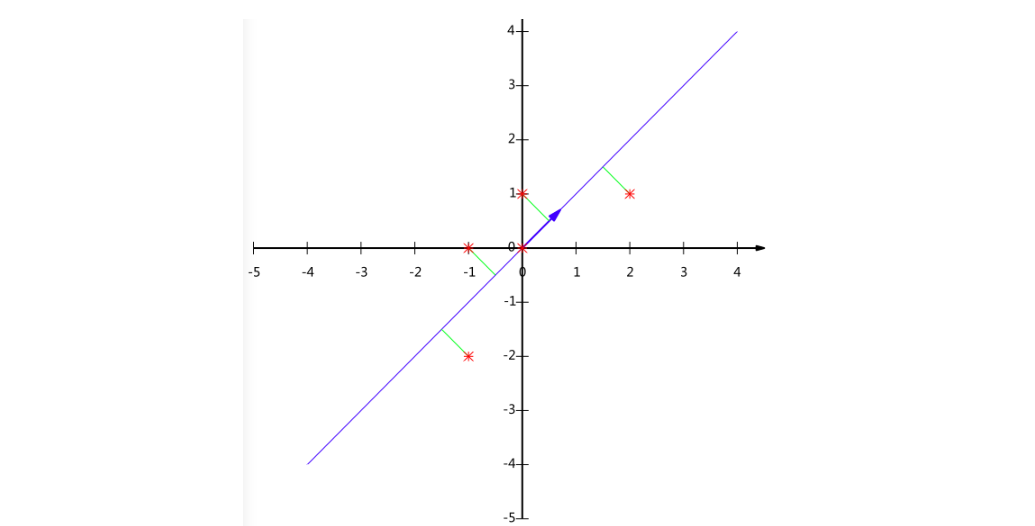
2、LDA(Linear Discriminant Analysis线性判别分析)

左图是PCA,它所作的只是将数据映射到,最方便表示这组数据的坐标轴上。分类效果可能一般。
右图是LDA,可以明显看出,在增加了分类信息之后,两组输入映射到了另外一个坐标轴上,有了这样一个映射,两组数据之间的就变得更易区分了(在低维上就可以区分,减少了很大的运算量)。
LDA的典型方法有Fisher Linear Discriminant等,它求一个线性变换,使样本数据中“between classes scatter matrix”(类间协方差矩阵)和“within classes scatter matrix”(同内协方差矩阵)之比的达到最大。
(三)基于局部信息
基于局部信息的的提取方法也叫Feature-based method。我们考虑一种情况,同一个人的2张照片,它们之间唯一的区别是其中一人的眼睛是闭着的。在整体方法中,所有的特征向量的都可能不同(每一个特征向量都能看到全图信息)。但在在基于特征的方法中,大部分特征保持不变,只有与眼睛周围提取的特征向量会不同。而且,我们可以在基于特征方法中,将描述符设计为对变化(例如缩放、旋转或平移)保持不变。使其鲁棒性更强
基于局部信息的典型算法是LBP(Local Binary Pattern,局部二值模式),由芬兰的T. Ojala, M.Pietikäinen, 和 D. Harwood 在1994年提出,用于图像的局部纹理特征提取。
1、原理
原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。如下图所示:
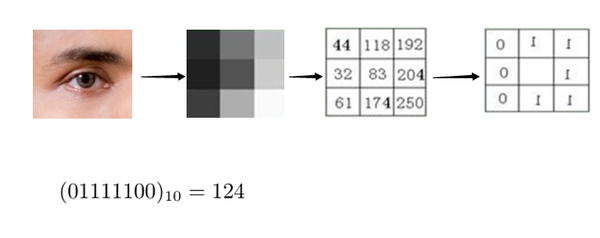
LBP算子利用了周围点与该点的关系对该点进行量化。量化后可以更有效地消除光照对图像的影响。只要光照的变化不足以改变两个点像素值之间的大小关系,那么LBP算子的值不会发生变化,所以一定程度上,基于LBP的识别算法解决了光照变化的问题(图像光照变化不均匀时,各像素间的大小关系被破坏,对应的LBP模式也就发生了变化)。
原始的LBP提出后,研究人员不断对其提出了各种改进和优化,使其具有旋转不变等特性。
经过LBP处理后的如下所示
2、Pipeline
a、首先将检测窗口划分为16×16的小区域(cell);
b、计算每个像素点的LBP值
c、然后计算每个cell的直方图
d、最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量
然后便可利用SVM或者其他机器学习算法进行分类。
二、深度学习算法
因为对人脸识别的许多规律或规则进行显性的描述相当困难,而神经网络方法则可以通过学习,获得这些规律的隐性表达,它的适应性更强。2012年深度学习在ILSVRC大放异彩后,很多研究者都在尝试将其应用在自己的方向,目前深度学习在人脸识别中也取得了非常好的效果。
(一)DeepFace
DeepFace是Facebook在2014年的CVPR上提出来的,后续出现的DeepID和FaceNet也都体现DeepFace的身影,可以说DeepFace是CNN在人脸识别的奠基之作。下边介绍DeepFace的基本框架。
1、网络架构

