#include<bits/stdc++.h> using namespace std; const int N=1e5+10; string a,b; int main() { cin>>a>>b; if(a.size()!=b.size()) { cout<<max(a.size(),b.size())<<endl; } else if(a==b) printf("-1 "); else cout<<a.size()<<endl; return 0; }
#include<bits/stdc++.h> using namespace std; const int N=1e5+10; int a[N]; int main() { int n; scanf("%d",&n); for(int i=1;i<=n;i++) scanf("%d",&a[i]); sort(a+1,a+1+n); for(int i=1;i<=n-2;i++) { if(a[i]+a[i+1]>a[i+2]) return puts("YES"); } puts("NO"); return 0; }
Mahmoud wrote a message s of length n. He wants to send it as a birthday present to his friend Moaz who likes strings. He wrote it on a magical paper but he was surprised because some characters disappeared while writing the string. That's because this magical paper doesn't allow character number i in the English alphabet to be written on it in a string of length more than ai. For example, if a1 = 2 he can't write character 'a' on this paper in a string of length 3 or more. String "aa" is allowed while string "aaa" is not.
Mahmoud decided to split the message into some non-empty substrings so that he can write every substring on an independent magical paper and fulfill the condition. The sum of their lengths should be n and they shouldn't overlap. For example, if a1 = 2 and he wants to send string "aaa", he can split it into "a" and "aa" and use 2 magical papers, or into "a", "a" and "a" and use 3 magical papers. He can't split it into "aa" and "aa" because the sum of their lengths is greater than n. He can split the message into single string if it fulfills the conditions.
A substring of string s is a string that consists of some consecutive characters from string s, strings "ab", "abc" and "b" are substrings of string "abc", while strings "acb" and "ac" are not. Any string is a substring of itself.
While Mahmoud was thinking of how to split the message, Ehab told him that there are many ways to split it. After that Mahmoud asked you three questions:
- How many ways are there to split the string into substrings such that every substring fulfills the condition of the magical paper, the sum of their lengths is n and they don't overlap? Compute the answer modulo 109 + 7.
- What is the maximum length of a substring that can appear in some valid splitting?
- What is the minimum number of substrings the message can be spit in?
Two ways are considered different, if the sets of split positions differ. For example, splitting "aa|a" and "a|aa" are considered different splittings of message "aaa".
The first line contains an integer n (1 ≤ n ≤ 103) denoting the length of the message.
The second line contains the message s of length n that consists of lowercase English letters.
The third line contains 26 integers a1, a2, ..., a26 (1 ≤ ax ≤ 103) — the maximum lengths of substring each letter can appear in.
Print three lines.
In the first line print the number of ways to split the message into substrings and fulfill the conditions mentioned in the problem modulo109 + 7.
In the second line print the length of the longest substring over all the ways.
In the third line print the minimum number of substrings over all the ways.
3
aab
2 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
3
2
2
10
abcdeabcde
5 5 5 5 4 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
401
4
3
In the first example the three ways to split the message are:
- a|a|b
- aa|b
- a|ab
The longest substrings are "aa" and "ab" of length 2.
The minimum number of substrings is 2 in "a|ab" or "aa|b".
Notice that "aab" is not a possible splitting because the letter 'a' appears in a substring of length 3, while a1 = 2.
#include<bits/stdc++.h> using namespace std; #define ll long long #define pi (4*atan(1.0)) #define eps 1e-14 #define bug(x,y) cout<<"bug"<<x<<" "<<y<<endl; const int N=1e3+10,M=1e6+10,inf=1e8+10,mod=1e9+7; const ll INF=1e18+10; char a[N]; int s[N]; int dp[2][N]; void solve1(int n) { int ans2=1; dp[0][0]=1; for(int i=1;i<=n;i++) dp[1][i]=inf; for(int i=1;i<=n;i++) { int st=max(0,i-s[a[i]-'a'+1]+1); for(int j=i;j>=1;j--) { st=max(st,i-s[a[j]-'a'+1]+1); if(st>j)break; ans2=max(ans2,i-j+1); dp[0][i]=(dp[0][i]+dp[0][j-1])%mod; dp[1][i]=min(dp[1][i],dp[1][j-1]+1); } //cout<<dp[1][i]<<" xxx"<<endl; } printf("%d %d %d ",dp[0][n],ans2,dp[1][n]); } int main() { int n; scanf("%d",&n); scanf("%s",a+1); for(int i=1;i<=26;i++) scanf("%d",&s[i]); solve1(n); return 0; }
题意:n个单词,1表示两个单词同义,2表示反义;
思路:再开一倍的点,表示那个单词的反义,并查集一下;
#pragma comment(linker, "/STACK:1024000000,1024000000") #include<iostream> #include<cstdio> #include<cmath> #include<string> #include<queue> #include<algorithm> #include<stack> #include<cstring> #include<vector> #include<list> #include<set> #include<map> using namespace std; #define ll long long #define pi (4*atan(1.0)) #define eps 1e-14 #define bug(x) cout<<"bug"<<x<<endl; const int N=2e5+10,M=1e6+10; const ll INF=1e18+10,mod=2147493647; int si; int fa[N]; map<string,int>mp; int Find(int x) { return x==fa[x]?x:fa[x]=Find(fa[x]); } int update(int u,int v) { int x=Find(u); int y=Find(v); if(x!=y) { fa[x]=y; return 0; } else return 1; } int main() { int n,m,q; scanf("%d%d%d",&n,&m,&q); for(int i=1; i<=2*n; i++) fa[i]=i; for(int i=1; i<=n; i++) { string a; cin>>a; mp[a]=i; } for(int i=1; i<=m; i++) { int flag; scanf("%d",&flag); string a,b; cin>>a>>b; int u=mp[a]; int v=mp[b]; int x=Find(u); int y=Find(v); int h=Find(u+n); if(flag==1) { if(y==h) puts("NO"); else { update(u,v); update(u+n,v+n); puts("YES"); } } else { if(x==y) puts("NO"); else { update(u+n,v); update(u,v+n); puts("YES"); } } } while(q--) { string a,b; cin>>a>>b; int x=Find(mp[a]); int y=Find(mp[b]); int h=Find(mp[a]+n); if(x==y) puts("1"); else if(y==h) puts("2"); else puts("3"); } return 0; }
Mahmoud and Ehab live in a country with n cities numbered from 1 to n and connected by n - 1 undirected roads. It's guaranteed that you can reach any city from any other using these roads. Each city has a number ai attached to it.
