1:为什么要进行normolize

【注】1:希望把输入的值控制在有效的范围内
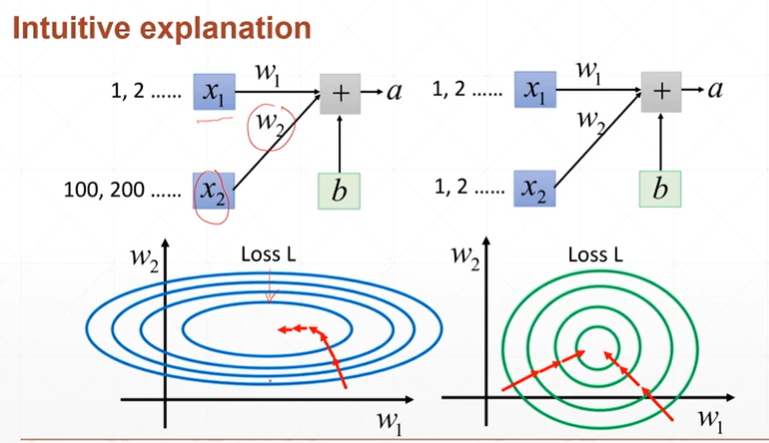
【注】希望能够进行高效的查询最优解。例如:当x2值大,x1值偏小时,w1的改变导致的影响较小,w2的改变导致的影响较大。
2:Normlization的种类
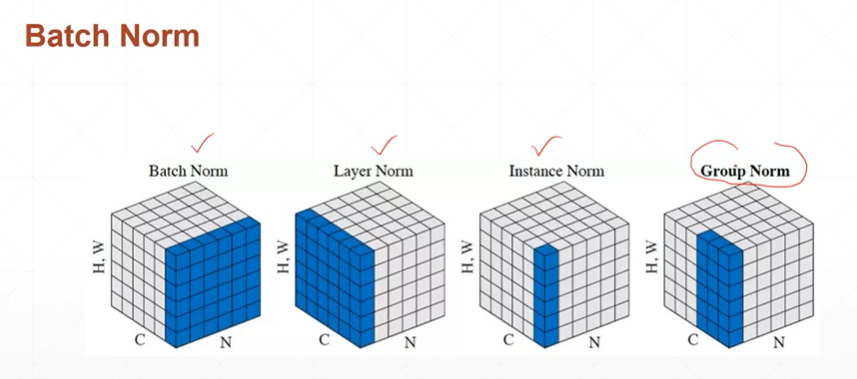
3:Batch Norm
(3.1)Batch Norm的图解
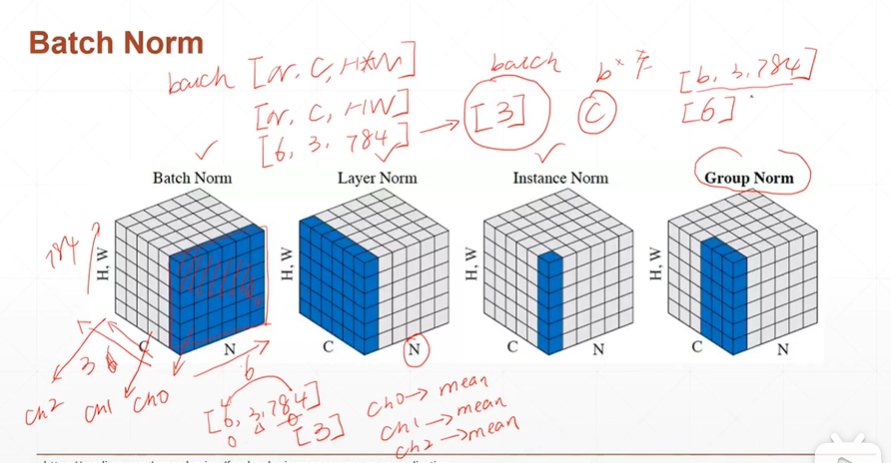
【注】Batch Norm实际统计的会得到一个维度为1大小为channel的tensor。其统计的时每一个channel的均值和方差。
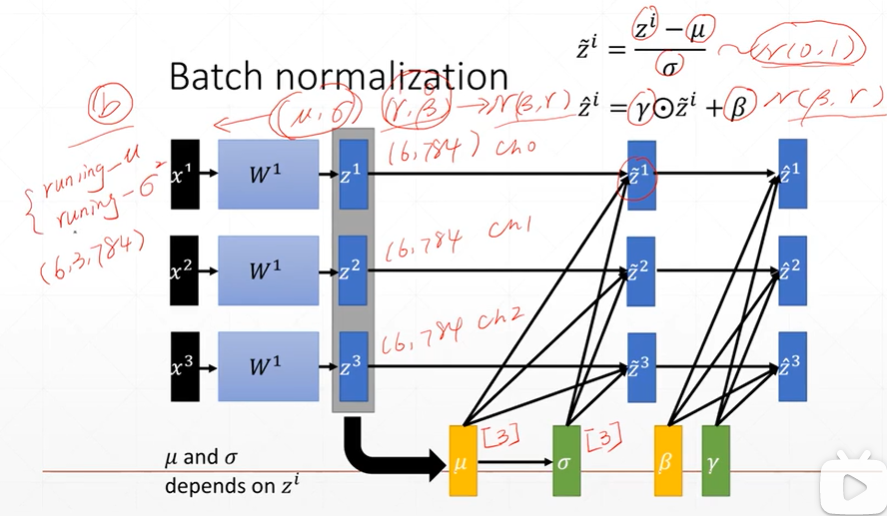
【注】
μ和σ**2都是每一次运行一个batch得到的统计数据。β和γ时通过最初设置,然后通过不断的学习得到。