DeepFace的架构并不复杂,层数也不深。网络架构由6个卷积层 + 2个全连接层构成。
2、Pineline
从实现过程,理解网络
a、图片的3D对齐
输入原始图片,讲过3D对齐后,使人脸的正面朝前(图g)

3D对齐技术可以将图像从2D空间,映射到3维空间,得到人脸特征3维空间的分布,进而可以得到人脸在2D空间下,各种角度的特征分布。
Recongnition任务中,正面照片的分辨效果最好,图g输出人脸的正面图片用来做识别的input,图h输出人脸在45度角下的2D图,用来展示3D对齐的在各个角度下的2D的输出样例。
b、前3层采用传统的conv提取信息
通过3层共享权值的卷积,每一层在整张图片上,提取本层的特征(同一层内,提取的是同一维度上的特征,因为filter一样)

在这里,介绍下共享权重卷积和非共享权重卷积。
1)共享权重
1个卷积核,提取1个特征,卷积核在input图上滑动,提取不同区域的同1种特征(叫做卷积层的参数共享),不同的卷积核,在不同特征的维度上,对input进行特征提取。大部分我们看到的卷积都是这种结构。参数量少,计算速度快。
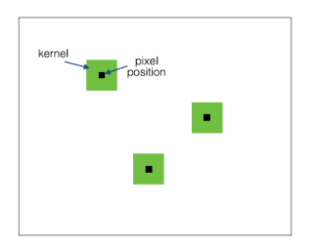
不同的pixel对应的filter相同
如果1个卷积核大小是“5*5*1”,一个图对应的参数是5*5*1, feature map上输出的是,不同部位,同一维度上的特征。
2)非共享权重( Local-Conv),也叫局部连接卷积
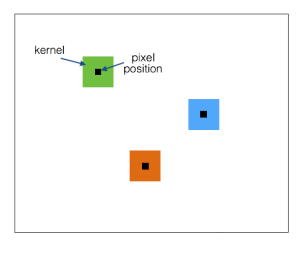
不同的pixel对应的filter不同。
如果1个卷积核大小是“5*5*1”,则1个128*128大小的图上,会有124*124个这样的filter,对应的参数数量是124*124*5*5*1,参数量剧增。因为不同的filter提取的是不同维度上的特征,所以feature map上输出的是不同部位,不同维度上的特征。
这样做的理由是,因为input里面人脸经过了3D对齐和2D映射,输入的图片是矫正后的正面人脸,各特征点的position都固定下来了,人脸部不同位置(鼻子,嘴巴,....)的特征不同,用不同的filter来学习效果更好。
c、后3层conv,采用局部连接层,提取不同维度上的特征。
后3层,采用Local-Conv,提人脸不同位置上的各种不同特征,因为Local-Conv参数量巨大,所以需要使用超大的数据库进行训练。DeepFace采用的是Facebook自己做的SFC数据集,有4030个人的440万张人脸数据。所以用在这里正好~
d、过全连接层,获取图像全局信息
1)过卷积生成的feature map送入第7层,第7层为全连接层,可以感受到上一层传过来的图像的所有信息。
之所以人脸识别的各种架构里面,大部分都含有这一层,原因是,全连接层可以捕捉到人脸距离较远区域的特征之间的关联性。比如,眼睛的位置和形状,与嘴巴的位置和形状之间的关联性,这种关联性,可以contribute to最后一步的recognition score.
2)在第7层对所有特征进行了L2归一化,使其值域落在【0,1】之间,以减弱图像对光照的敏感性.为什么归一化之后就可以减少图像对光照的敏感性?

