Manacher Algorithm算法,俗称马拉车算法,其时间复杂为O(n)。该算法是利用回文串的特性来避免重复计算的,至于如何利用,且由后面慢慢道来。
在时间复杂度为O(n^2)的算法中,我们在遍历的过程要考虑到回文串长度的奇偶性,比如说“abba”的长度为偶数,“abcba”的长度为奇数,这样在寻找最长回文子串的过程要分别考奇偶的情况,是否可以统一处理了?
一)第一步是改造字符串S,变为T,其改造的方法如下:
在字符串S的字符之间和S的首尾都插入一个“#”,如:S=“abba”变为T="#a#b#b#a#" 。我们会发现S的长度是4,而T的长度为9,长度变为奇数了!!那S的长度为奇数的情况时,变化后的长度还是奇数吗?我们举个例子,S=“abcba”,变化为T=“#a#b#c#b#a#”,T的长度为11,所以我们发现其改造的目的是将字符串的长度变为奇数,这样就可以统一的处理奇偶的情况了。
二)第二步,为了改进回文相互重叠的情况,我们将改造完后的T[ i ] 处的回文半径存储到数组P[ ]中,P[ i ]为新字符串T的T[ i ]处的回文半径,表示以字符T[i]为中心的最长回文字串的最端右字符到T[i]的长度,如以T[ i ]为中心的最长回文子串的为T[ l, r ],那么P[ i ]=r-i+1。这样最后遍历数组P[ ],取其中最大值即可。若P[ i ]=1表示该回文串就是T[ i ]本身。举一个简单的例子感受一下:

数组P有一性质,P[ i ]-1就是该回文子串在原字符串S中的长度 ,那就是P[i]-1就是该回文子串在原字符串S中的长度,至于证明,首先在转换得到的字符串T中,所有的回文字串的长度都为奇数,那么对于以T[i]为中心的最长回文字串,其长度就为2*P[i]-1,经过观察可知,T中所有的回文子串,其中分隔符的数量一定比其他字符的数量多1,也就是有P[i]个分隔符,剩下P[i]-1个字符来自原字符串,所以该回文串在原字符串中的长度就为P[i]-1。
另外,由于第一个和最后一个字符都是#号,且也需要搜索回文,为了防止越界,我们还需要在首尾再加上非#号字符,实际操作时我们只需给开头加上个非#号字符,结尾不用加的原因是字符串的结尾标识为'�',等于默认加过了。
1 //设t为将要进行预处理的字符串,则处理实现如下 2 string t="@#"; 3 for(int i=0;i<str.size();i++) 4 { 5 t=t+str[i]; 6 t=t+"#"; 7 }
这样原问题就转化成如何求数组P[ ]的问题了。
三)如何求数组P [ ]
从左往右计算数组P[ ], Mi为之前取得最大回文串的中心位置,而R是最大回文串能到达的最右端的值。
1)当 i <=R时,如何计算 P[ i ]的值了?毫无疑问的是数组P中点 i 之前点对应的值都已经计算出来了。利用回文串的特性,我们找到点 i 关于 Mi 的对称点 j ,其值为 j= 2*Mi-i 。因,点 j 、i 在以Mi 为中心的最大回文串的范围内([L ,R]),
a)那么如果P[j] <R-i (同样是L和j 之间的距离),说明,以点 j 为中心的回文串没有超出范围[L ,R],由回文串的特性可知,从左右两端向Mi遍历,两端对应的字符都是相等的。所以P[ j ]=P[ i ](这里得先从点j转到点i 的情况),如下图:

b)如果P[ j ]>=R-i (即 j 为中心的回文串的最左端超过 L),如下图所示。即,以点 j为中心的最大回文串的范围已经超出了范围[L ,R] ,这种情况,等式P[ j ]=P[ i ]还成立吗?显然不总是成立的!因,以点 j 为中心的回文串的最左端超过L,那么在[ L, j ]之间的字符肯定能在( j, Mi ]找到相等的,由回文串的特性可知,P[ i ] 至少等于R- i,至于是否大于R-i(图中红色的部分),我们还要从R+1开始一一的匹配,直达失配为止,从而更新R和对应的Mi以及P[ i ]。

2)当 i > R时,如下图。这种情况,没法利用到回文串的特性,只能老老实实的一步步去匹配。

如果还不是很懂,看看另一个博客中给出的例子(懂了可以跳过)
现在,想象你在"abaaba"中心画一道竖线,你是否注意到数组P围绕此竖线是中心对称的?再试试"aba"的中心,P围绕此中心也是对称的。这当然不是巧合,而是在某个条件下的必然规律。我们将利用此规律减少对数组P中某些元素的重复计算。
我们来看一个重叠得更典型的例子,即S="babcbabcbaccba"。

