前面是一些选择题,不大记住了
简答题,第一题是正则表达式
第二题,什么是哈希查找,以及构造函数,遇到冲突了怎么处理
由于哈希表的查找高效性,在平时的算法中用的比较多。例如:字符串,单词个数的统计,只出现一次字符或者数字的统计,两个集合相同的元素查找等等,还有插入删除的高效(链地址发)都可以用哈希表来解决。缺点是需要占用额外的内存空间。


下面介绍五种常用的哈希构造方法: 构造哈希函数的原则是: (1)函数本身便于计算; (2)计算出来的地址分布均匀,即对任一关键字k,f(k) 对应不同地址的概率相等,目的是尽可能减少冲突。 1、除留余数法; 取关键字被某个不大于哈希表长m的数p除后所得的余数为哈希地址。即: H(key)=key MODE p,p<=m.(p的取值最好为素数)。 若冲突较多,可取较大的m和p值。 2、随机法; 采用一个伪随机函数做哈希函数,即: H(key)=random(key)。其中random为随机函数。 通常,当关键字长度不等时采用此法构造哈希函数较为恰当。 3、平方取中法; 当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。 这是因为:平方后中间几位和关键字中每一位都相关,故不同关键字会以较高的概率产生不同的哈希地址。 例如对于关键key:123。1234^2=1522756,H(k)关键字的哈希地址为:227. 4、折叠法; 这种方法是按哈希表地址位数将关键字分成位数相等的几部分(最后一部分可以较短),然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址。具体方法有折叠法与移位法。移位法是将分割后的每部分低位对齐相加,折叠法是从一端向另一端沿分割界来回折叠(奇数段为正序,偶数段为倒序),然后将各段相加。 例如:key=12360324711202065,哈希表长度为1000,则应把关键字分成3位一段,在此舍去最低的两位65,分别进行移位叠加和折叠叠加,求得哈希地址为105和907。具体过程如下: 5、直接定址法; 取关键字或关键字的某个线性函数值为哈希地址。即: H(key)=key 或 H(key)=a*key+b 其中a、b为常数(这种hash函数叫做自身函数)。 6、数字分析法; 如果事先知道关键字集合,并且每个关键字的位数比哈希表的地址码位数多时,可以从关键字中选出分布较均匀的若干位,构成哈希地址。 例如,有1000个记录,关键字为10位十进制整数d1d2d3…d7d8d9d10,如哈希表长取1200,则哈希表的地址空间为:000~1199。假设经过分析,各关键字中 d3、d5和d7的取值分布较均匀,则哈希函数为:h(key)=h(d1d2d3…d7d8d9d10)=d3d5d7。 例如,h(3748597089)=457,h(9846372561)=432。就是找数字中分布均匀的数字。
1、开放定址法,又称下标加1法 这种方法也称再散列法,其基本思想是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。这种方法有一个通用的再散列函数形式: Hi=(H(key)+di)% m i=1,2,…,n 其中H(key)为哈希函数,m 为表长,di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有以下三种: (1)线性探测再散列 (2)二次探测再散列 (3)伪随机探测再散列 缺点是:线性探测再散列容易产生“二次聚集”。当删除某个数据的时候,需要设置标记或者移动数据,否则会导致查找的中断。 2、再哈希法: 这种方法是同时构造多个不同的哈希函数: Hi=RH1(key) i=1,2,…,k 当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。 3、链地址法;需要额外的空间; 这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。 4、公共溢出区; 这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