running-μ和running-σ**2是总batch运行完之后的全局统计数据。
(3.2):Batch Norm在pytorch的使用
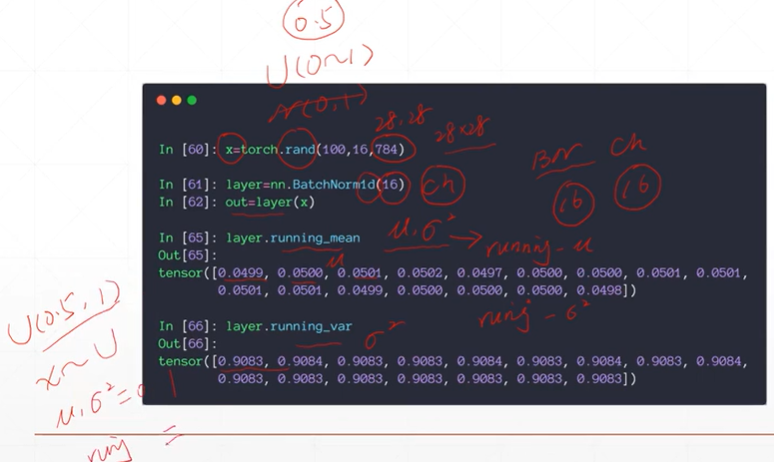
[注]layer.running_mean统计的为全局的均值,layer.ruuning_var统计的为全局的方差。
[注]nn.BatchNorm1d(pa1)其中的参数为channel的大小。这里之所以为1d是因为2d(28*28)被拉平成1d(784)。
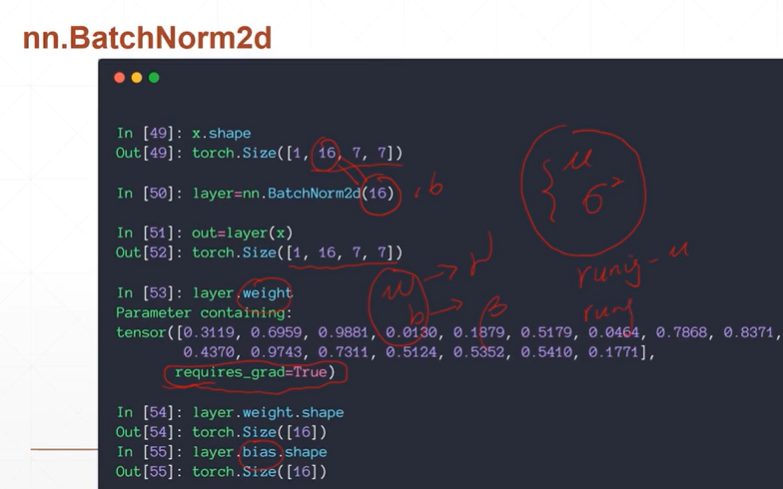
[注]上图中的weight和bias分别表示缩放公式中的:γ,β
[注]在BatchNorm2d中不能直接查看每一个batch的均值和方差,只能查看全局的均值和方差。
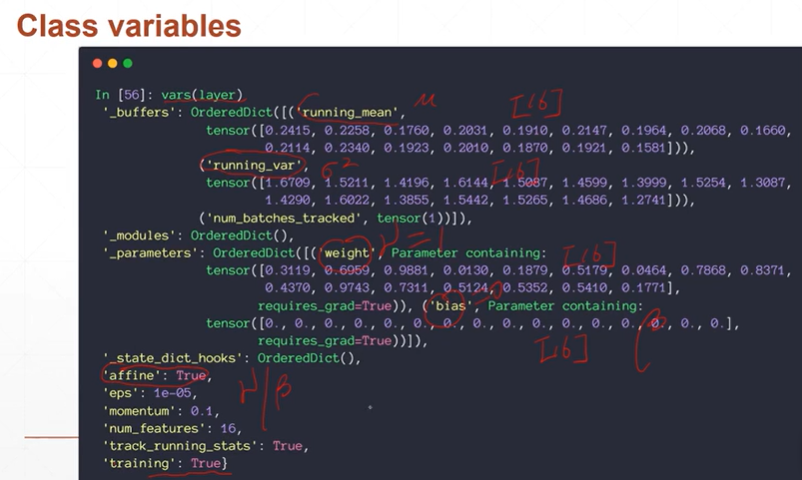
