什么是拉丁超立方抽样法?它和蒙特卡罗模拟有什么关系?
逆变换方法(The Inverse Transform Method)采样
拉丁超立方抽样
拉丁超立方抽样(LHS)是一种从多维分布中生成参数值的近随机样本的统计方法。抽样方法常用于构建计算机实验或进行蒙特卡罗积分。在统计抽样的上下文中,当(且仅当)每行和每列只有一个样本时,包含样本位置的方格为拉丁方格。拉丁超立方体是将这个概念推广到任意数量的维数,因此每个样本是包含它的每个轴向超平面上的唯一一个样本。
在简单随机抽样中,不考虑之前生成的样本点,生成新的样本点。我们并不需要事先知道需要多少采样点。
在拉丁超立方抽样中,首先必须决定使用多少采样点,并且记住每个采样点是在哪一行和哪一列中采样的。请注意,这种配置类似于在不互相威胁的情况下,在棋盘上有N辆車。
拉丁超立方抽样也是蒙特卡洛模拟法的一种,它改进了采样策略能够做到以较小的采样规模获得较高的采样精度,在实际应用中具有高效性很受欢迎。核心步骤为分层抽样、打乱排序。

概率密度函数PDF和累计概率密度函数CDF

拉丁超立方抽样原理示意图
蒙特卡罗抽样技术完全是随机的,即在输入分布的范围内,样本可以落在任何位置。样本更有可能从高发生概率的分布区域中抽取。在累积分布中,每个蒙特卡罗样本使用一个0 和 1之间的新的随机数。在足够的迭代之后,蒙特卡罗抽样通过抽样“重建”输入分布。但是,当执行的迭代次数少的时候,会产生聚集的问题。
拉丁超立方体抽样是抽样技术的最新进展,和蒙特卡罗方法相比,它被设计成通过较少迭代次数的抽样,准确地重建输入分布。拉丁超立方体抽样的关键是对输入概率分布进行分层。分层在累积概率尺度(0,1.0)上把累积曲线分成相等的区间。然后,从输入分布的每个区间或“分层”中随机抽取样本。抽样被强制代表每个区间的值,于是,被强制重建输入概率分布。
假设我们要在n维向量空间里抽取m个样本。拉丁超立方体抽样的步骤是:
(1)将每一维分成互不重迭的m个区间,使得每个区间有相同的概率
(通常考虑一个均匀分布,这样区间的长度相同)。
(2)在每一维里的每一个区间中随机的抽取一个点;
(3)再从每一维里随机抽出(2)中选取的点,将它们组成向量。
在抽样时,每个区间都抽取一个样本。使用拉丁超立方体方法,样本更加准确地反映输入概率分布中值的分布。在拉丁超立方体抽样中使用的技术是“抽样不替换”,累积分布的分层数目等于执行的迭代次数。
matlab实现拉丁超立方抽样(逆变换法)
1. 从离散均匀分布U[1, 1024]中抽样10000个点
x = unidinv(linspace(0+eps, 1, 10000), 1024); idx = randperm(length(x)); y = x(idx); figure plot(y, '.') figure plot(unique(x), 'o') xlim([0, 1024])
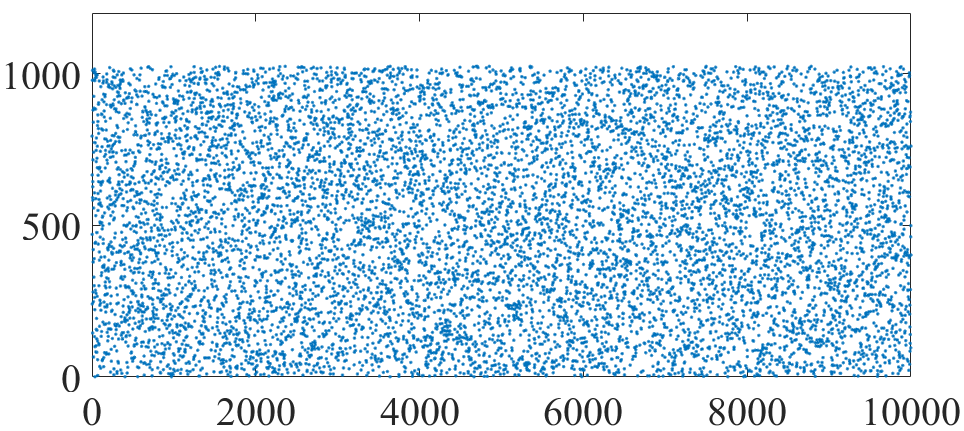
抽样结果

抽样结果区间分布
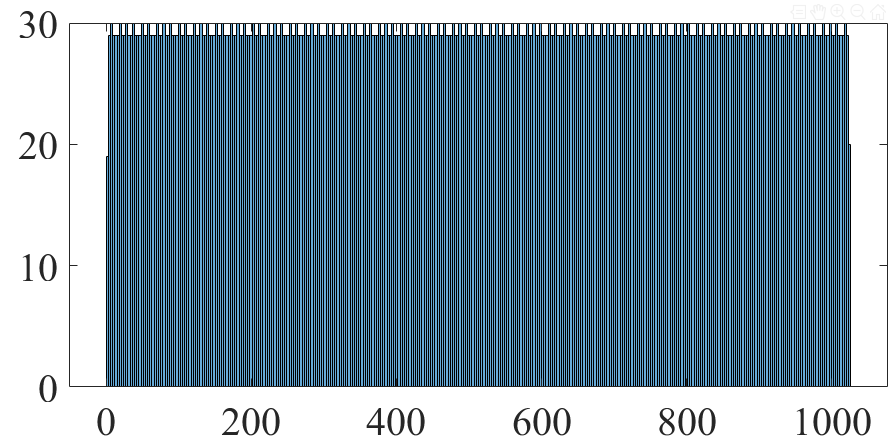
直方图(binwidth=3)
可以看到拉丁超立方的好处是覆盖率高(因为这里即使仅抽取1024个点,也能覆盖整个抽样区间)。
2. 从高斯分布N(5, 3)中抽样
