机器学习任务可以分为三类:
- 有监督学习:用于分类、回归预测等,训练数据有标签
- 无监督学习:无标签
- 强化学习:通过与环境交互,训练智能体做出一系列动作使得累积奖励最大化
为了解决以上机器学习任务,机器学习的核心思想是函数逼近。存在不同类型的函数逼近器:线性模型、SVM、决策树、高斯过程、深度学习等。
一、有监督学习(supervised learning)
有监督学习可以描述为找出输入输出之间的一种映射关系。一个重要的前提是假设训练样本满足I.I.D条件。有监督学习算法可以看做是一个函数,将数据集映射到模型。


训练数据 + 有监督学习算法 = 预测模型。假设一个随机采样机制,训练样本集从对应的分布中随机采样,即训练样本集DLS是一个随机变量。那么对应的预测值也是一个
随机变量,它在输入空间上对应的平均误差也是随机变量。那么,我们可以计算模型在输入空间上平均误差的期望值。

二、偏差、方差和过拟合
如果损失函数取二范数的形式,那么误差可以自然地分解为一个偏差项和一个方差项。
这种偏差 - 方差分解可能很有用,因为它强调了由于模型选择或学习算法中的错误假设导致的误差(偏差)与由于只有一组有限的数据可供模型学习而导致的误差(参数方差)之间的权衡。
也即:
偏差(bias):由于模型选择或学习算法中的错误假设导致的误差。
参数方差(parametric variance):数据集中可供模型学习的数据有限引起的误差。
注意,参数方差也称为过拟合误差(overfitting error)。


对于任何给定的模型,通过考虑强收敛定律,参数方差随着数据集的不断增大而趋于零。
尽管其他损失函数没有这种直接分解(James,2003),但总是需要在足够复杂的模型(减少模型偏差,即使数据量不受限制也存在)和模型不太复杂(以避免过度拟合有限数量的数据)
之间进行权衡。(当模型非常复杂时,可能模型偏差会减小,但是不可避免导致过拟合问题,反之亦然。因此,偏差和过拟合之间存在着一种权衡。)

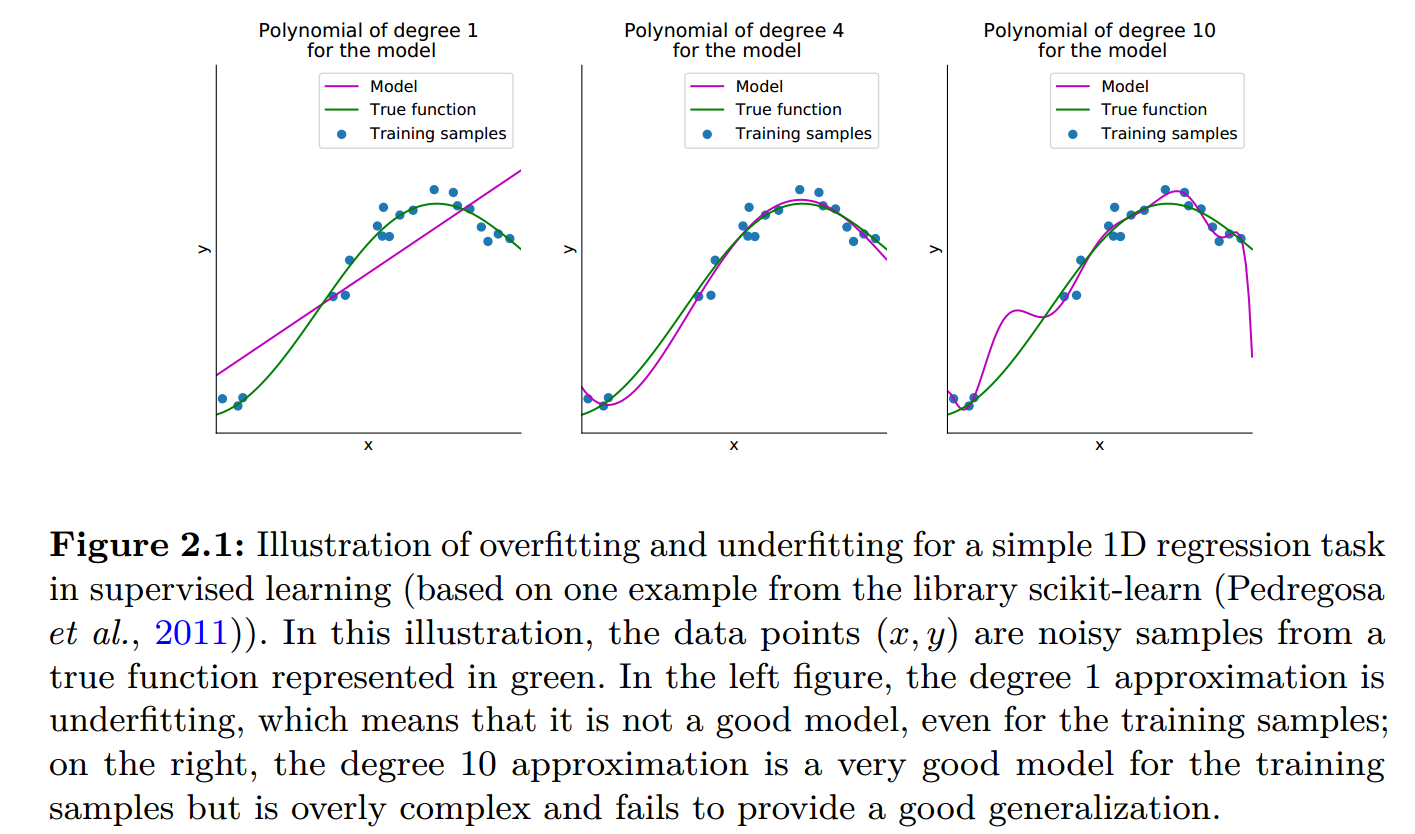
左侧图中,采用1自由度的模型近似,存在欠拟合问题,意味着它并不是一个好的模型,即使对于训练样本而言预测结果也很糟糕。
右侧图中,采用10自由度的模型近似,对于训练样本而言是一个非常好的模型,但是由于模型过于复杂而难以提供好的泛化能力(过拟合)。
中间的图中,采用4自由度的模型逼近,可以看到,不管是在训练样本上,还是在整个样本分布上,预测值的误差都很小,模型的泛化能力强(泛化误差的定义见下文)。
三、模型的泛化误差
如果我们不知道上述随机变量的联合概率密度分布PDF,则无法计算输入空间X上平均误差的期望值 I[f]。
![]()
但是我们可以计算数据样本的经验误差(用样本误差的平均值估计真实的误差期望值,样本估计整体IID假设)。(模型训练时是使该经验误差最小化。)

泛化误差的定义:模型在训练集上误差(图中紫线与数据点)与在潜在联合概率密度分布上的误差(图中紫线与绿线?)之间的差异。

尽管缺乏强大的理论基础,但实践中已经清楚,深度神经网络的优势是它们的泛化能力,尽管其含有有大量参数(因此可能具有较高的复杂度)(Zhang et al,2016)。

参考文献:
Vincent François-Lavet, Peter Henderson, Riashat Islam, Marc G. Bellemare and Joelle
Pineau (2018), “An Introduction to Deep Reinforcement Learning”, Foundations and
Trends in Machine Learning: Vol. 11, No. 3-4. DOI: 10.1561/2200000071.