上图展示了把S转换为T的样子。假设你已经算出了一部分P。竖实线表示回文"abcbabcba"的中心C,两个虚实线表示其左右边界L和R。你下一步要计算P[i],i围绕C的对称点是i’。你有办法高效地计算P[i]吗?
我们先看一下i围绕C的对称点i’(此时i’=9)。

据上图所示,很明显P[i]=P[i’]=1。这是因为i和i’围绕C对称。同理,P[12]=P[10]=0,P[14]=P[8]=0。

现在再看i=15处。此时P[15]=P[7]=7?错了,你逐个字符检测一下会发现此时P[15]应该是5。
为什么此时规则变了?

如上图所示,两条绿色实线划定的范围必定是对称的,两条绿色虚线划定的范围必定也是对称的。此时请注意P[i’]=7,超过了左边界L。超出的部分就不对称了。此时我们只知道P[i]>=5,至于P[i]还能否扩展,只有通过逐个字符检测才能判定了。
在此例中,P[21]≠P[9],所以P[i]=P[15]=5。
相应的代码如下:
1 string Manacher(string s) 2 { 3 /*改造字符串*/ 4 string res="$#"; 5 for(int i=0;i<s.size();++i) 6 { 7 res+=s[i]; 8 res+="#"; 9 } 10 11 /*数组*/ 12 vector<int> P(res.size(),0); 13 int mi=0,right=0; //mi为最大回文串对应的中心点,right为该回文串能达到的最右端的值 14 int maxLen=0,maxPoint=0; //maxLen为最大回文串的长度,maxPoint为记录中心点 15 16 for(int i=1;i<res.size();++i) 17 { 18 P[i]=right>i ?min(P[2*mi-i],right-i):1; //关键句,文中对这句以详细讲解 19 20 while(res[i+P[i]]==res[i-P[i]]) 21 ++P[i]; 22 23 if(right<i+P[i]) //超过之前的最右端,则改变中心点和对应的最右端 24 { 25 right=i+P[i]; 26 mi=i; 27 } 28 29 if(maxLen<P[i]) //更新最大回文串的长度,并记下此时的点 30 { 31 maxLen=P[i]; 32 maxPoint=i; 33 } 34 } 35 return s.substr((maxPoint-maxLen)/2,maxLen-1); 36 }
原文地址:https://www.cnblogs.com/love-yh/p/7072161.html
自己根据习惯改的模板(可忽略)
1 string Manacher(string str) 2 { 3 /*改造字符串*/ 4 string res="$#"; 5 for(int i=0;i<str.size();i++) 6 { 7 res+=str[i]; 8 res+="#"; 9 } 10 /*数组*/ 11 vector<int> P(res.size(),0); 12 int mi=0;// mi为最大回文串对应的中心点 13 int right=0;//right为该回文串能达到的最右端的值 14 int maxlen=0;//maxlen为最大回文串的长度 15 int maxpoint=0;//maxpoint为记录中心点 16 for(int i=1;i<res.size();i++)//注意i从1开始 17 { 18 if(right>i)//关键句 19 P[i]=min(P[2*mi-i],right-i); 20 else 21 P[i]=1; 22 while(res[i+P[i]]==res[i-P[i]]) 23 ++P[i]; 24 if(right<i+P[i])//超过之前的最右端,则改变中心点和对应的最右端 25 { 26 mi=i; 27 right=i+P[i]; 28 } 29 if(P[i]>maxlen)//更新最大回文串的长度,并记下此时的点 30 { 31 maxlen=P[i]; 32 maxpoint=i; 33 } 34 } 35 return str.substr((maxpoint-maxlen)/2,maxlen-1);//返回最长子串 36 }
下文摘自https://www.luogu.org/blog/codesonic/manacheralgorithm
正文
题意是求S中的最长回文串
最暴力的做法当然是枚举l和r,对于每个l和r求遍历一遍判断是否为回文
时间复杂度达到 O(n^3) ,显然做不了这题
在这个基础上稍微优化一下,也是很显然的做法:长度为奇数回文串以最中间字符的位置为对称轴左右对称,而长度为偶数的回文串的对称轴在中间两个字符之间的空隙。可以遍历这些对称轴,在每个对称轴上同时向左和向右扩展,直到左右两边的字符不同或者到达边界。
这样的复杂度是 O(n^2),还是过不了
观察数据范围, S.length()<=11000000,应该需要一个 O(n) 及以下的算法
dalao云
暴力算法的优化是信息的利用和对重复搜索的去重
我们考虑如何利用这里的重复信息
第一种解法,是直接暴力计算
而第二种解法,是利用字符串对称的性质,把枚举端点变成枚举中点,少了一个循环,优化掉 O(n) 的复杂度
我们所求的 O(n)算法,是不是能由第二种解法再利用一次字符串对称的性质得来呢?
观察下面的字符串:
O A K A B A K A B A O A K
其中的最长回文串为 ABAKABA ,若使用第二种解法,有什么可以不计算的呢?
相信很容易猜到,一个回文串的左半边有一个回文串,那它的右半边也有一个,那么我们对这个回文串的计算显然可以略去
扩展到一般性质,若一个回文串里包含着另一个回文串,那这个回文串的另一边必然存在另一个与它一模一样的回文串!
由此我们来改进第二种算法
这个 O(n^2) 算法有什么缺点呢?
- 回文串长度的奇偶性造成了对称轴的位置可能在某字符上,也可能在两个字符之间的空隙处,要对两种情况分别处理
如何解决?我们可以强行在原字符串中插入其他本字符串不会出现的字符,如"#"
也就是说,若原来的字符串是这样