我的是这样理解的,归一化之前,光照强的图像(如右图)对应的值高,比如左图中某一点a的像素值为100,左图上像素值最大的是200,右图的光线更强,与a点相对应的点a’像素值为110,右图上像素值最大的是220,经过归一化后,左图右图同一点的值,也就相同了。
e、输出4030类的识别结果。
用softmax输出4030种人物的分类信息
3、网络特点
a、提出了3D对齐
3D对齐和3D-2D映射在这里不敷述,paper中觉得这样做,对最后的准确率提升帮助较大。但是现在的网络,在没有采用3D对齐的前提下,也取得漂亮的score.
3D对齐这一块可以先放一放。
b、局部卷积。
局部连接的思想,就跟上面分析的一样,比较好理解。至于这种方法在别的网路中work不work,后面paper看多了应该能有个更清楚的认识。
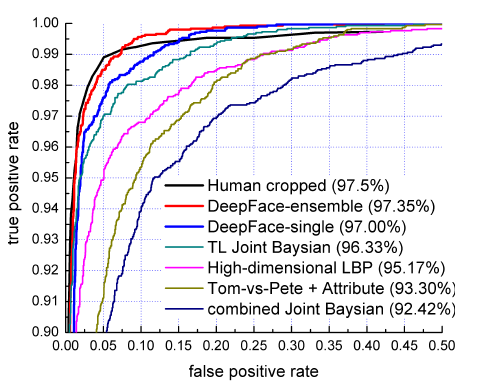
4、网络成绩
DeepFace在LFW数据集中进行人脸识别中取得了97.35%的好成绩,该成绩相对于传统方法中依靠人工显式的提取特征,再进行分类的method,识别准确性获得明显提高,再次证实了CNN在特征提取方面的威力,此外该成绩已经逼近人类在LFW数据集中97.5%的识别成绩,性能卓越。
5、特征度量
虽然网络的output是个4030维的分类结果,paper中还是提出了另外的度量2个图片相似性的方法。
a、内积
文中直接计算两个经过归一化后的特征之间的内积来计算2个图像过backbone后的vector之间的距离,一开始有点不太懂,两个图片相同的话,内积是大还是小?感觉看内积大小分不出来2个图片相似性啊?
后来想了想,这样之所以work,是因为本网络的特殊性。过第7层的fc层后,输出的vector是个4096维的数据,网络架构中采用了relu激活,这4096维中有75%的数据是0,4096维的vector构成了1个稀疏向量。基于这样的前提,两个不同的图片,对应的不同位置上的0和非0元素相乘抵消,内积趋近于0,而相似的2个图片,由于0存在于2个vector相同的位置,非0元素也存在于2个vector相同的位置,0没有和非零元素相抵消,对应的值较大。这样就实现了图片相似性的区分。
Paper中提到的另外2个距离度量算法。
b、X² similarity
按照下面公式乘就可以了,比较简单,没啥好说的
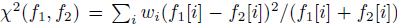