x = norminv(linspace(0+eps, 1, 10000), 5, 3); idx = randperm(length(x)); y = x(idx); figure plot(y, '.') figure histogram(y, 'binwidth', 0.1)
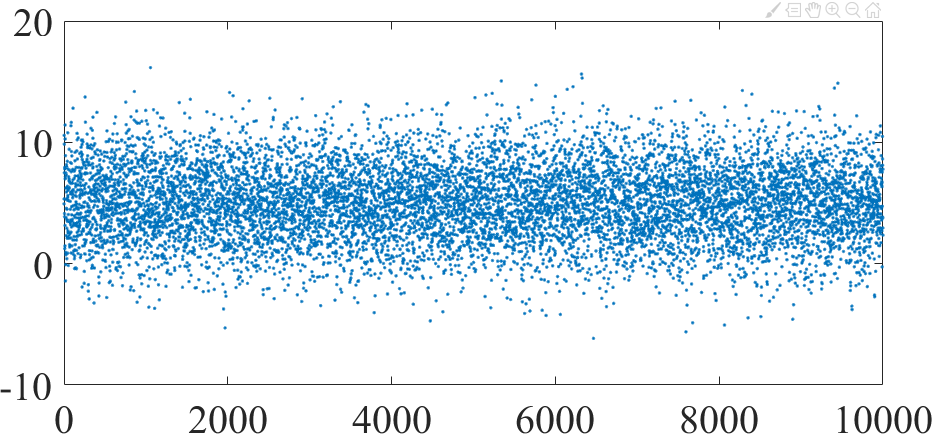
抽样结果
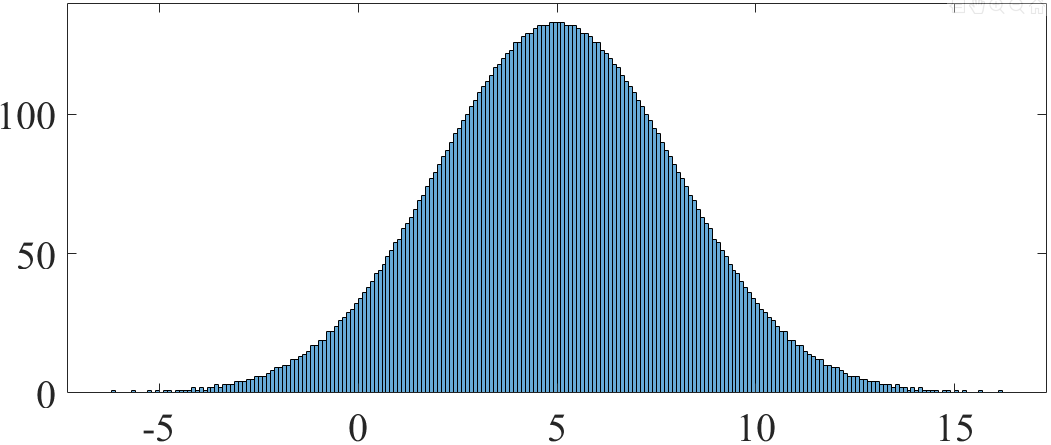
直方图(binwidth=0.1)
3. matlab中常用分布的PDF、CDF和逆CDF
可以看到逆变换法需要用到CDF的逆,这里给出matlab中常见的概率分布。
来自:https://blog.csdn.net/leo2351960/article/details/39207299/
统计工具箱函数 Ⅰ-1 概率密度函数 函数名 对应分布的概率密度函数 betapdf 贝塔分布的概率密度函数 binopdf 二项分布的概率密度函数 chi2pdf 卡方分布的概率密度函数 exppdf 指数分布的概率密度函数 evpdf 最大值型的极值I型分布(Gumbel分布) fpdf f分布的概率密度函数 gampdf 伽玛分布的概率密度函数 geopdf 几何分布的概率密度函数 hygepdf 超几何分布的概率密度函数 normpdf 正态(高斯)分布的概率密度函数 lognpdf 对数正态分布的概率密度函数 nbinpdf 负二项分布的概率密度函数 ncfpdf 非中心f分布的概率密度函数 nctpdf 非中心t分布的概率密度函数 ncx2pdf 非中心卡方分布的概率密度函数 poisspdf 泊松分布的概率密度函数 raylpdf 雷利分布的概率密度函数 tpdf 学生氏t分布的概率密度函数 unidpdf 离散均匀分布的概率密度函数 unifpdf 连续均匀分布的概率密度函数 weibpdf 威布尔分布的概率密度函数 Ⅰ-2 累加分布函数 函数名 对应分布的累加函数 betacdf 贝塔分布的累加函数 binocdf 二项分布的累加函数 chi2cdf 卡方分布的累加函数 expcdf 指数分布的累加函数 evcdf 最大值型的极值I型分布(Gumbel)的累加函数 fcdf f分布的累加函数 gamcdf 伽玛分布的累加函数 geocdf 几何分布的累加函数 hygecdf 超几何分布的累加函数 logncdf 对数正态分布的累加函数 nbincdf 负二项分布的累加函数 ncfcdf 非中心f分布的累加函数 nctcdf 非中心t分布的累加函数 ncx2cdf 非中心卡方分布的累加函数 normcdf 正态(高斯)分布的累加函数 poisscdf 泊松分布的累加函数 raylcdf 雷利分布的累加函数 tcdf 学生氏t分布的累加函数 unidcdf 离散均匀分布的累加函数 unifcdf 连续均匀分布的累加函数 weibcdf 威布尔分布的累加函数 Ⅰ-3 累加分布函数的逆函数 函数名 对应分布的累加分布函数逆函数 betainv 贝塔分布的累加分布函数逆函数 binoinv 二项分布的累加分布函数逆函数 chi2inv 卡方分布的累加分布函数逆函数 expinv 指数分布的累加分布函数逆函数 evinv Gumbel分布的逆函数 finv f分布的累加分布函数逆函数 gaminv 