引言
ZooKeeper是中典型的pub/sub模式的分布式数据管理与协调框架,开发人员可以使用它进行分布式数据的发布与订阅。另外,其丰富的数据节点类型可以交叉使用,配合Watcher事件通知机制,可以应用于分布式都会涉及的一些核心功能:数据发布/订阅、Master选举、命名服务、分布式协调/通知、集群管理、分布式锁、分布式队列等。本博文主要介绍:发布/订阅、分布式锁、Master选举三种最常用的场景
本文中的代码示例均是由Curator客户端编写的,已经对ZooKeeper原生API做好很多封装。参考资料《从Paxos到Zookeeper 分布式一致性原理与实践》(有需要电子PDF的朋友,可以评论私信我)
一、数据发布/订阅
1、基本概念
(1)数据发布/订阅系统即所谓的配置中心,也就是发布者将数据发布到ZooKeeper的一个节点或者一系列节点上,提供订阅者进行数据订阅,从而实现动态更新数据的目的,实现配置信息的集中式管理和数据的动态更新。ZooKeeper采用的是推拉相结合的方式:客户端向服务器注册自己需要关注的节点,一旦该节点的数据发生改变,那么服务端就会向相应的客户端发送Wacher事件通知,客户端接收到消息通知后,需要主动到服务端获取最新的数据。
(2)实际系统开发过程中:我们可以将初始化配置信息放到节点上集中管理,应用在启动时都会主动到ZooKeeper服务端进行一次配置读取,同时在指定节点注册Watcher监听,主要配置信息一旦变更,订阅者就可以获取读取最新的配置信息。通常系统中需要使用一些通用的配置信息,比如机器列表信息、运行时的开关配置、数据库配置信息等全局配置信息,这些都会有以下3点特性:
1) 数据量通常比较小(通常是一些配置文件)
2) 数据内容在运行时会经常发生动态变化(比如数据库的临时切换等)
3) 集群中各机器共享,配置一致(比如数据库配置共享)。
(3)利用的ZooKeeper特性是:ZooKeeper对任何节点(包括子节点)的变更,只要注册Wacther事件(使用Curator等客户端工具已经被封装好)都可以被其它客户端监听
2、代码示例


package com.lijian.zookeeper.demo; import org.apache.curator.RetryPolicy; import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFrameworkFactory; import org.apache.curator.framework.recipes.cache.NodeCache; import org.apache.curator.framework.recipes.cache.NodeCacheListener; import org.apache.curator.retry.ExponentialBackoffRetry; import org.apache.zookeeper.CreateMode; import java.util.concurrent.CountDownLatch; public class ZooKeeper_Subsciption { private static final String ADDRESS = "xxx.xxx.xxx.xxx:2181"; private static final int SESSION_TIMEOUT = 5000; private static final String PATH = "/configs"; private static RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); private static String config = "jdbc_configuration"; private static CountDownLatch countDownLatch = new CountDownLatch(4); public static void main(String[] args) throws Exception { // 订阅该配置信息的集群节点(客户端):sub1-sub3 for (int i = 0; i < 3; i++) { CuratorFramework consumerClient = getClient(); subscribe(consumerClient, "sub" + String.valueOf(i)); } // 更改配置信息的集群节点(客户端):pub CuratorFramework publisherClient = getClient(); publish(publisherClient, "pub"); } private static void init() throws Exception { CuratorFramework client = CuratorFrameworkFactory.builder() .connectString(ADDRESS) .sessionTimeoutMs(SESSION_TIMEOUT) .retryPolicy(retryPolicy) .build(); client.start(); // 检查节点是否存在,不存在则初始化创建 if (client.checkExists().forPath(PATH) == null) { client.create() .creatingParentsIfNeeded() .withMode(CreateMode.EPHEMERAL) .forPath(PATH, config.getBytes()); } } /** * 创建客户端并且初始化建立一个存储配置数据的节点 * * @return * @throws Exception */ private static CuratorFramework getClient() throws Exception { CuratorFramework client = CuratorFrameworkFactory.builder() .connectString(ADDRESS) .sessionTimeoutMs(SESSION_TIMEOUT) .retryPolicy(retryPolicy) .build(); client.start(); if (client.checkExists().forPath(PATH) == null) { client.create() .creatingParentsIfNeeded() .withMode(CreateMode.EPHEMERAL) .forPath(PATH, config.getBytes()); } return