权重参数是由SVM学来的
c、Siamese network孪生网络
当神经网络训练完成后,将其除了L8外的其他层复制为两份,分别输入两张人脸图像,得到特征后,先计算两个feature的绝对差值,然后将其输入给一个新的全连接层(注意不是原来的L8,其只有一个神经元)来进行二分类,判断两张人脸是否身份相同
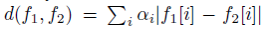
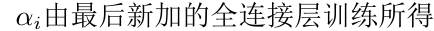
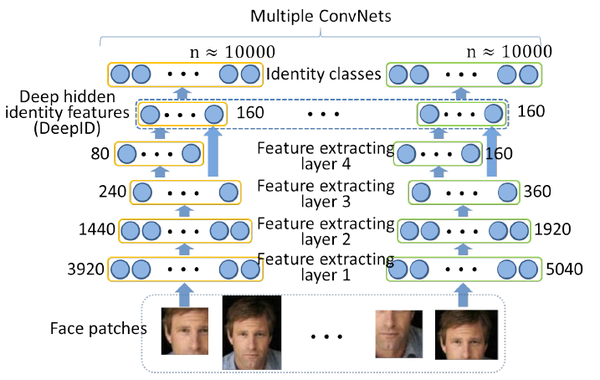
(二)DeepID
DeepID是一种特征提取的算法,由港中文汤晓鸥团队于2014年提出,发表于CVPR2014。其应用领域是人脸识别的子领域——人脸验证,就是判断两张图片是不是同一个人。之前的人脸验证任务主要的方法是使用过完备的(over-complete)低层次特征,结合浅层的机器学习模型进行的。过去的方法常常是将人脸提取出几万乃至几百万的特征,然后将特征进行降维,再计算两个特征的相似度,本文提出一种使用深度学习提取人脸深层次特征(称之为DeepID)的方法。DeepID特征由人脸分类任务学习得到,此特征可以用于人脸验证中,最终在LFW数据集上取得了97.45%的成绩。
1、网络架构
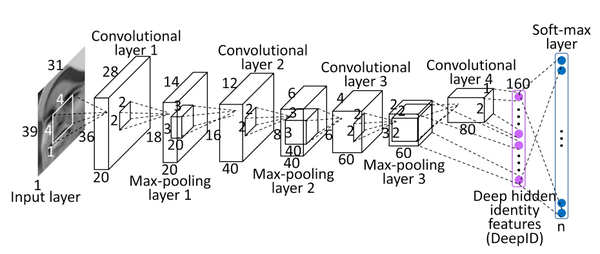
DeepFace的架构并不复杂,层数也不深。网络架构由4个卷积层 + 1个全连接层构成。
2、Pineline
a、做patch
1)截区域
按照人脸特征点的分布,在1张输入图片上取10个区域,如下图所示:

2)数据增强
(1)将每个区域,resize成3中不同尺度的pic,如下图所示:

(2)将图像进行水平翻转

(3)提取灰度图

(4)patches总量
经过前3步的数据增强,此时的1张image,产生了10 * 3 * 2 * 2 = 120个区域,将每1个区域与其水平翻转的区域,送入网络,进行特征提取。此步共训练60个神经网络。输出160*2维的DeepID
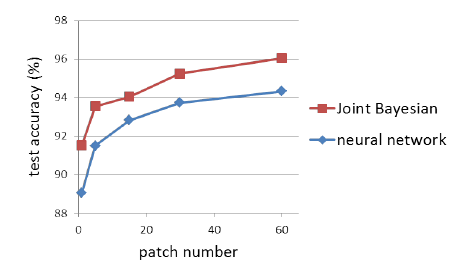
3)增加patches效果
由下图可见,增加patches数量后,网络性能,相对于只用了1整张image的原始结构,提升明显,感觉就是数据增强的原因。
b、过ConvNets

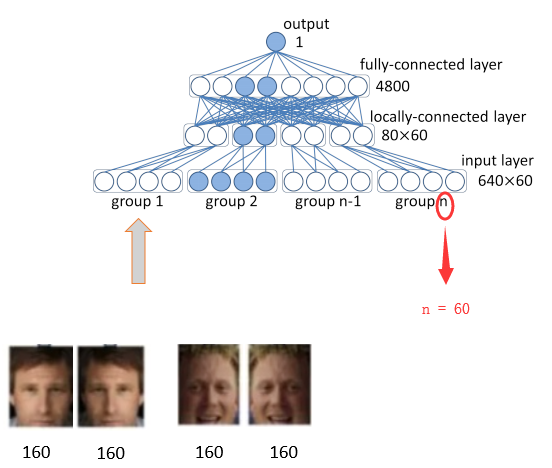
以1个区域的输入为例,如果区域是长方形,则resize成39*31,如果如果区域是正方形,则resize成31*31,假设本次输入的区域是长方形,喂入网络,如上图所示。

图片经过4层卷积,第3层,和第4层的feature map分别是3*2*60,和2*1*80维。将最后2层的feature map分别过全连接层,concatenate成1个160维的vector
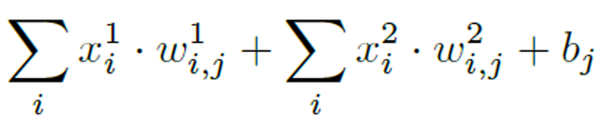
Concatenate方式:在同一维度上叠加
不同hierarchy的Feature map叠加在一起,分类器可以看到多尺度的图像。想当于联系了上下文,网络性能更好。