伽玛分布的累加分布函数逆函数 geoinv 几何分布的累加分布函数逆函数 hygeinv 超几何分布的累加分布函数逆函数 logninv 对数正态分布的累加分布函数逆函数 nbininv 负二项分布的累加分布函数逆函数 ncfinv 非中心f分布的累加分布函数逆函数 nctinv 非中心t分布的累加分布函数逆函数 ncx2inv 非中心卡方分布的累加分布函数逆函数 icdf norminv 正态(高斯)分布的累加分布函数逆函数 poissinv 泊松分布的累加分布函数逆函数 raylinv 雷利分布的累加分布函数逆函数 tinv 学生氏t分布的累加分布函数逆函数 unidinv 离散均匀分布的累加分布函数逆函数 unifinv 连续均匀分布的累加分布函数逆函数 weibinv 威布尔分布的累加分布函数逆函数
4. python库pyDOE
pyDOE是python环境下进行试验设计的包。
可以进行拉丁超立方抽样
https://pythonhosted.org/pyDOE/randomized.html#latin-hypercube
https://github.com/tisimst/pyDOE
https://github.com/clicumu/pyDOE2
基本语法
from pyDOE import lhs lhs(n, [samples, criterion, iterations]) # n: 维度, integer # samples:采样点数, integer # criterion:default "None" # 一个告诉 lhs 如何采样点的字符串(默认值:无,它只是随机化间隔内的点) # “center”或“c”:将采样间隔内的点居中 # “maximin”或“m”:最大化点之间的最小距离,但将点放在其间隔内的随机位置 # “centermaximin”或“cm”:与“maximin”相同,但在间隔内居中 # “correlation”或“corr”:最小化最大相关系数 # 输出设计将所有变量范围从零缩放到一,然后可以根据用户的意愿进行转换 #(例如使用 scipy.stats.distributions ppf(逆累积分布)函数转换为特定的统计分布。
抽样
例如,二维标准高斯分布抽样:
>>> from scipy.stats import norm >>> lhd = lhs(2, samples=5) >>> lhd = norm(loc=0, scale=1).ppf(lhd) # this applies to both factors here
Out[28]:
array([[ 0.75863463, -0.3369805 ],
[-0.00529301, 0.99955206],
[-1.07653807, -0.1303521 ],
[-0.36624876, 0.3676775 ],
[ 0.8589196 , -0.85595459]])
拉丁超立方抽样原理示意图
计算过程也很直观,首先基于cdf的逆进行分层区间抽样,然后通过期望分布函数进行变换即可。
python环境下的统计分布从scipy.stats包导入。包括连续分布和离散分布。累计分布的逆采用ppf()得到。
https://docs.scipy.org/doc/scipy/tutorial/stats.html