【注】'training':true表示当前的模式为训练,'affine':True表示当前的γ和β是否需要自动学习。
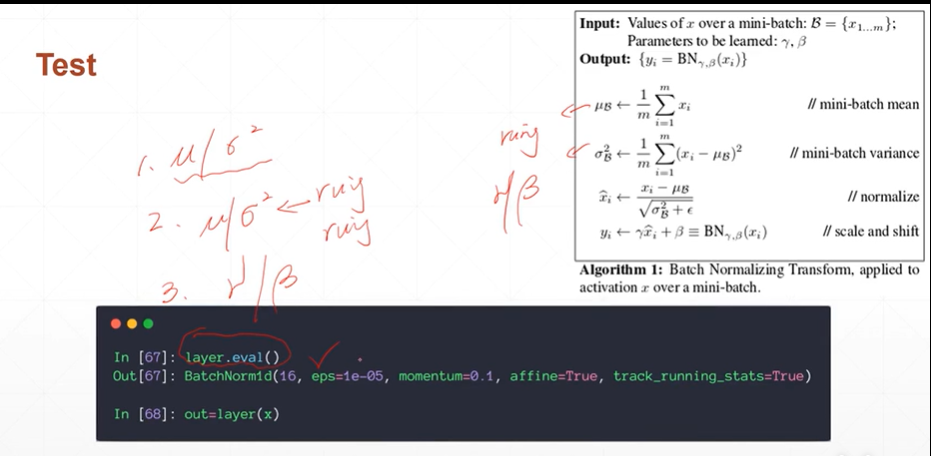
【注】在test模式下,不需要计算μ和σ**2.只需要将全局的running 的值赋值给其即可。Test模式下不能backward故γ和β不需要更新。故Test模式下进行时,记得首先使用layer.eval()将模式切换到Test下。
(3.3)Batch Norm的标准计算

[注]上图是1,2步是当前Batch的均值和方差的计算。3,4步为规范化的计算以及缩放。
4:使用Normlization的好处
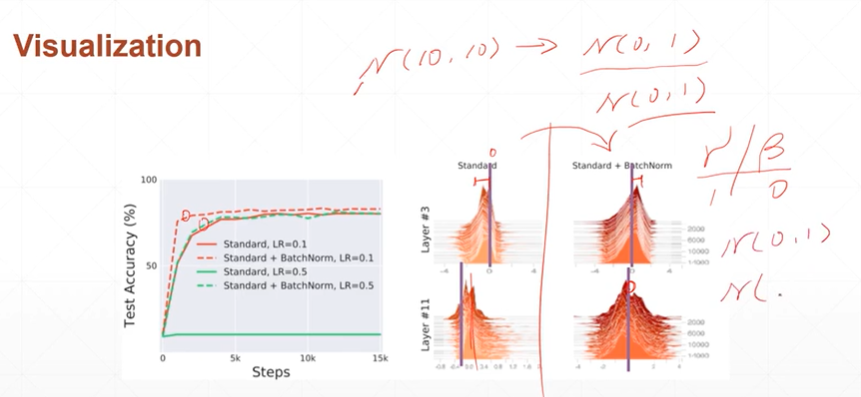
【注】均值和方差更加靠近0和1.

[注]优点:收敛更快,更容易找到最优解,更加稳定(1:降低不收敛或者梯度为0(梯度弥散)现象的出现,2:调整参数时,敏感度降低以使得lr能有更大的调整范围)