DeepID自身的分类错误率在40%到60%之间震荡,虽然较高,但DeepID是用来学特征的,并不需要要关注自身分类错误率。
将上文160维的vector送入soft-max进行分类,输出10000分类的结果。60个网络,各自对应各自预测的cls结果,如下图所示:
3、利用DeepID做verification
本来以为做完cls,这个paper就可以结束了,然鹅,看了paper后面密密麻麻的2张,才意识到这个paper是关于verification的,之所以要做cls,主要是多分类的训练,可以提高ConvNet的提取特征的能力,终其目的,还是为了拿到提取的特征,做其关心的verification
a、用前面训练好的网络,对2张图片做verification
每张照片,根据是否水平翻转,分为2组,每组有60个patches(10个区域,每个区域3个size,每个size有RGB和Grey2种模式)
将每1个区域与其水平翻转对应的部分,联合要对比的图片的同一个区域,组着在一起,送入网络,进行特征提取。此步调用了60个神经网络。
每张输入的160维vector,即为那个区域的identity,可视化160维的数据如下,可以看出相同人脸的identity相似度高,不同人脸的identity区别较大。

1张image经过网络,输出120(60个patches,每个patch里2张图)*160=19200维vector,以此vector表征人脸的identity。
将2张face的identity,送入joint Bayesian,判断是否为同1个人。

下面介绍一下classifier里面的joint Bayesian分类器
b、Joint Bayesian
1)经典Bayesian Face
在介绍joint Bayesian之前,先看一下joint Bayesian出现之前,业界广泛使用的经典Bayesian Face,算法描述如下:

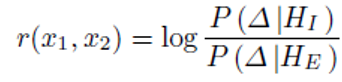
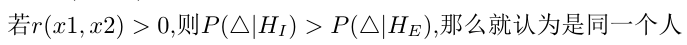
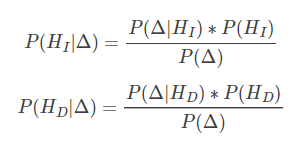
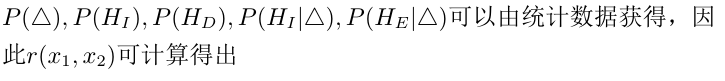
但是经典bayesian从2维投射到1维时,会丧失一些分区信息,导致在2维平面上可分的目标,在1维平面上变得不可区分。
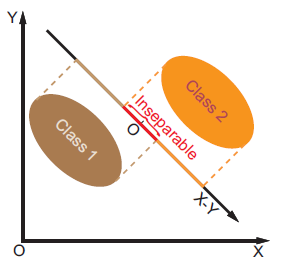
从上图中可以看到,2-D的数据通过差分x-y映射到1-D上。O附近的点交错在一起, 使得在O附近的Class-1 和Class-2 无法区分开来。这就是经典Bayesian Face的缺陷
2)joint Bayesian
针对经典Bayesian Face出现的问题,中科大,港中文以及亚研院的4位同学,在孙剑的指导下于2012年提出来joint Bayesian方法



c、神经网络分类器
14年,当时的verification sota 分类器还是joint Bayesian,神经网络成绩一般,作者试了这2种方法后,选择了性能更优的joint Bayesian