|
pdf() |
Probability density function. |
|
cdf() |
Cumulative distribution function. |
|
ppf() |
Percent point function (inverse of |
从离散分布中抽样也是一样:
from scipy.stats import randint lhd = lhs(6, samples=10) lhd = randint(0, 5).ppf(lhd) # sample from U[0, 5)
Out[31]:
array([[1., 1., 2., 1., 3., 2.],
[4., 0., 1., 3., 1., 3.],
[2., 3., 2., 2., 2., 4.],
[2., 4., 0., 4., 4., 1.],
[3., 3., 3., 2., 0., 1.],
可以指定在每个区间采样的准则:
lhs(4, criterion='center')
array([[ 0.875, 0.625, 0.875, 0.125],
[ 0.375, 0.125, 0.375, 0.375],
[ 0.625, 0.375, 0.125, 0.625],
[ 0.125, 0.875, 0.625, 0.875]])
还可以为每个维度指定不同的分布参数:
例如,现在,假设我们想将这些设计转换为正态分布,均值=[1,2,3,4],标准差= [0.1,0.5,1,0.25]:
>>> design = lhs(4, samples=10)
>>> from scipy.stats.distributions import norm
>>> means = [1, 2, 3, 4]
>>> stdvs = [0.1, 0.5, 1, 0.25]
>>> for i in xrange(4):
... design[:, i] = norm(loc=means[i], scale=stdvs[i]).ppf(design[:, i])
...
>>> design
array([[ 0.84947986, 2.16716215, 2.81669487, 3.96369414],
[ 1.15820413, 1.62692745, 2.28145071, 4.25062028],
[ 0.99159933, 2.6444164 , 2.14908071, 3.45706066],
[ 1.02627463, 1.8568382 , 3.8172492 , 4.16756309],
[ 1.07459909, 2.30561153, 4.09567327, 4.3881782 ],
[ 0.896079 , 2.0233295 , 1.54235909, 3.81888286],
[ 1.00415 , 2.4246118 , 3.3500082 , 4.07788558],
[ 0.91999246, 1.50179698, 2.70669743, 3.7826346 ],
[ 0.97030478, 1.99322045, 3.178122 , 4.04955409],
[ 1.12124679, 1.22454846, 4.52414072, 3.8707982 ]])