client; } /** * 集群中的某个节点机器更改了配置信息:即发布了更新了数据 * * @param client * @throws Exception */ private static void publish(CuratorFramework client, String znode) throws Exception { System.out.println("节点[" + znode + "]更改了配置数据..."); client.setData().forPath(PATH, "configuration".getBytes()); countDownLatch.await(); } /** * 集群中订阅的节点客户端(机器)获得最新的配置数据 * * @param client * @param znode * @throws Exception */ private static void subscribe(CuratorFramework client, String znode) throws Exception { // NodeCache监听ZooKeeper数据节点本身的变化 final NodeCache cache = new NodeCache(client, PATH); // 设置为true:NodeCache在第一次启动的时候就立刻从ZooKeeper上读取节点数据并保存到Cache中 cache.start(true); System.out.println("节点["+ znode +"]已订阅当前配置数据:" + new String(cache.getCurrentData().getData())); // 节点监听 countDownLatch.countDown(); cache.getListenable().addListener(new NodeCacheListener() { @Override public void nodeChanged() { System.out.println("配置数据已发生改变, 节点[" + znode + "]读取当前新配置数据: " + new String(cache.getCurrentData().getData())); } }); } }
运行结果:节点[pub]更改了配置数据为“configuration”,订阅"/configs"节点的sub1-sub3观测到配置被改变,立马读取当前最新的配置数据“configuration”

二、Master选举
1、基本概念
(1)在一些读写分离的应用场景中,客户端写请求往往是由Master处理的,而另一些场景中,Master则常常负责处理一些复杂的逻辑,并将处理结果同步给集群中其它系统单元。比如一个广告投放系统后台与ZooKeeper交互,广告ID通常都是经过一系列海量数据处理中计算得到(非常消耗I/O和CPU资源的过程),那就可以只让集群中一台机器处理数据得到计算结果,之后就可以共享给整个集群中的其它所有客户端机器。
(2)利用ZooKeeper的特性:利用ZooKeeper的强一致性,即能够很好地保证分布式高并发情况下节点的创建一定能够保证全局唯一性,ZooKeeper将会保证客户端无法重复创建一个已经存在的数据节点,也就是说如果多个客户端请求创建同一个节点,那么最终一定只有一个客户端请求能够创建成功,这个客户端就是Master,而其它客户端注在该节点上注册子节点Wacther,用于监控当前Master是否存活,如果当前Master挂了,那么其余客户端立马重新进行Master选举。
(3)竞争成为Master角色之后,创建的子节点都是临时顺序节点,比如:_c_862cf0ce-6712-4aef-a91d-fc4c1044d104-lock-0000000001,并且序号是递增的。需要注意的是这里有"lock"单词,这说明ZooKeeper这一特性,也可以运用于分布式锁。

2、代码示例
package com.lijian.zookeeper.demo; import org.apache.curator.RetryPolicy; import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFrameworkFactory; import org.apache.curator.framework.recipes.leader.LeaderSelector; import org.apache.curator.framework.recipes.leader.LeaderSelectorListenerAdapter; import org.apache.curator.retry.ExponentialBackoffRetry; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.atomic.AtomicInteger; public class ZooKeeper_Master { private static final String ADDRESS="xxx.xxx.xxx.xxx:2181"; private static final int SESSION_TIMEOUT=5000; private static final String MASTER_PATH = "/master_path"; private static final int CLIENT_COUNT = 5; private static RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); public static void main(String[] args) throws InterruptedException { ExecutorService service = Executors.newFixedThreadPool(CLIENT_COUNT); for (int i = 0; i < CLIENT_COUNT; i++) { final String index = String.valueOf(i); service.submit(() -> { masterSelect(index); }); } } private static void masterSelect(final String znode){ // client成为master的次数统计 AtomicInteger leaderCount = new AtomicInteger(1); CuratorFramework client = CuratorFrameworkFactory.builder() .connectString(ADDRESS) .sessionTimeoutMs(SESSION_TIMEOUT) .retryPolicy(retryPolicy) .build(); client.start(); // 一旦执行完takeLeadership,就会重新进行选举 LeaderSelector selector = new LeaderSelector(client, MASTER_PATH, new LeaderSelectorListenerAdapter() { @Override public void takeLeadership(CuratorFramework curatorFramework) throws Exception { System.out.println("节点["+ znode +"]成为master"); System.out.println("节点["+ znode +"]已经成为master次数:"+ leaderCount.getAndIncrement()); // 睡眠5s模拟成为master后完成任务 Thread.sleep(5000); System.out.println("节点["+ znode +"]释放master"); } }); // autoRequeue自动重新排队:使得上一次选举为master的节点还有可能再次成为master selector.autoRequeue(); selector.start(); } }
运行结果:由于执行selector.autoRequeue()方法,被选举为master后的节点可能会再次获被选举为master,所以会一直循环执行,以下只截图部分。其中获取成为master的次数充分表明了Master选举的公平性。

三、分布式锁
1、基本概念
(1)对于排他锁:ZooKeeper通过数据节点表示一个锁,例如/exclusive_lock/lock节点就可以定义一个锁,所有客户端都会调用create()接口,试图在/exclusive_lock下创建lock子节点,但是ZooKeeper的强一致性会保证所有客户端最终只有一个客户创建成功。也就可以认为获得了锁,其它线程Watcher监听子节点变化(等待释放锁,竞争获取资源)。
对于共享锁:ZooKeeper同样可以通过数据节点表示一个锁,类似于/shared_lock/[Hostname]-请求类型(读/写)-序号的临时节点,比如/shared_lock/192.168.0.1-R-0000000000
2、代码示例
Curator提供的有四种锁,分别如下:
(1)InterProcessMutex:分布式可重入排它锁
(2)InterProcessSemaphoreMutex:分布式排它锁
(3)InterProcessReadWriteLock:分布式读写锁
(4)InterProcessMultiLock:将多个锁作为单个实体管理的容器
主要是以InterProcessMutex为例,编写示例:
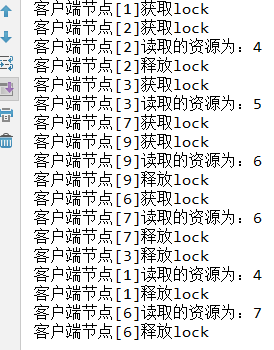
package com.lijian.zookeeper.demo; import org.apache.curator.RetryPolicy; import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFrameworkFactory; import org.apache.curator.framework.recipes.locks.InterProcessMutex; import org.apache.curator.retry.ExponentialBackoffRetry; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class ZooKeeper_Lock { private static final String ADDRESS = "xxx.xxx.xxx.xxx:2181"; private static final int SESSION_TIMEOUT = 5000; private static final String LOCK_PATH = "/lock_path"; private static final int CLIENT_COUNT = 10; private static RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); private static int resource = 0; public static void main(String[] args){ ExecutorService service = Executors.newFixedThreadPool(CLIENT_COUNT); for (int i = 0; i < CLIENT_COUNT; i++) { final String index = String.valueOf(i); service.submit(() -> { distributedLock(index); }); } } private static void distributedLock(final String znode) { CuratorFramework client = CuratorFrameworkFactory.builder() .connectString(ADDRESS) .sessionTimeoutMs(SESSION_TIMEOUT) .retryPolicy(retryPolicy) .build(); client.start(); final InterProcessMutex lock = new InterProcessMutex(client, LOCK_PATH); try { // lock.acquire(); System.out.println("客户端节点[" + znode + "]获取lock"); System.out.println("客户端节点[" + znode + "]读取的资源为:" + String.valueOf(resource)); resource ++; // lock.release(); System.out.println("客户端节点[" + znode + "]释放lock"); } catch (Exception e) { e.printStackTrace(); } } }
运行结果:加锁后可以从左图看到读取的都是最新的资源值。如果去掉锁的话读取的资源值不能保证是最新值看右图