链地址法(拉链法) 当存储结构是链表时,多采用拉链法,用拉链法处理冲突的办法是:把具有相同散列地址的关键字(同义词)值放在同一个单链表中,称为同义词链表。有m个散列地址就有m个链表,同时用指针数组T[0..m-1]存放各个链表的头指针,凡是散列地址为i的记录都以结点方式插入到以T[i]为指针的单链表中。T中各分量的初值应为空指针。 哈希表拉链法查找的具体实现代码: #include <iostream> using namespace std; #define MODLE 13 struct Haxi_Table { int data; char a; Haxi_Table *next; }; Haxi_Table *haxi_table[MODLE];//哈希表数组; void Create_Haxi(int arry[],int num) { for(int i=0;i<num;i++) { int index=arry[i]%MODLE; Haxi_Table *temp=new Haxi_Table; temp->a=i+97; temp->data=num; temp->next=NULL; if(!haxi_table[index]) { haxi_table[index]=temp; } else { temp->next=haxi_table[index]; haxi_table[index]=temp; } } } char FindValue(int value) { int index=value%MODLE; Haxi_Table *p=haxi_table[index]; while(p) { if(p->data=value) { return p->a; } else { p=p->next; } } return -1; } void DestoryHash() { Haxi_Table *temp=NULL; for(int i=0;i<MODLE;i++) { if(haxi_table[i]) { while(haxi_table[i]) { temp=haxi_table[i]; haxi_table[i]=haxi_table[i]->next; delete temp; } } } } int main() { int num; cout<<"please input the number of your data:"<<endl; cin>>num; int *array=new int[num]; cout<<"please input the "<<num<<" data:"<<endl; for(int i=0;i<num;i++) cin>>array[i]; Create_Haxi(array,num); cout<<"查找结果,8对应的字符为:"<<FindValue(8)<<endl; DestoryHash(); system("pause"); return 0; }
第三题,画图描述tcp/ip握手状态
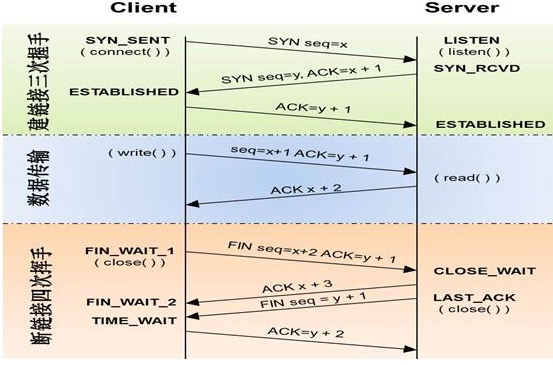
TCP是因特网中的传输层协议,使用三次握手协议建立连接。当主动方发出SYN连接请求后,等待对方回答SYN+ACK[1],并最终对对方的 SYN 执行 ACK 确认。这种建立连接的方法可以防止产生错误的连接。[1] TCP三次握手的过程如下: 客户端发送SYN(SEQ=x)报文给服务器端,进入SYN_SEND状态。 服务器端收到SYN报文,回应一个SYN (SEQ=y)ACK(ACK=x+1)报文,进入SYN_RECV状态。 客户端收到服务器端的SYN报文,回应一个ACK(ACK=y+1)报文,进入Established状态。 三次握手完成,TCP客户端和服务器端成功地建立连接,可以开始传输数据了。
建立一个连接需要三次握手,而终止一个连接要经过四次握手,这是由TCP的半关闭(half-close)造成的。 (1) 某个应用进程首先调用close,称该端执行“主动关闭”(active close)。该端的TCP于是发送一个FIN分节,表示数据发送完毕。 (2) 接收到这个FIN的对端执行 “被动关闭”(passive close),这个FIN由TCP确认。 注意:FIN的接收也作为一个文件结束符(end-of-file)传递给接收端应用进程,放在已排队等候该应用进程接收的任何其他数据之后,因为,FIN的接收意味着接收端应用进程在相应连接上再无额外数据可接收。 (3) 一段时间后,接收到这个文件结束符的应用进程将调用close关闭它的套接字。这导致它的TCP也发送一个FIN。 (4) 接收这个最终FIN的原发送端TCP(即执行主动关闭的那一端)确认这个FIN。[1] 既然每个方向都需要一个FIN和一个ACK,因此通常需要4个分节。 注意: (1) “通常”是指,某些情况下,步骤1的FIN随数据一起发送,另外,步骤2和步骤3发送的分节都出自执行被动关闭那一端,有可能被合并成一个分节。[2] (2) 在步骤2与步骤3之间,从执行被动关闭一端到执行主动关闭一端流动数据是可能的,这称为“半关闭”(half-close)。 (3) 当一个Unix进程无论自愿地(调用exit或从main函数返回)还是非自愿地(收到一个终止本进程的信号)终止时,所有打开的描述符都被关闭,这也导致仍然打开的任何TCP连接上也发出一个FIN。 无论是客户还是服务器,任何一端都可以执行主动关闭。通常情况是,客户执行主动关闭,但是某些协议,例如,HTTP/1.0却由服务器执行主动关闭。[2]