4、网络成绩
DeepID相对于传统的PCA方法,表征能力进一步增强

DeepID在LFW数据集上取得了97.45%的准确率,相比于DeepFace的97.35%,获得了进一步的提高。ROC曲线如下:
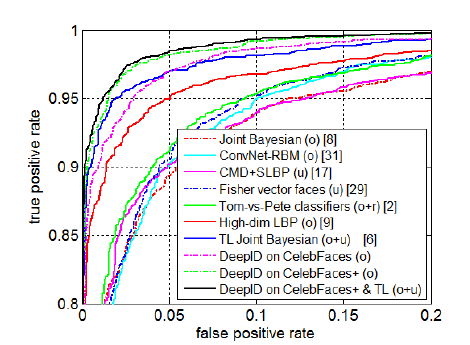
5、数据指标
简单的介绍下ROC,以前看的时候没有仔细去弄明白这个指标,最近看好多paper上都有这个东西,查阅了资料,总结如下
ROC全名叫receiver operating characteristic curve,中文译为:接收者操作特征曲线,用以说明二分类器在识别阈值变化时的诊断能力。
ROC将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。绘图方法如下
a、统计样本分类score
将一系列样本,按照positive可能性得分,进行排序
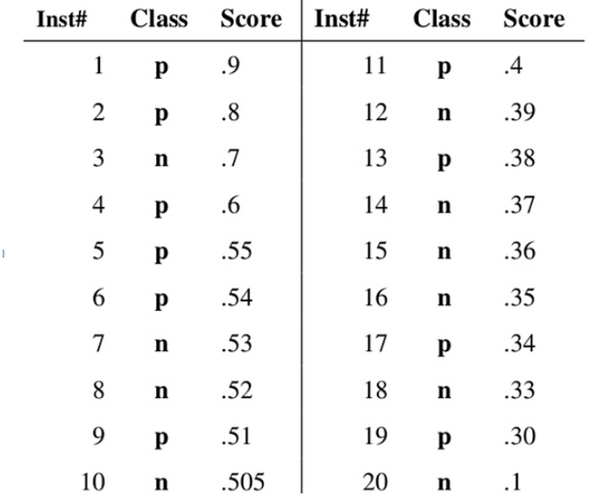
b、计算真阳率和假阳率
以score作为阈值,依次对排好序的样本进行判断,score > threshold, 则判定为Positive, 否则判为Negative,每一个threshold计算1次真阳率和假阳率,做出这个20个样本的真阳率-假阳率对应图。
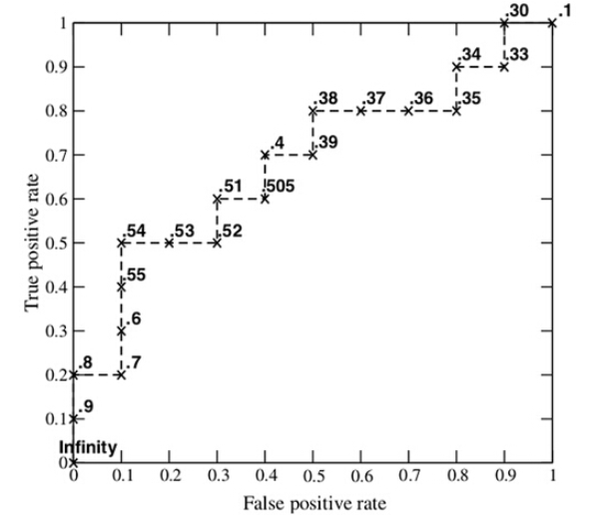
c、ROC曲线优势
为什么要使用ROC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。下图是ROC曲线和Presision-Recall曲线的对比:

(a)和(c)为Roc曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果,可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线变化较大。
6、小结
分类数提高,可以学到表征力更强的identity
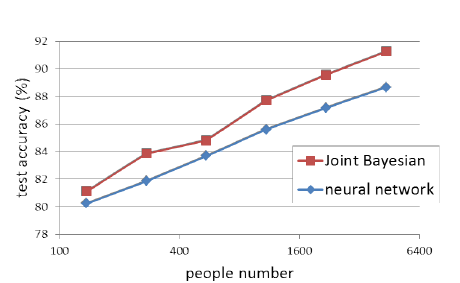
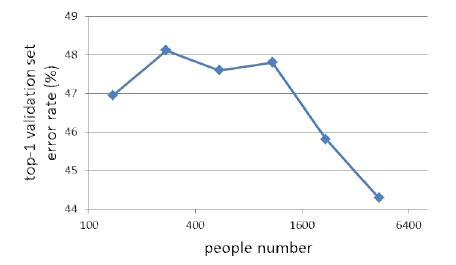
用更多的分类来训练网络,测试的error rate持续降低。一开始还疑惑DeepID初衷是做verification,为什么一开始要用softmax做cls,其实原因到这里就明了了,分类越多,学到的160维的identity表征力越强。
(三)DeepID_v2
港中文汤晓鸥团队在DeepId_v1基础上提出的新版本架构,发表于NIPS2014
1、Architecture
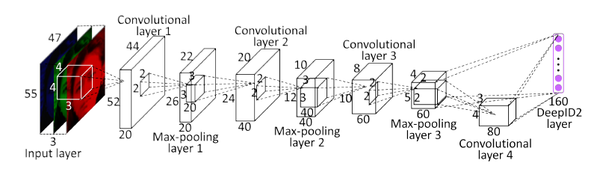
网络架构基本上与DeepId_v1一致。
2、Pipeline
图片被分成20regions,每个region有5scales,2RGB&Gray共10种模式,共生成200个pathes,进行水平翻转,分别送入200个网络中。
以1个55 * 47的RGB 模式patch为例,过程和DeepID_v1相似,最后生成1个160维的向量。
用前后向贪心算法,从400个DeepID中,筛选出25个有效且互补的DeepID2向量,缩减计算规模,得到160*25 = 4000的特征值。

