[转载]Pytorch详解NLLLoss和CrossEntropyLoss
来源:https://blog.csdn.net/qq_22210253/article/details/85229988
pytorch的官方文档写的也太简陋了吧…害我看了这么久…
NLLLoss
在图片单标签分类时,输入m张图片,输出一个mN的Tensor,其中N是分类个数。比如输入3张图片,分三类,最后的输出是一个33的Tensor,举个例子:
第123行分别是第123张图片的结果,假设第123列分别是猫、狗和猪的分类得分。
可以看出模型认为第123张都更可能是猫。
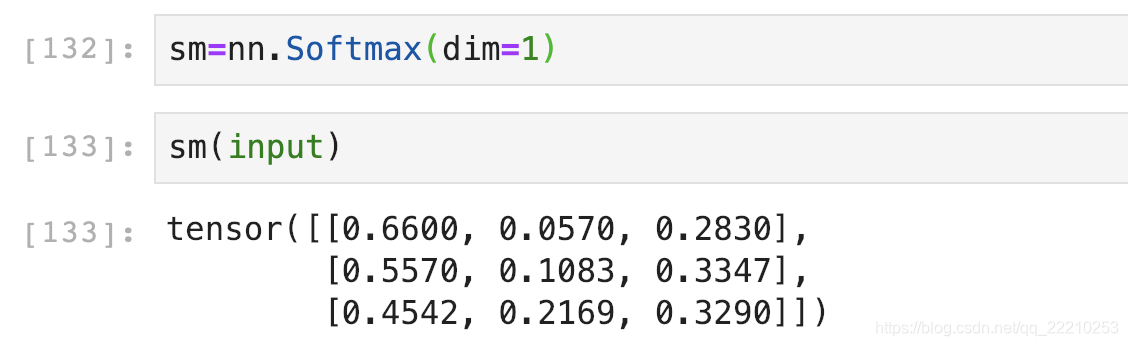
然后对每一行使用Softmax,这样可以得到每张图片的概率分布。
这里dim的意思是计算Softmax的维度,这里设置dim=1,可以看到每一行的加和为1。比如第一行0.6600+0.0570+0.2830=1。
如果设置dim=0,就是一列的和为0。比如第一列0.2212+0.3050+0.4738=1。
我们这里一张图片是一行,所以dim应该设置为1。
然后对Softmax的结果取自然对数:
Softmax后的数值都在0~1之间,所以ln之后值域是负无穷到0。
NLLLoss的结果就是把上面的输出与Label对应的那个值拿出来,再去掉负号,再求均值。
假设我们现在Target是[0,2,1](第一张图片是猫,第二张是猪,第三张是狗)。第一行取第0个元素,第二行取第2个,第三行取第1个,去掉负号,结果是:[0.4155,1.0945,1.5285]。再求个均值,结果是:
下面使用NLLLoss函数验证一下:
嘻嘻,果然是1.0128!
CrossEntropyLoss
CrossEntropyLoss就是把以上Softmax–Log–NLLLoss合并成一步,我们用刚刚随机出来的input直接验证一下结果是不是1.0128:
真的是1.0128哈哈哈哈!我也太厉害了吧!
如果你也觉得我很厉害,请奖励我0.01元,鼓励我做的更好,非常感谢!







这篇文章的优点就是非常的直观。nn.NLLLoss的定义如下:
来源:https://blog.csdn.net/zhangxb35/article/details/72464152
用于多分类的负对数似然损失函数(Negative Log Likelihood)
loss(x,label)=−xlabel
loss(x,label)=−xlabel
在前面接上一个 nn.LogSoftMax 层就等价于交叉熵损失了。事实上,nn.CrossEntropyLoss 也是调用这个函数。注意这里的 xlabelxlabel 和上个交叉熵损失里的不一样(虽然符号我给写一样了),这里是经过 logSoftMaxlogSoftMax 运算后的数值,
什么是交叉熵
来源:https://baike.baidu.com/item/%E4%BA%A4%E5%8F%89%E7%86%B5/8983241
交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。
对于离散变量采用以下的方式计算:H(p,q)=
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
在特征工程中,可以用来衡量两个随机变量之间的相似度。
在语言模型中(NLP)中,由于真实的分布p是未知的,在语言模型中,模型是通过训练集得到的,交叉熵就是衡量这个模型在测试集上的正确率。

由此可见,Pytorch上的CrossEntropyLoss和交叉熵的原本定义还是有差距的
更详细的看这里!
来源:https://blog.csdn.net/geter_CS/article/details/84857220


大家可以手算一下,LogSoftmax的式子再内部嵌套上NLLLoss的式子就是CrossEntropyLoss的公式