那么我们把它改成这样
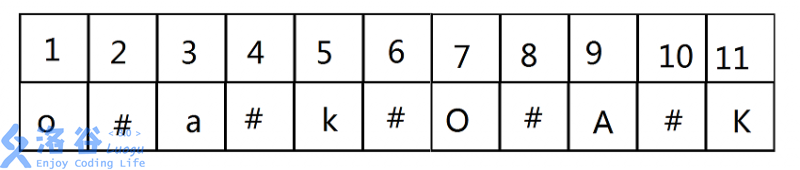
关于这部分的代码:
1 inline void change() { 2 s[0]=s[1]='#'; 3 for(int i=0; i<n; i++) { 4 s[i*2+2]=a[i]; 5 s[i*2+3]='#'; 6 } 7 n=n*2+2; 8 s[n]=0; 9 }
这样我们就可以直接以每个字符为对称轴进行扩展了
- 会出现很多子串被重复多次访问,时间效率大幅降低。
这个就是我们刚刚提出的优化了。
我们用一个辅助数组 hwi表示 i 点能够扩展出的回文长度
我们先设置一个辅助变量 maxright,表示已经触及到的最右边的字符
以及一个辅助变量 mid ,表示包含 maxright 的回文串的对称轴所在的位置
也就是这样:

当i在maxright左边且在mid右边时:
设i关于mid的对称点为j,显然 hwi一定不会小于 hwj。
我们没必要保存j,j可以通过计算得出,为 mid+(mid-i)=(mid imes2)-imid+(mid−i)=(mid×2)−i
那么我们就将 hwi设为 hwj ,从 i+hwi开始扩展(利用已知信息),这样就可以较快地求出hw[i],然后重新maxright和mid
当 ii 在 maxright右边时,我们无法得知关于 hwi的信息,只好从1开始遍历,然后更新 maxright和 mid
这部分的代码也是非常简短的:
1 inline void manacher() { 2 int maxright=0,mid; 3 for(int i=1; i<n; i++) { 4 if(i<maxright) 5 hw[i]=min(hw[(mid<<1)-i],hw[mid]+mid-i); 6 else 7 hw[i]=1; 8 while(s[i+hw[i]]==s[i-hw[i]]) 9 ++hw[i]; 10 if(hw[i]+i>maxright) { 11 maxright=hw[i]+i; 12 mid=i; 13 } 14 } 15 }
虽然看起来优化不了多少,但它的时间复杂度确实是 O(n) 的,下面证明一下
分两种情况讨论
1.在遍历i的时候,maxright没有右移
那么 hwi 可以直接得出,计算是 O(1) 的
2.在遍历i的时候,maxright右移了
这个时候,设maxright右移了s个单位
因为maxright需要右移n个单位,所以复杂度是 O(n)
习题
一道几乎是裸题的题
看到回文串可以想想马拉车,于是我们就用马拉车写
在朴素的马拉车基础上求出l和r数组, li 表示i所在回文串中的最右端的下标, ri代表i所在回文串中的最左端的下标
然后拼接一下即可
SP7586 NUMOFPAL - Number of Palindromes
求一个串中包含几个回文串
用马拉车求出以每个字母为对称轴的回文串长度,因为一个回文串长度/2就是这个回文串包含的子回文串长度,所以最后统计一下即可~
声明:我博客里有大量的从别的博客复制过来的代码,分析,以及理解,但我一律会在文章后面标记原博客大佬博客地址,其中部分会加以连接。 绝无抄袭的意思,只是为了我在复习的时候找博客方便。 如有原作者对此有不满,请在博客留言,我一定会删除该博文。