We define the distance from city x to city y as the xor of numbers attached to the cities on the path from x to y (including both x andy). In other words if values attached to the cities on the path from x to y form an array p of length l then the distance between them is  , where
, where  is bitwise xor operation.
is bitwise xor operation.
Mahmoud and Ehab want to choose two cities and make a journey from one to another. The index of the start city is always less than or equal to the index of the finish city (they may start and finish in the same city and in this case the distance equals the number attached to that city). They can't determine the two cities so they try every city as a start and every city with greater index as a finish. They want to know the total distance between all pairs of cities.
The first line contains integer n (1 ≤ n ≤ 105) — the number of cities in Mahmoud and Ehab's country.
Then the second line contains n integers a1, a2, ..., an (0 ≤ ai ≤ 106) which represent the numbers attached to the cities. Integer ai is attached to the city i.
Each of the next n - 1 lines contains two integers u and v (1 ≤ u, v ≤ n, u ≠ v), denoting that there is an undirected road between cities u and v. It's guaranteed that you can reach any city from any other using these roads.
Output one number denoting the total distance between all pairs of cities.
3
1 2 3
1 2
2 3
10
5
1 2 3 4 5
1 2
2 3
3 4
3 5
52
5
10 9 8 7 6
1 2
2 3
3 4
3 5
131
A bitwise xor takes two bit integers of equal length and performs the logical xor operation on each pair of corresponding bits. The result in each position is 1 if only the first bit is 1 or only the second bit is 1, but will be 0 if both are 0 or both are 1. You can read more about bitwise xor operation here: https://en.wikipedia.org/wiki/Bitwise_operation#XOR.
In the first sample the available paths are:
- city 1 to itself with a distance of 1,
- city 2 to itself with a distance of 2,
- city 3 to itself with a distance of 3,
- city 1 to city 2 with a distance of
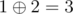 ,
, - city 1 to city 3 with a distance of
 ,
, - city 2 to city 3 with a distance of
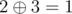 .
.
#pragma comment(linker, "/STACK:1024000000,1024000000") #include<iostream> #include<cstdio> #include<cmath> #include<string> #include<queue> #include<algorithm> #include<stack> #include<cstring> #include<vector> #include<list> #include<set> #include<map> using namespace std; #define ll long long #define pi (4*atan(1.0)) #define eps 1e-14 #define bug(x) cout<<"bug"<<x<<endl; const int N=2e5+10,M=1e6+10; const ll INF=1e18+10,mod=2147493647; struct is { int v,next; }edge[N<<1]; int head[N],edg,n; int a[N]; ll num[N][30][3]; ll ans,sum; void init() { memset(head,-1,sizeof(head)); edg=0; } void add(int u,int v) { edg++; edge[edg].v=v; edge[edg].next=head[u]; head[u]=edg; } void dfs(int u,int fa,int x) { int q=(a[u]&(1<<x))?1:0; num[u][x][q]++; ll flag0=0,flag1=0; for(int i=head[u];i!=-1;i=edge[i].next) { int v=edge[i].v; if(v==fa)continue; dfs(v,u,x); num[u][x][1]+=num[v][x][q^1]; num[u][x][0]+=num[v][x][q^0]; flag0+=num[v][x][0]; flag1+=num[v][x][1]; } for(int i=head[u];i!=-1;i=edge[i].next) { int v=edge[i].v; if(v==fa)continue; if(q) { ans+=num[v][x][0]*(flag0-num[v][x][0])*(1LL<<x); ans+=num[v][x][1]*(flag1-num[v][x][1])*(1LL<<x); } else { ans+=num[v][x][0]*(flag1-num[v][x][1])*(1LL<<x); ans+=num[v][x][1]*(flag0-num[v][x][0])*(1LL<<x); } sum+=num[v][x][q^1]*(1LL<<x); } } int main() { init(); scanf("%d",&n); for(int i=1;i<=n;i++) scanf("%d",&a[i]),sum+=a[i]; for(int i=1;i<n;i++) { int u,v; scanf("%d%d",&u,&v); add(u,v); add(v,u); } for(int i=0;i<23;i++) dfs(1,-1,i); /*for(int i=1;i<=n;i++) { printf("%lld %lld ",num[i][0][0],num[i][0][1]); printf("%lld %lld ",num[i][1][0],num[i][1][1]); }*/ printf("%lld ",ans/2+sum); return 0; }