---恢复内容开始---
在Windows平台下,当Java源代码中包含中文字符时,如果我们利用代码编辑器保存代码时是utf-8编码格式保存,那么我们在用javac编译时会出现“错误:编码GBK的不可映射字符”。
我们在用javac编译时,编译程序首先会获得我们windows操作系统默认采用的编码格式(GBK),这样在从硬盘读取java文件的时候(此时在硬盘中的表现形式是之前存储java文件时utf-8编码成的字节流文件)就相当于按GBK格式解码,而原编码为utf-8,就会发生解码错误,导致无法编译。当我们不加设置就编译时,相当于使用了参数:javac -encoding GBK Strean.java,就会出现不兼容的情况。解决以上问题有如下两种方式:
1.用-encoding参数指明编码方式:javac -encoding UTF-8 Stream.java,这样就相当于利用utf-8格式对硬盘读取出的java文件进行解码,不会出现解码错误问题。
2.利用代码编辑器对java文件进行转换编码格式存储,换成GBK编码存储方式存储即可。
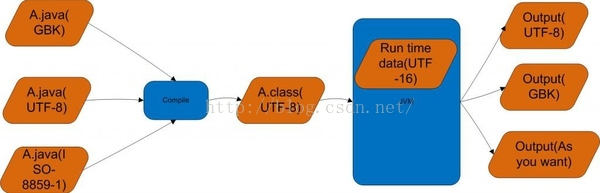
当采用上述2方式解决时,java编译器将Java源文件从GBK编码格式转换为Java内部默认的Unicode格式放入内存中,然后javac把转换后的Unicode格式的文件编译成class文件存储,class文件是Unicode编码的。当我们运行 java Stream 命令时,java解释器将此文件以Unicode格式编码的class文件保存到jvm内存中形成运行文件。具体的java编译器采用utf8,在java编译阶段是utf8,此时还未涉及到java解释器,即class文件的存储是用utf8,因为相对于utf16,utf8在处理英文占用内存小,而程序大部分都是英文。jvm运行时的编码方式是utf16,即jvm用utf8从class文件读取程序后再转化为utf16编码的字符串,因为utf16是2个字节,统一的长度更方便jvm申请数组等操作。
需要注意的是,一般涉及到IO操作时,我们只要保证编码和解码字符集一致就可以防止乱码。有些应用程序如果不注意指定字符编码,中文环境中取操作系统默认编码,如果编解码都在中文环境中,通常也没问题,但是还是强烈的不建议使用操作系统的默认编码,因为这样,你的应用程序的编码格式就和运行环境绑定起来了,在跨环境下很可能出现乱码问题。
参考:1.https://www.cnblogs.com/maohuidong/p/8044568.html
2.https://zhidao.baidu.com/question/494528739317154332.html
3.https://blog.csdn.net/qitehuanjue/article/details/52682820