再利用PCA对此向量进行降维,得到1* 180的向量,以此向量为依据,做cls和verif,cls用交叉熵,verif用join Bayesian。
3、相比于DeepID_V1的改动
网络结构没有多大改动,重点是在loss计算上。众所周知,表征人脸的特征最好能使不同的人脸之间的差异尽可能大,使相同人脸的不同照片人脸之间差异尽可能小。我们希望得到一个网路,这个网络计算出来的特征vector尽可能满足上述条件。设计loss函数如下:
a、分类loss

F是特征向量,θid是softmax层参数,t是label的分类结果。
b、Verification loss
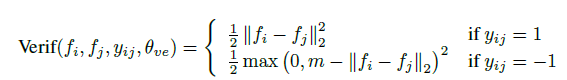
1)类内loss
当
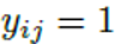
,input image和标签数据是同一个分类,此时训练网络,使之与label中的特征,尽可能的相近。
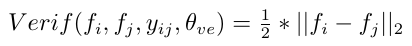
2)类间loss
当
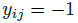
,input image和标签数据属于不同分类,

m为超参数,事先指定好。由上图知,当输入的图片的特征vector,和label的vector差异很大,其L2距离超过m时,loss值为0,网络倾向于学习,使类间距离尽可能的大的vector。
总Verification loss为类间loss和类内loss的加权和,权重各为0.5。
之前业界普遍采用的方法是L1/L2范式和余弦相似度,文中采用一种基于L2 Norm的损失函数。paper中作者测试了其他几种距离算法对准确率的影响,L2距离的性能最好。
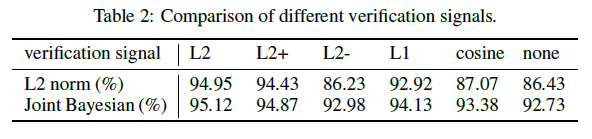
c、cls和verif的组合
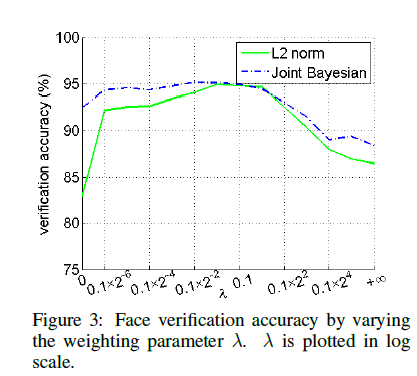
选取合适的λ,调整verif loss在总loss中的系数,当λ=0时,不计算verfi的loss,文中选取λ=0.5
4、网络成绩
LFW共有5749个人的数据,共13233张脸。数据集太小,paper中引入外部数据集CelebFace+,有10177个人的数据,共202599张脸。
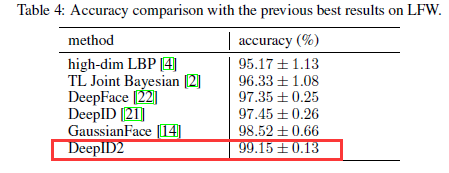
为充分利用从大量图像块中提取到的特征,作者重复使用7次前项后向贪婪算法选取特征,每次的选择是从之前的选择中未被留下的部分中进行选取。然后在每次选择的特征上,训练联合贝叶斯模型。再将这七个联合贝叶斯模型使用SVM进行融合,得到最佳的效果在LFW上为99.15%。