第四题,http和https的区别,https的握手状态
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。
简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
SSL四次握手过程,如下图所示:
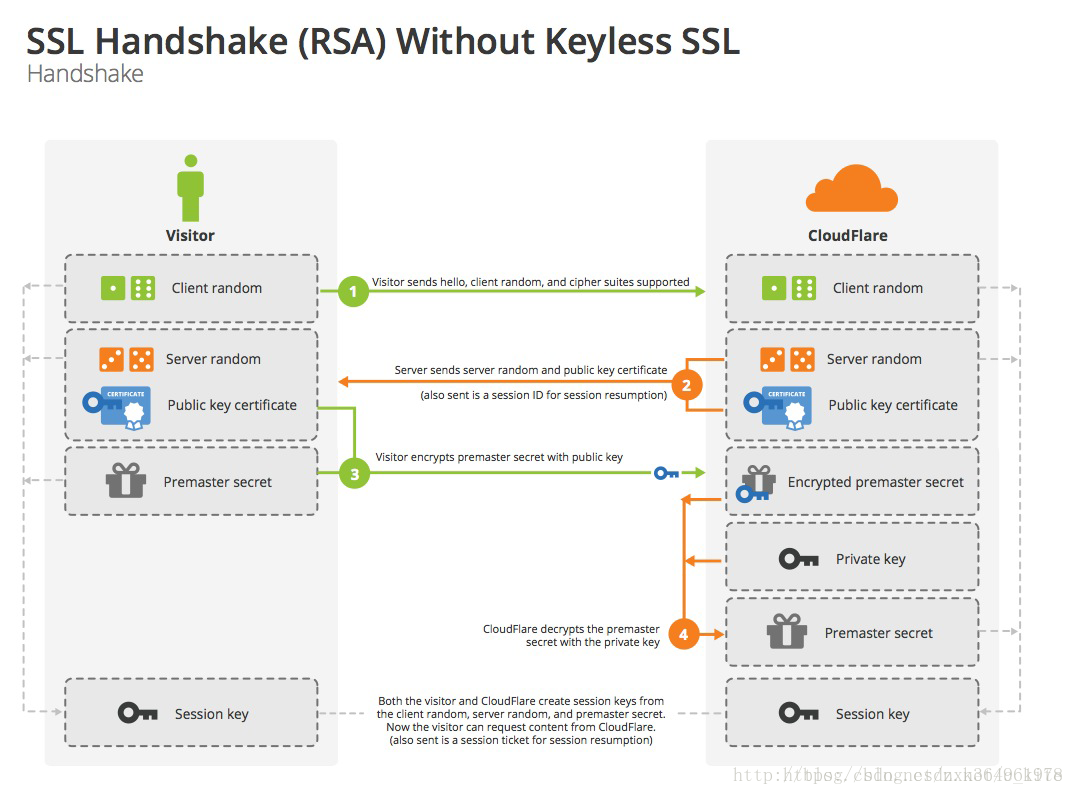
1.客户端请求建立SSL链接,并向服务端发送一个随机数–Client random和客户端支持的加密方法,比如RSA公钥加密,此时是明文传输。 2.服务端回复一种客户端支持的加密方法、一个随机数–Server random、授信的服务器证书和非对称加密的公钥。 3.客户端收到服务端的回复后利用服务端的公钥,加上新的随机数–Premaster secret 通过服务端下发的公钥及加密方法进行加密,发送给服务器。 4.服务端收到客户端的回复,利用已知的加解密方式进行解密,同时利用Client random、Server random和Premaster secret通过一定的算法生成HTTP链接数据传输的对称加密key – session key。 此后的HTTP链接数据传输即通过对称加密方式进行加密传输。
1.https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。 2.http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。 3.http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。 4.http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
https的工作原理

我们都知道HTTPS能够加密信息,以免敏感信息被第三方获取,所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议 1.客户端发起HTTPS请求 这个没什么好说的,就是用户在浏览器里输入一个https网址,然后连接到server的443端口。 2.服务端的配置 采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请,区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面(startssl就是个不错的选择,有1年的免费服务)。 这套证书其实就是一对公钥和私钥,如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。 3.传送证书 这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。 4.客户端解析证书 这部分工作是有客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。 如果证书没有问题,那么就生成一个随机值,然后用证书对该随机值进行加密,就好像上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。 5.传送加密信息 这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。 6.服务段解密信息 服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密,所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。 7.传输加密后的信息 这部分信息是服务段用私钥加密后的信息,可以在客户端被还原。 8.客户端解密信息 客户端用之前生成的私钥解密服务段传过来的信息,于是获取了解密后的内容,整个过程第三方即使监听到了数据,也束手无策。
参考链接:
http://www.mahaixiang.cn/internet/1233.html
http://www.ruanyifeng.com/blog/2014/02/ssl_tls.html
http://www.ruanyifeng.com/blog/2014/09/illustration-ssl.html
https://blog.csdn.net/zxk364961978/article/details/54809008
算法题1,链表反转,
算法题2,二叉树反转,